 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMosaicQuant: Inlier-Outlier Disaggregation for Unified 4-Bit LLM Quantization
Jun 14, 20264-bit quantization significantly reduces the memory footprint and accelerates the inference of large language models (LLMs). However, its limited bit-width representation struggles to faithfully capture both dense common values (\emph{inliers}) and rare large-magnitude values (\emph{outliers}), causing substantial accuracy degradation. Existing mixed-precision methods mitigate this by retaining outliers in high precision, but at the cost of breaking the uniformity of low-bit execution, introducing precision conversion and extra data movement that undermine practical speedup. We propose \textbf{MosaicQuant}, a unified 4-bit LLM quantization paradigm built on a novel principle of \emph{inlier--outlier disaggregation}. Rather than elevating outlier precision, MosaicQuant quantizes the full weight matrix into a dense 4-bit base component, where inliers are captured faithfully while outlier are inevitably quantized. A sparse 4-bit residual component is then introduced to compensate for these quantization errors, selectively targeting the most error-critical weight blocks where output distortion is shown to be concentrated. However, a unified representation alone is insufficient, as naïvely executing the sparse residual as a separate kernel still breaks the unified low-bit inference pipeline. To bridge this gap, we introduce \textbf{ZipperEngine}, which fuses sparse block computation into the dense 4-bit GEMM kernel via an overlapped pipeline, unifying not only the representation but also the execution into a single coherent low-bit inference pipeline. Extensive experiments on LLaMA3 and Qwen3 demonstrate that MosaicQuant preserves near-FP16 accuracy while achieving up to $1.24\times$ speedup over the W16A16 baseline.
CAN: Constrained Attention Networks for Multi-Aspect Sentiment Analysis
Dec 27, 2018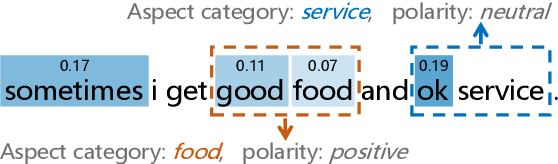
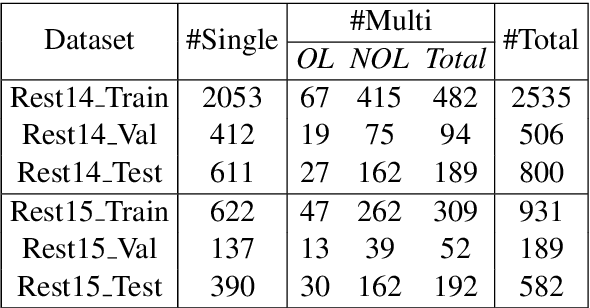
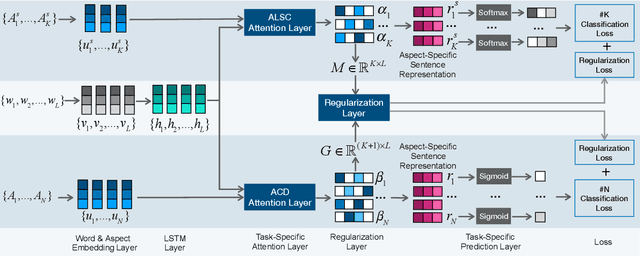
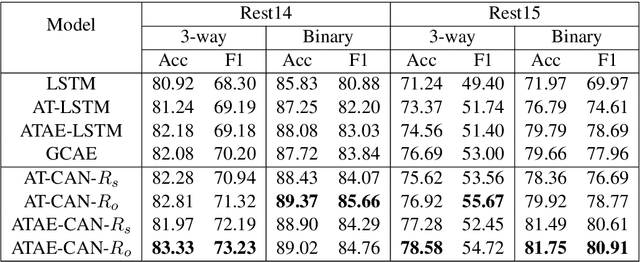
Aspect level sentiment classification is a fine-grained sentiment analysis task, compared to the sentence level classification. A sentence usually contains one or more aspects. To detect the sentiment towards a particular aspect in a sentence, previous studies have developed various methods for generating aspect-specific sentence representations. However, these studies handle each aspect of a sentence separately. In this paper, we argue that multiple aspects of a sentence are usually orthogonal based on the observation that different aspects concentrate on different parts of the sentence. To force the orthogonality among aspects, we propose constrained attention networks (CAN) for multi-aspect sentiment analysis, which handles multiple aspects of a sentence simultaneously. Experimental results on two public datasets demonstrate the effectiveness of our approach. We also extend our approach to multi-task settings, outperforming the state-of-the-arts significantly.