 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceVerse: a Fine-grained and Detail-controllable 3D Face Morphable Model from a Hybrid Dataset
Mar 29, 2022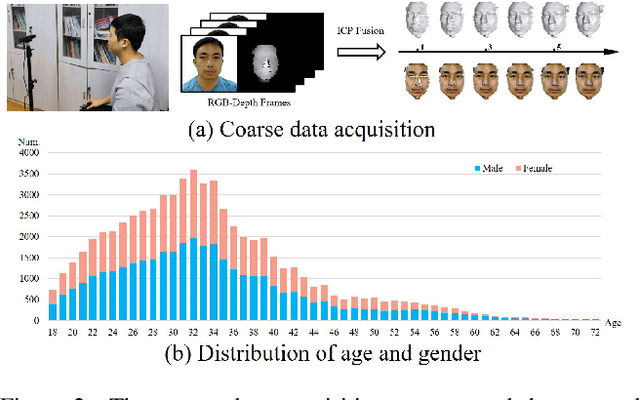
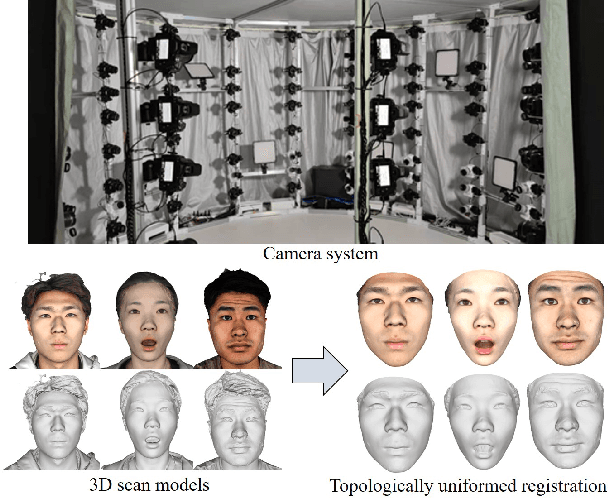
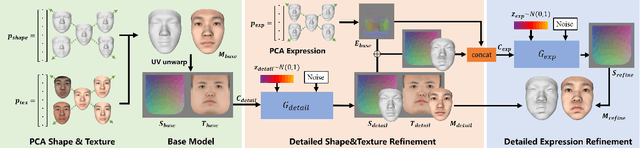
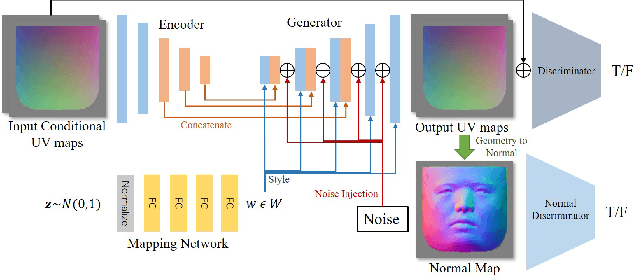
We present FaceVerse, a fine-grained 3D Neural Face Model, which is built from hybrid East Asian face datasets containing 60K fused RGB-D images and 2K high-fidelity 3D head scan models. A novel coarse-to-fine structure is proposed to take better advantage of our hybrid dataset. In the coarse module, we generate a base parametric model from large-scale RGB-D images, which is able to predict accurate rough 3D face models in different genders, ages, etc. Then in the fine module, a conditional StyleGAN architecture trained with high-fidelity scan models is introduced to enrich elaborate facial geometric and texture details. Note that different from previous methods, our base and detailed modules are both changeable, which enables an innovative application of adjusting both the basic attributes and the facial details of 3D face models. Furthermore, we propose a single-image fitting framework based on differentiable rendering. Rich experiments show that our method outperforms the state-of-the-art methods.
Intent Matching based Customer Services Chatbot with Natural Language Understanding
Jan 07, 2022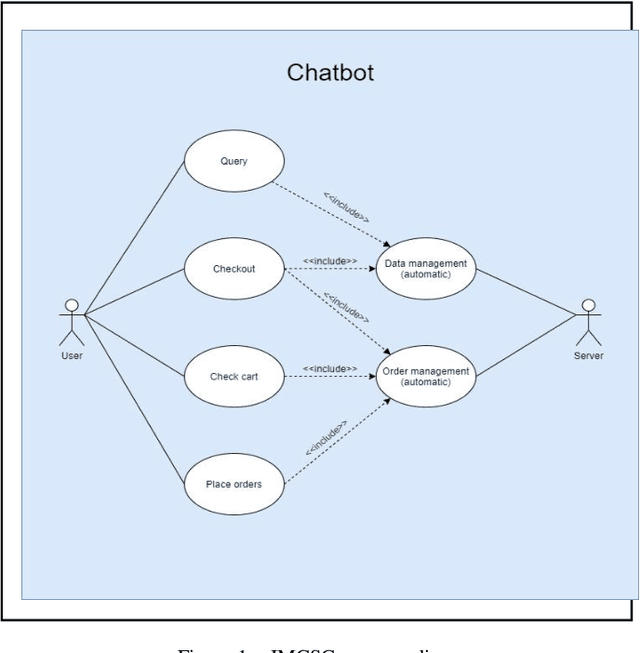
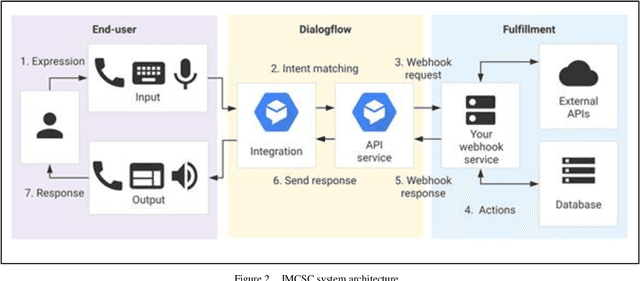
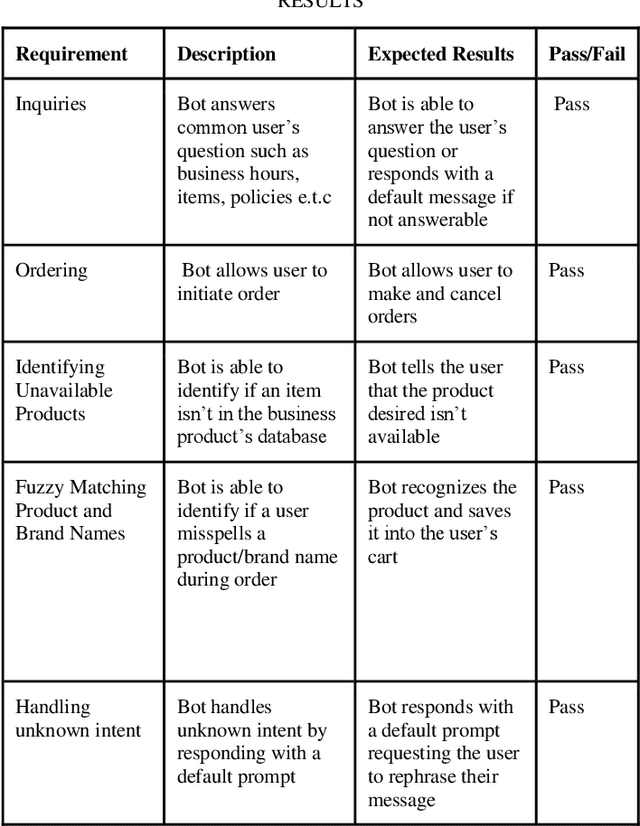
Customer service is the lifeblood of any business. Excellent customer service not only generates return business but also creates new customers. Looking at the demanding market to provide a 24/7 service to customers, many organisations are increasingly engaged in popular social media and text messaging platforms such as WhatsApp and Facebook Messenger in providing a 24/7 service to customers in the current demanding market. In this paper, we present an intent matching based customer services chatbot (IMCSC), which is capable of replacing the customer service work of sales personnel, whilst interacting in a more natural and human-like manner through the employment of Natural Language Understanding (NLU). The bot is able to answer the most common frequently asked questions and we have also integrated features for the processing and exporting of customer orders to a Google Sheet.
CELLS: Cost-Effective Evolution in Latent Space for Goal-Directed Molecular Generation
Dec 05, 2021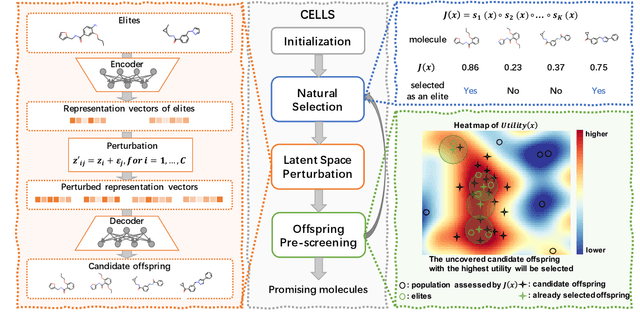
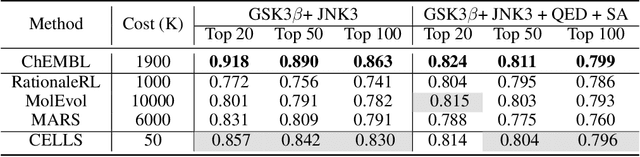
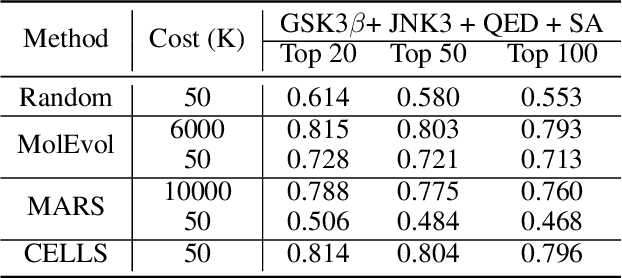
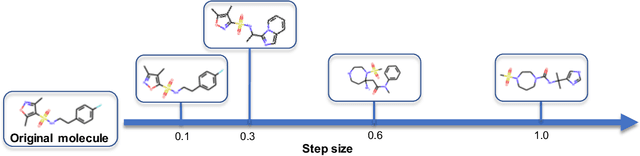
Efficiently discovering molecules that meet various property requirements can significantly benefit the drug discovery industry. Since it is infeasible to search over the entire chemical space, recent works adopt generative models for goal-directed molecular generation. They tend to utilize the iterative processes, optimizing the parameters of the molecular generative models at each iteration to produce promising molecules for further validation. Assessments are exploited to evaluate the generated molecules at each iteration, providing direction for model optimization. However, most previous works require a massive number of expensive and time-consuming assessments, e.g., wet experiments and molecular dynamic simulations, leading to the lack of practicability. To reduce the assessments in the iterative process, we propose a cost-effective evolution strategy in latent space, which optimizes the molecular latent representation vectors instead. We adopt a pre-trained molecular generative model to map the latent and observation spaces, taking advantage of the large-scale unlabeled molecules to learn chemical knowledge. To further reduce the number of expensive assessments, we introduce a pre-screener as the proxy to the assessments. We conduct extensive experiments on multiple optimization tasks comparing the proposed framework to several advanced techniques, showing that the proposed framework achieves better performance with fewer assessments.
GenURL: A General Framework for Unsupervised Representation Learning
Oct 27, 2021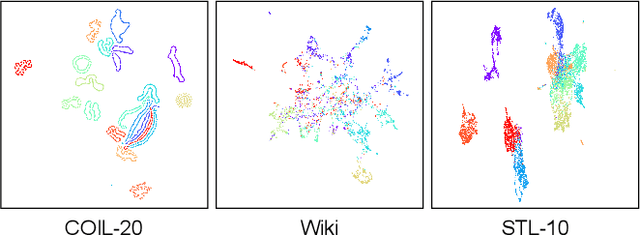
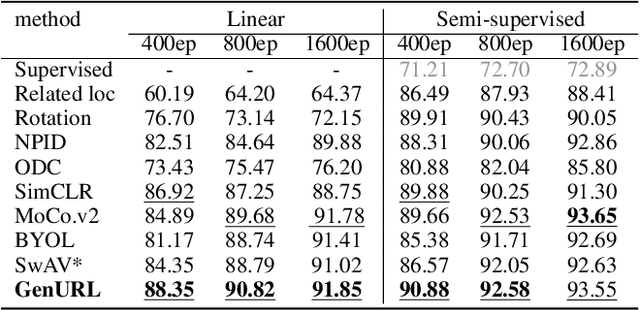
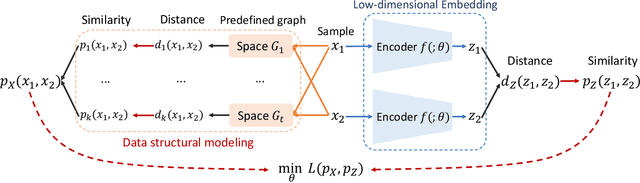
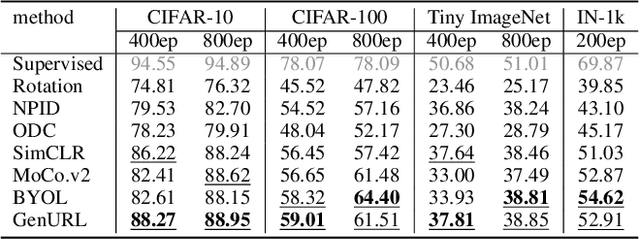
Recently unsupervised representation learning (URL) has achieved remarkable progress in various scenarios. However, most methods are specifically designed based on specific data characters or task assumptions. Based on the manifold assumption, we regard most URL problems as an embedding problem that seeks an optimal low-dimensional representation of the given high-dimensional data. We split the embedding process into two steps, data structural modeling and low-dimensional embedding, and propose a general similarity-based framework called GenURL. Specifically, we provide a general method to model data structures by adaptively combining graph distances on the feature space and predefined graphs, then propose robust loss functions to learn the low-dimensional embedding. Combining with a specific pretext task, we can adapt GenURL to various URL tasks in a unified manner and achieve state-of-the-art performance, including self-supervised visual representation learning, unsupervised knowledge distillation, graph embeddings, and dimension reduction. Moreover, ablation studies of loss functions and basic hyper-parameter settings in GenURL illustrate the data characters of various tasks.
Video Person Re-identification using Attribute-enhanced Features
Aug 16, 2021
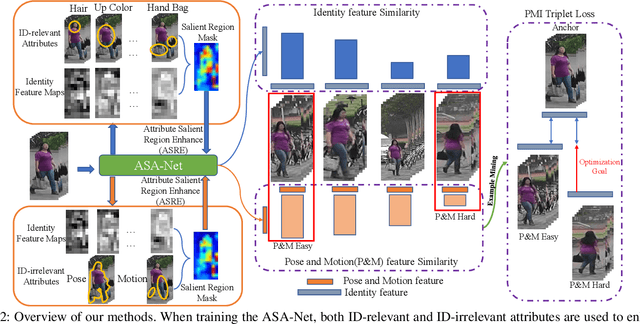

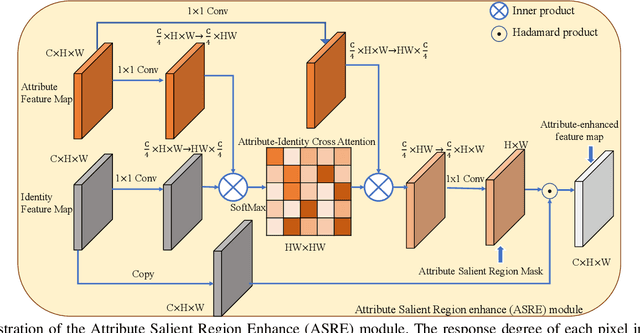
Video-based person re-identification (Re-ID) which aims to associate people across non-overlapping cameras using surveillance video is a challenging task. Pedestrian attribute, such as gender, age and clothing characteristics contains rich and supplementary information but is less explored in video person Re-ID. In this work, we propose a novel network architecture named Attribute Salience Assisted Network (ASA-Net) for attribute-assisted video person Re-ID, which achieved considerable improvement to existing works by two methods.First, to learn a better separation of the target from background, we propose to learn the visual attention from middle-level attribute instead of high-level identities. The proposed Attribute Salient Region Enhance (ASRE) module can attend more accurately on the body of pedestrian. Second, we found that many identity-irrelevant but object or subject-relevant factors like the view angle and movement of the target pedestrian can greatly influence the two dimensional appearance of a pedestrian. This problem can be mitigated by investigating both identity-relevant and identity-irrelevant attributes via a novel triplet loss which is referred as the Pose~\&~Motion-Invariant (PMI) triplet loss.
Automated Agriculture Commodity Price Prediction System with Machine Learning Techniques
Jun 24, 2021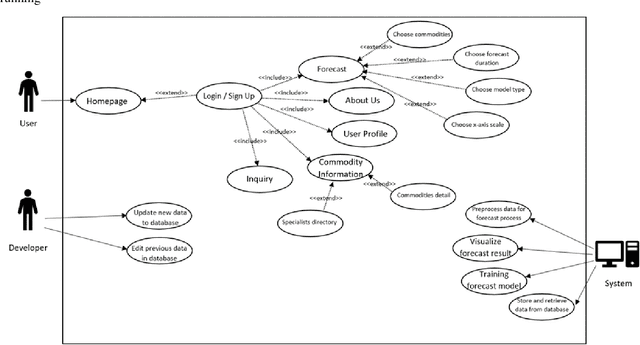
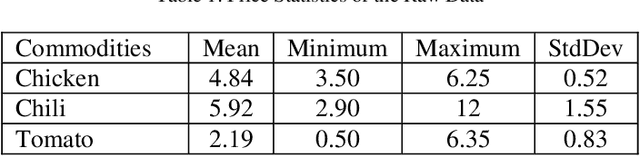
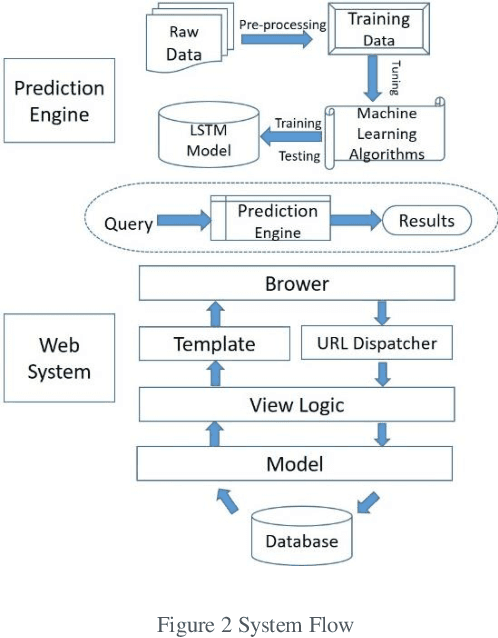
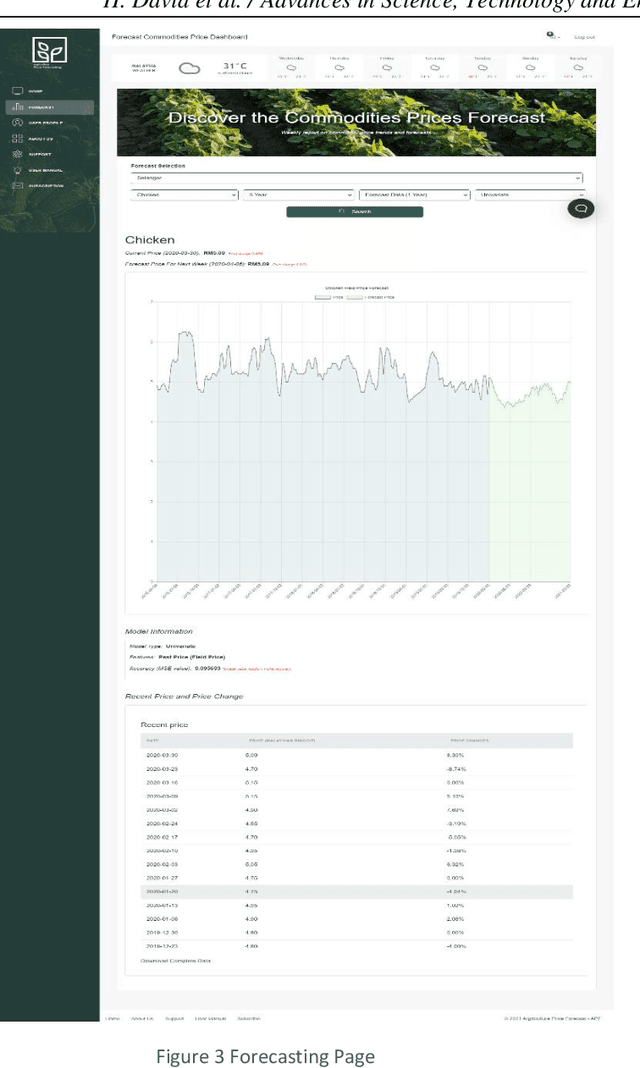
The intention of this research is to study and design an automated agriculture commodity price prediction system with novel machine learning techniques. Due to the increasing large amounts historical data of agricultural commodity prices and the need of performing accurate prediction of price fluctuations, the solution has largely shifted from statistical methods to machine learning area. However, the selection of proper set from historical data for forecasting still has limited consideration. On the other hand, when implementing machine learning techniques, finding a suitable model with optimal parameters for global solution, nonlinearity and avoiding curse of dimensionality are still biggest challenges, therefore machine learning strategies study are needed. In this research, we propose a web-based automated system to predict agriculture commodity price. In the two series experiments, five popular machine learning algorithms, ARIMA, SVR, Prophet, XGBoost and LSTM have been compared with large historical datasets in Malaysia and the most optimal algorithm, LSTM model with an average of 0.304 mean-square error has been selected as the prediction engine of the proposed system.
An Automated Knowledge Mining and Document Classification System with Multi-model Transfer Learning
Jun 24, 2021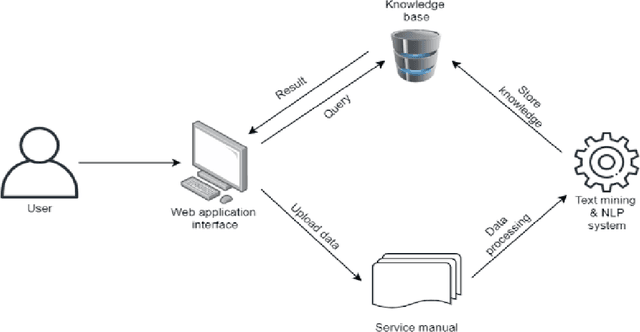
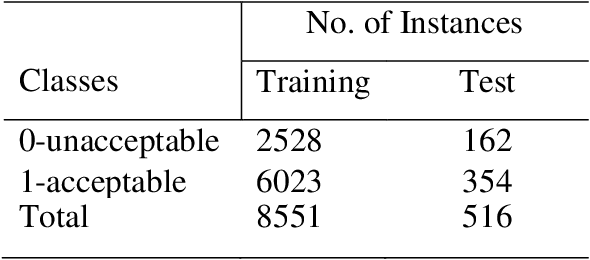
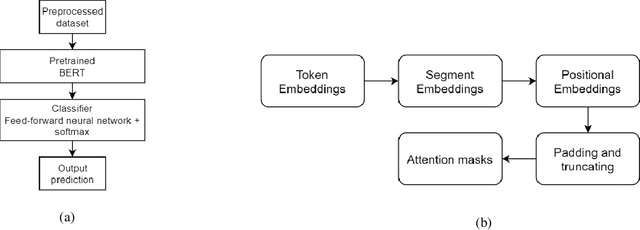
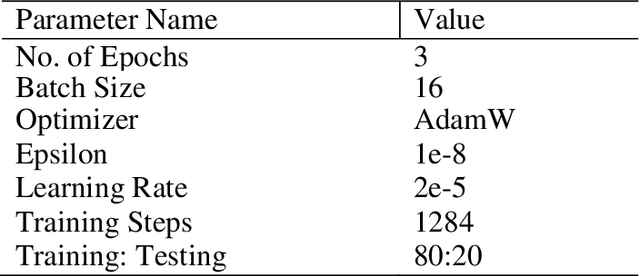
Service manual documents are crucial to the engineering company as they provide guidelines and knowledge to service engineers. However, it has become inconvenient and inefficient for service engineers to retrieve specific knowledge from documents due to the complexity of resources. In this research, we propose an automated knowledge mining and document classification system with novel multi-model transfer learning approaches. Particularly, the classification performance of the system has been improved with three effective techniques: fine-tuning, pruning, and multi-model method. The fine-tuning technique optimizes a pre-trained BERT model by adding a feed-forward neural network layer and the pruning technique is used to retrain the BERT model with new data. The multi-model method initializes and trains multiple BERT models to overcome the randomness of data ordering during the fine-tuning process. In the first iteration of the training process, multiple BERT models are being trained simultaneously. The best model is then selected for the next phase of the training process with another two iterations and the training processes for other BERT models will be terminated. The performance of the proposed system has been evaluated by comparing with two robust baseline methods, BERT and BERT-CNN. Experimental results on a widely used Corpus of Linguistic Acceptability (CoLA) dataset have shown that the proposed techniques perform better than these baseline methods in terms of accuracy and MCC score.
IDEAL: Independent Domain Embedding Augmentation Learning
May 21, 2021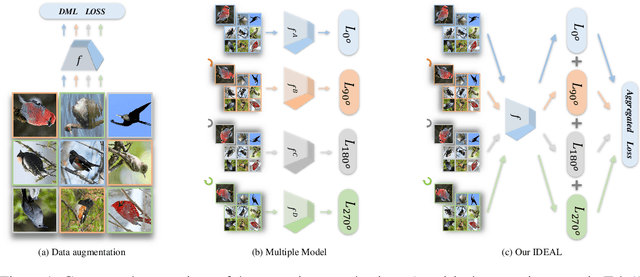

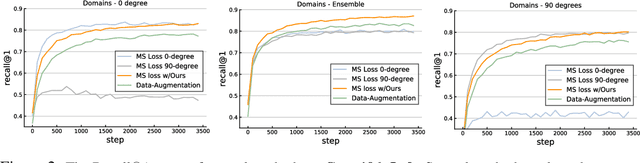

Many efforts have been devoted to designing sampling, mining, and weighting strategies in high-level deep metric learning (DML) loss objectives. However, little attention has been paid to low-level but essential data transformation. In this paper, we develop a novel mechanism, the independent domain embedding augmentation learning ({IDEAL}) method. It can simultaneously learn multiple independent embedding spaces for multiple domains generated by predefined data transformations. Our IDEAL is orthogonal to existing DML techniques and can be seamlessly combined with prior DML approaches for enhanced performance. Empirical results on visual retrieval tasks demonstrate the superiority of the proposed method. For example, the IDEAL improves the performance of MS loss by a large margin, 84.5\% $\rightarrow$ 87.1\% on Cars-196, and 65.8\% $\rightarrow$ 69.5\% on CUB-200 at Recall$@1$. Our IDEAL with MS loss also achieves the new state-of-the-art performance on three image retrieval benchmarks, \ie, \emph{Cars-196}, \emph{CUB-200}, and \emph{SOP}. It outperforms the most recent DML approaches, such as Circle loss and XBM, significantly. The source code and pre-trained models of our method will be available at\emph{\url{https://github.com/emdata-ailab/IDEAL}}.
AutoMix: Unveiling the Power of Mixup
Mar 24, 2021
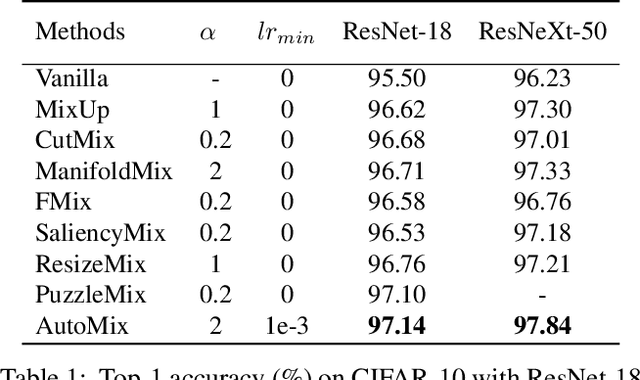
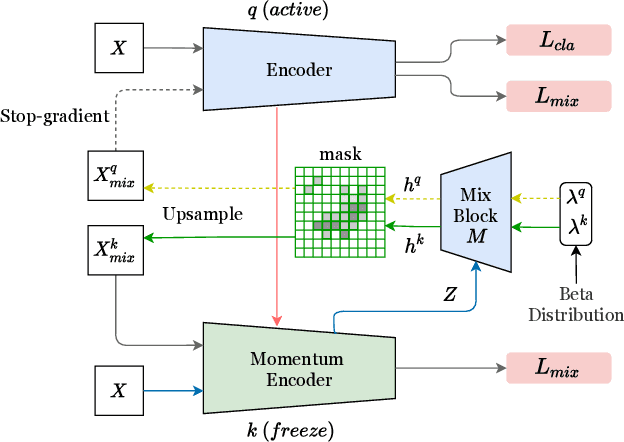
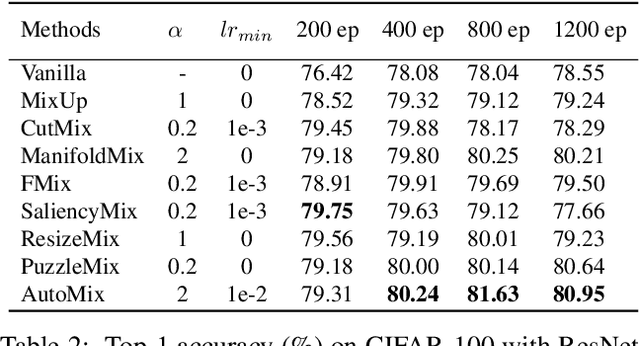
Mixup-based data augmentation has achieved great success as regularizer for deep neural networks. However, existing mixup methods require explicitly designed mixup policies. In this paper, we present a flexible, general Automatic Mixup (AutoMix) framework which utilizes discriminative features to learn a sample mixing policy adaptively. We regard mixup as a pretext task and split it into two sub-problems: mixed samples generation and mixup classification. To this end, we design a lightweight mix block to generate synthetic samples based on feature maps and mix labels. Since the two sub-problems are in the nature of Expectation-Maximization (EM), we also propose a momentum training pipeline to optimize the mixup process and mixup classification process alternatively in an end-to-end fashion. Extensive experiments on six popular classification benchmarks show that AutoMix consistently outperforms other leading mixup methods and improves generalization abilities to downstream tasks. We hope AutoMix will motivate the community to rethink the role of mixup in representation learning. The code will be released soon.
Reformulating HOI Detection as Adaptive Set Prediction
Mar 10, 2021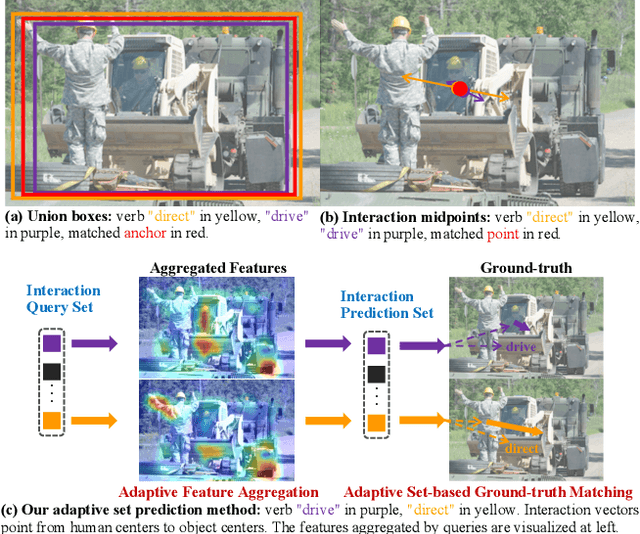
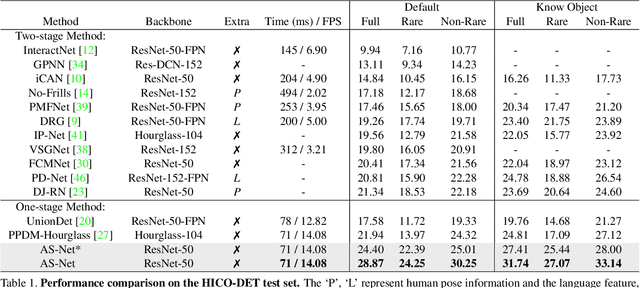
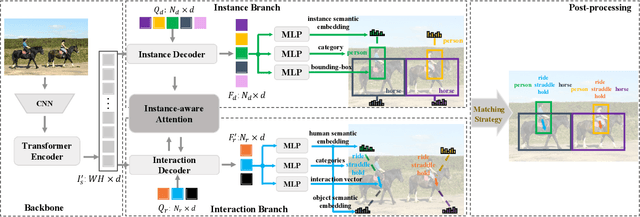
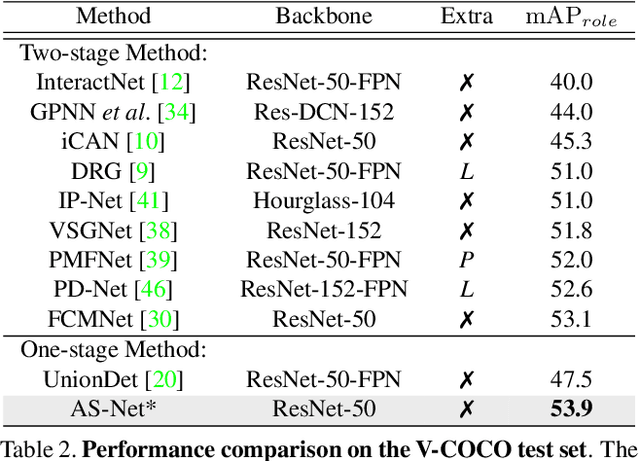
Determining which image regions to concentrate on is critical for Human-Object Interaction (HOI) detection. Conventional HOI detectors focus on either detected human and object pairs or pre-defined interaction locations, which limits learning of the effective features. In this paper, we reformulate HOI detection as an adaptive set prediction problem, with this novel formulation, we propose an Adaptive Set-based one-stage framework (AS-Net) with parallel instance and interaction branches. To attain this, we map a trainable interaction query set to an interaction prediction set with a transformer. Each query adaptively aggregates the interaction-relevant features from global contexts through multi-head co-attention. Besides, the training process is supervised adaptively by matching each ground-truth with the interaction prediction. Furthermore, we design an effective instance-aware attention module to introduce instructive features from the instance branch into the interaction branch. Our method outperforms previous state-of-the-art methods without any extra human pose and language features on three challenging HOI detection datasets. Especially, we achieve over $31\%$ relative improvement on a large scale HICO-DET dataset. Code is available at https://github.com/yoyomimi/AS-Net.