 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning across Meta-Tasks for Few-Shot Learning
Mar 09, 2020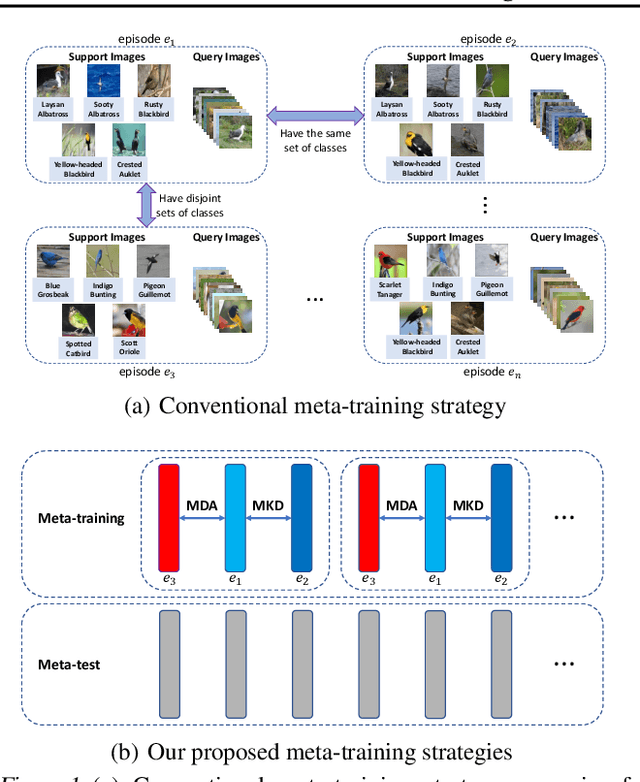
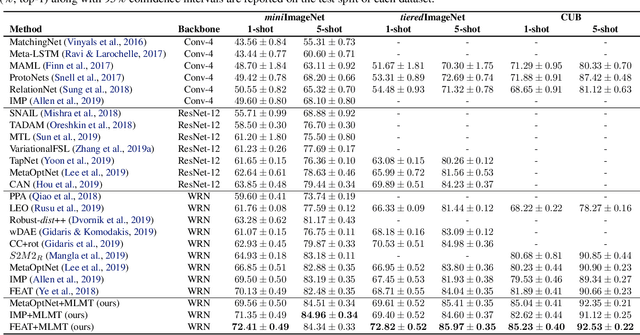
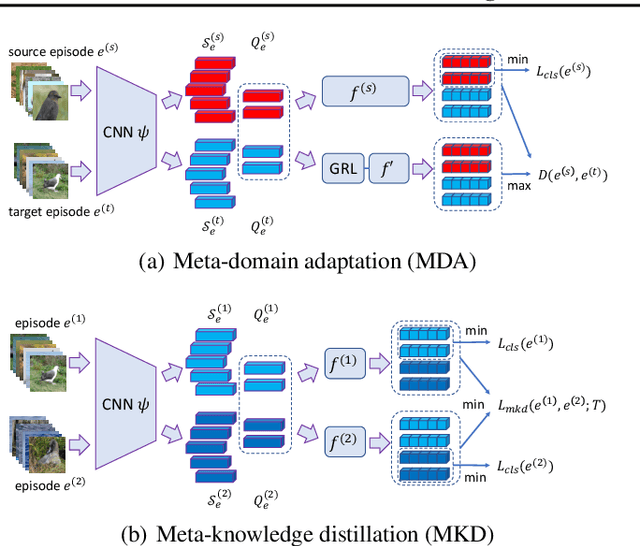
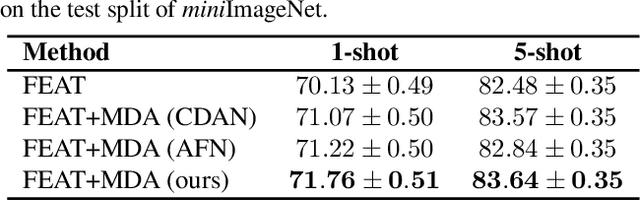
Existing meta-learning based few-shot learning (FSL) methods typically adopt an episodic training strategy whereby each episode contains a meta-task. Across episodes, these tasks are sampled randomly and their relationships are ignored. In this paper, we argue that the inter-meta-task relationships should be exploited and those tasks are sampled strategically to assist in meta-learning. Specifically, we consider the relationships defined over two types of meta-task pairs and propose different strategies to exploit them. (1) Two meta-tasks with disjoint sets of classes: this pair is interesting because it is reminiscent of the relationship between the source seen classes and target unseen classes, featured with domain gap caused by class differences. A novel learning objective termed meta-domain adaptation (MDA) is proposed to make the meta-learned model more robust to the domain gap. (2) Two meta-tasks with identical sets of classes: this pair is useful because it can be employed to learn models that are robust against poorly sampled few-shots. To that end, a novel meta-knowledge distillation (MKD) objective is formulated. Extensive experiments demonstrate that both MDA and MKD significantly boost the performance of a variety of FSL methods, resulting in new state-of-the-art on three benchmarks.
AdarGCN: Adaptive Aggregation GCN for Few-Shot Learning
Mar 09, 2020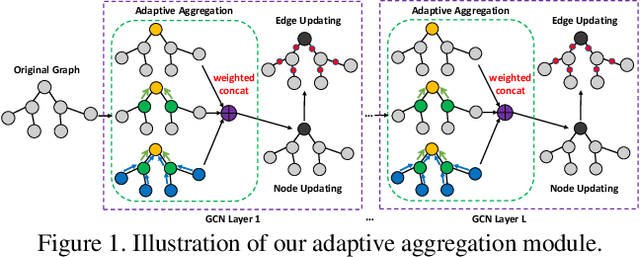
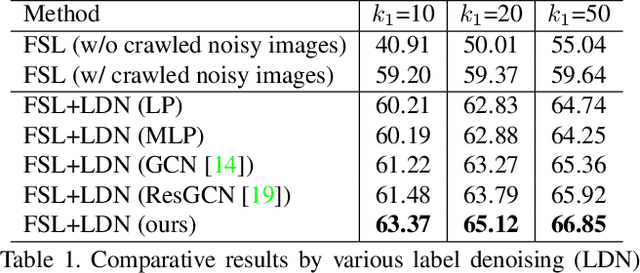
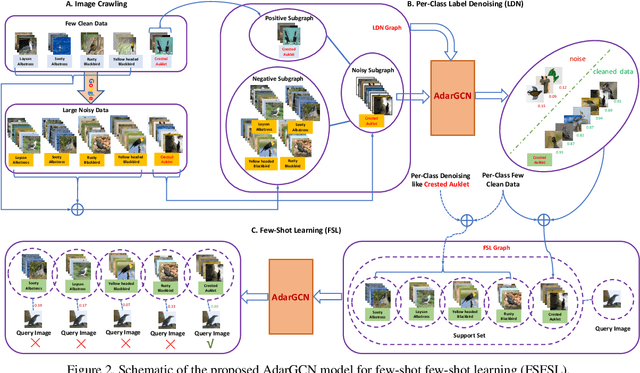
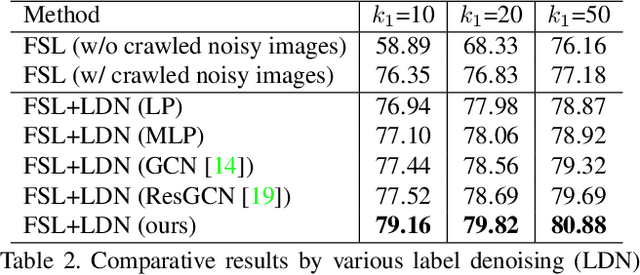
Existing few-shot learning (FSL) methods assume that there exist sufficient training samples from source classes for knowledge transfer to target classes with few training samples. However, this assumption is often invalid, especially when it comes to fine-grained recognition. In this work, we define a new FSL setting termed few-shot fewshot learning (FSFSL), under which both the source and target classes have limited training samples. To overcome the source class data scarcity problem, a natural option is to crawl images from the web with class names as search keywords. However, the crawled images are inevitably corrupted by large amount of noise (irrelevant images) and thus may harm the performance. To address this problem, we propose a graph convolutional network (GCN)-based label denoising (LDN) method to remove the irrelevant images. Further, with the cleaned web images as well as the original clean training images, we propose a GCN-based FSL method. For both the LDN and FSL tasks, a novel adaptive aggregation GCN (AdarGCN) model is proposed, which differs from existing GCN models in that adaptive aggregation is performed based on a multi-head multi-level aggregation module. With AdarGCN, how much and how far information carried by each graph node is propagated in the graph structure can be determined automatically, therefore alleviating the effects of both noisy and outlying training samples. Extensive experiments show the superior performance of our AdarGCN under both the new FSFSL and the conventional FSL settings.
Few-Shot Learning as Domain Adaptation: Algorithm and Analysis
Feb 12, 2020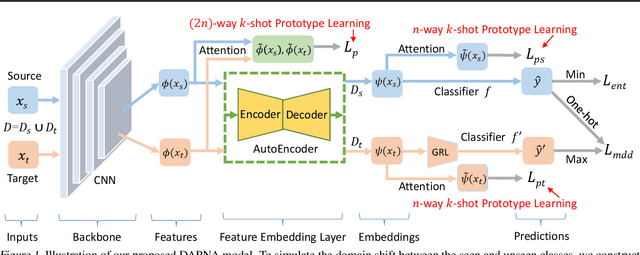
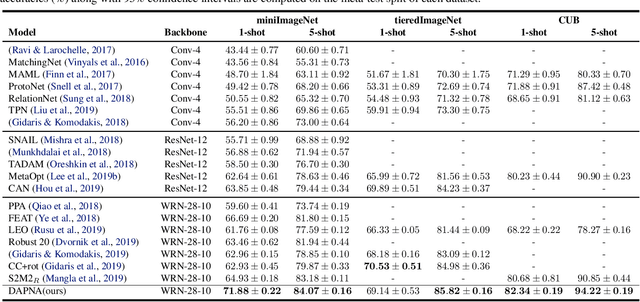
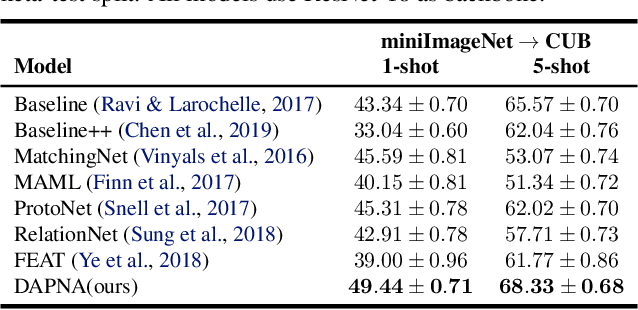
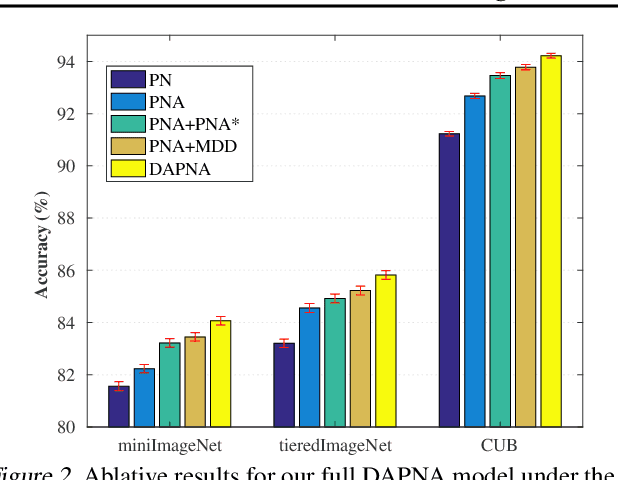
To recognize the unseen classes with only few samples, few-shot learning (FSL) uses prior knowledge learned from the seen classes. A major challenge for FSL is that the distribution of the unseen classes is different from that of those seen, resulting in poor generalization even when a model is meta-trained on the seen classes. This class-difference-caused distribution shift can be considered as a special case of domain shift. In this paper, for the first time, we propose a domain adaptation prototypical network with attention (DAPNA) to explicitly tackle such a domain shift problem in a meta-learning framework. Specifically, armed with a set transformer based attention module, we construct each episode with two sub-episodes without class overlap on the seen classes to simulate the domain shift between the seen and unseen classes. To align the feature distributions of the two sub-episodes with limited training samples, a feature transfer network is employed together with a margin disparity discrepancy (MDD) loss. Importantly, theoretical analysis is provided to give the learning bound of our DAPNA. Extensive experiments show that our DAPNA outperforms the state-of-the-art FSL alternatives, often by significant margins.
Learning Depth-Guided Convolutions for Monocular 3D Object Detection
Dec 13, 2019
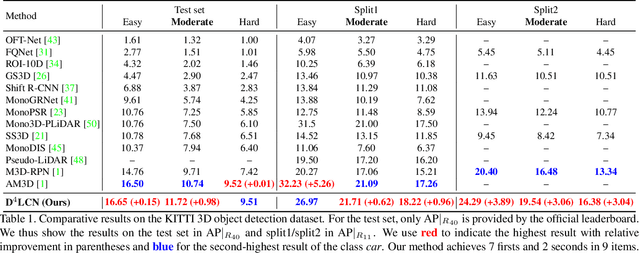
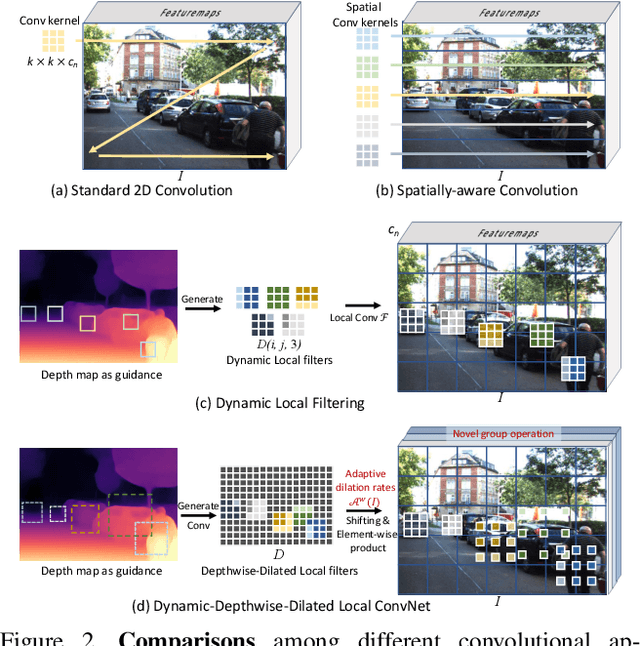
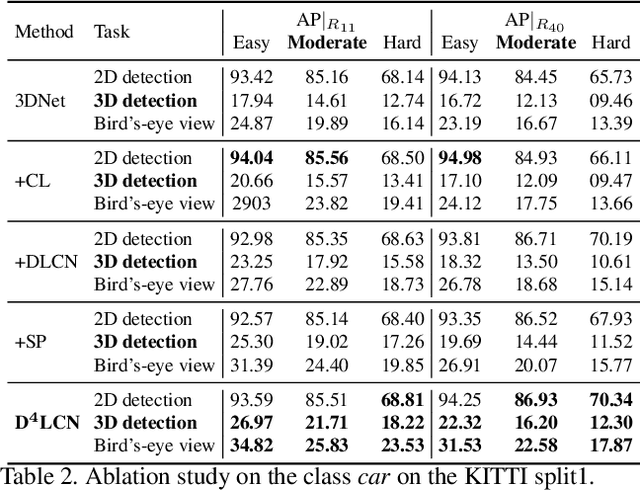
3D object detection from a single image without LiDAR is a challenging task due to the lack of accurate depth information. Conventional 2D convolutions are unsuitable for this task because they fail to capture local object and its scale information, which are vital for 3D object detection. To better represent 3D structure, prior arts typically transform depth maps estimated from 2D images into a pseudo-LiDAR representation, and then apply existing 3D point-cloud based object detectors. However, their results depend heavily on the accuracy of the estimated depth maps, resulting in suboptimal performance. In this work, instead of using pseudo-LiDAR representation, we improve the fundamental 2D fully convolutions by proposing a new local convolutional network (LCN), termed Depth-guided Dynamic-Depthwise-Dilated LCN (D$^4$LCN), where the filters and their receptive fields can be automatically learned from image-based depth maps, making different pixels of different images have different filters. D$^4$LCN overcomes the limitation of conventional 2D convolutions and narrows the gap between image representation and 3D point cloud representation. Extensive experiments show that D$^4$LCN outperforms existing works by large margins. For example, the relative improvement of D$^4$LCN against the state-of-the-art on KITTI is 9.1\% in the moderate setting. The code is available at https://github.com/dingmyu/D4LCN.
Every Frame Counts: Joint Learning of Video Segmentation and Optical Flow
Nov 28, 2019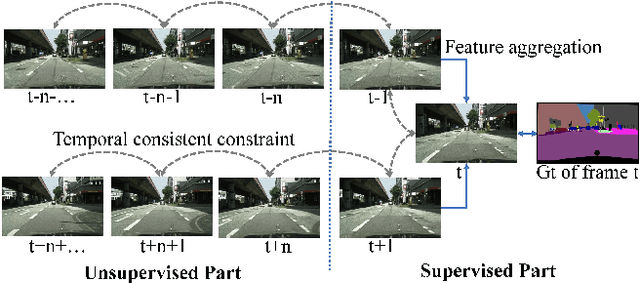

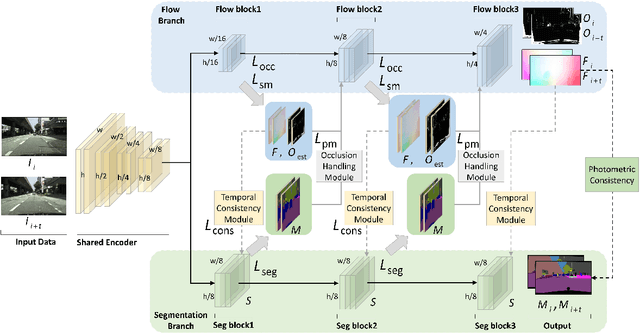
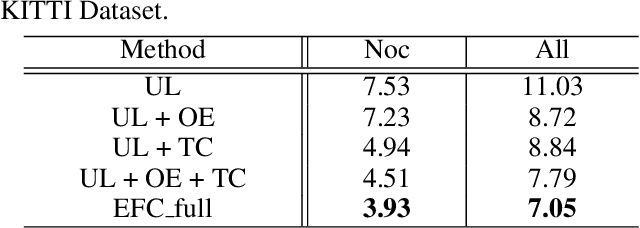
A major challenge for video semantic segmentation is the lack of labeled data. In most benchmark datasets, only one frame of a video clip is annotated, which makes most supervised methods fail to utilize information from the rest of the frames. To exploit the spatio-temporal information in videos, many previous works use pre-computed optical flows, which encode the temporal consistency to improve the video segmentation. However, the video segmentation and optical flow estimation are still considered as two separate tasks. In this paper, we propose a novel framework for joint video semantic segmentation and optical flow estimation. Semantic segmentation brings semantic information to handle occlusion for more robust optical flow estimation, while the non-occluded optical flow provides accurate pixel-level temporal correspondences to guarantee the temporal consistency of the segmentation. Moreover, our framework is able to utilize both labeled and unlabeled frames in the video through joint training, while no additional calculation is required in inference. Extensive experiments show that the proposed model makes the video semantic segmentation and optical flow estimation benefit from each other and outperforms existing methods under the same settings in both tasks.
Mobile Video Action Recognition
Aug 27, 2019
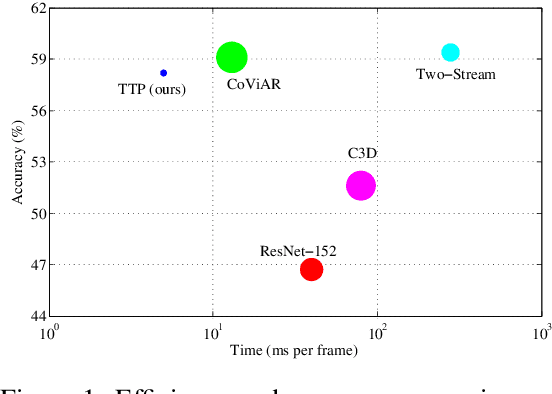
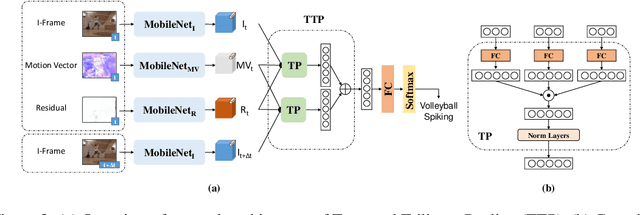

Video action recognition, which is topical in computer vision and video analysis, aims to allocate a short video clip to a pre-defined category such as brushing hair or climbing stairs. Recent works focus on action recognition with deep neural networks that achieve state-of-the-art results in need of high-performance platforms. Despite the fast development of mobile computing, video action recognition on mobile devices has not been fully discussed. In this paper, we focus on the novel mobile video action recognition task, where only the computational capabilities of mobile devices are accessible. Instead of raw videos with huge storage, we choose to extract multiple modalities (including I-frames, motion vectors, and residuals) directly from compressed videos. By employing MobileNetV2 as backbone, we propose a novel Temporal Trilinear Pooling (TTP) module to fuse the multiple modalities for mobile video action recognition. In addition to motion vectors, we also provide a temporal fusion method to explicitly induce the temporal context. The efficiency test on a mobile device indicates that our model can perform mobile video action recognition at about 40FPS. The comparative results on two benchmarks show that our model outperforms existing action recognition methods in model size and time consuming, but with competitive accuracy.
Variational Context: Exploiting Visual and Textual Context for Grounding Referring Expressions
Jul 08, 2019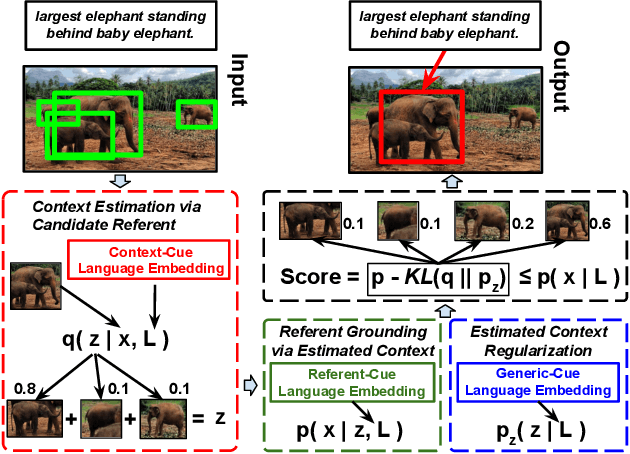
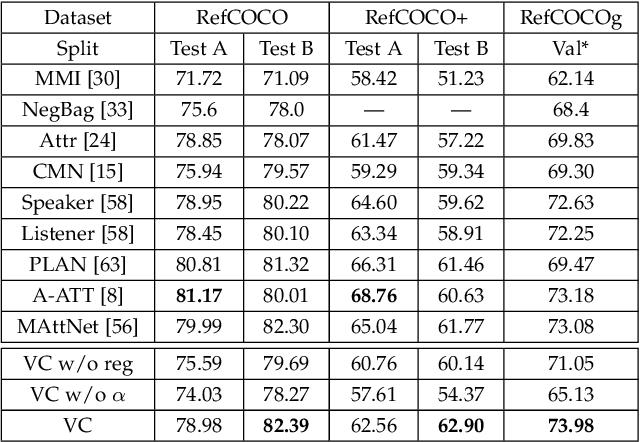

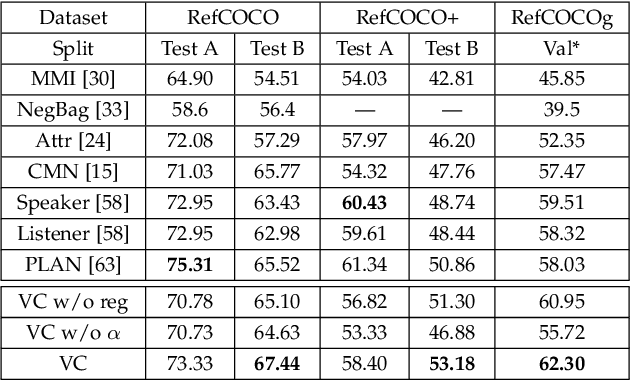
We focus on grounding (i.e., localizing or linking) referring expressions in images, e.g., ``largest elephant standing behind baby elephant''. This is a general yet challenging vision-language task since it does not only require the localization of objects, but also the multimodal comprehension of context -- visual attributes (e.g., ``largest'', ``baby'') and relationships (e.g., ``behind'') that help to distinguish the referent from other objects, especially those of the same category. Due to the exponential complexity involved in modeling the context associated with multiple image regions, existing work oversimplifies this task to pairwise region modeling by multiple instance learning. In this paper, we propose a variational Bayesian method, called Variational Context, to solve the problem of complex context modeling in referring expression grounding. Specifically, our framework exploits the reciprocal relation between the referent and context, i.e., either of them influences estimation of the posterior distribution of the other, and thereby the search space of context can be greatly reduced. In addition to reciprocity, our framework considers the semantic information of context, i.e., the referring expression can be reproduced based on the estimated context. We also extend the model to unsupervised setting where no annotation for the referent is available. Extensive experiments on various benchmarks show consistent improvement over state-of-the-art methods in both supervised and unsupervised settings.
Face-Focused Cross-Stream Network for Deception Detection in Videos
Dec 11, 2018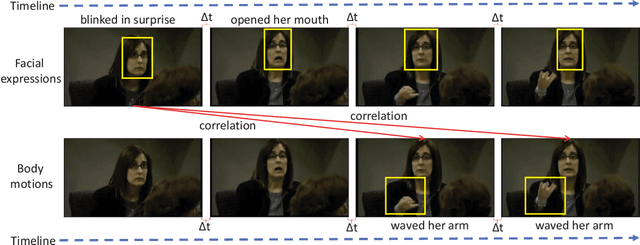
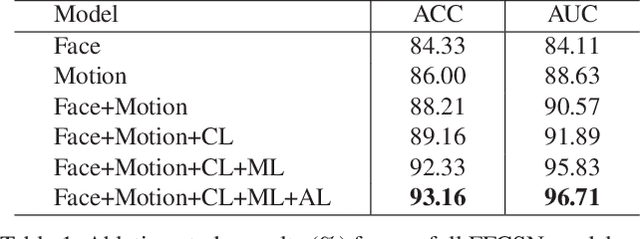
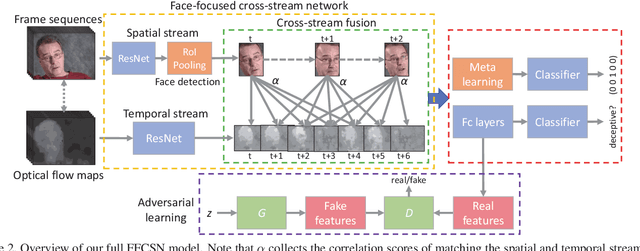
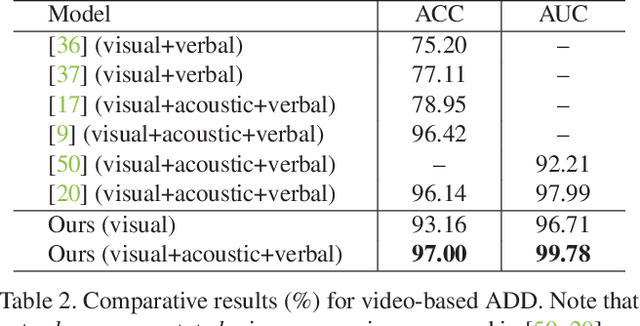
Automated deception detection (ADD) from real-life videos is a challenging task. It specifically needs to address two problems: (1) Both face and body contain useful cues regarding whether a subject is deceptive. How to effectively fuse the two is thus key to the effectiveness of an ADD model. (2) Real-life deceptive samples are hard to collect; learning with limited training data thus challenges most deep learning based ADD models. In this work, both problems are addressed. Specifically, for face-body multimodal learning, a novel face-focused cross-stream network (FFCSN) is proposed. It differs significantly from the popular two-stream networks in that: (a) face detection is added into the spatial stream to capture the facial expressions explicitly, and (b) correlation learning is performed across the spatial and temporal streams for joint deep feature learning across both face and body. To address the training data scarcity problem, our FFCSN model is trained with both meta learning and adversarial learning. Extensive experiments show that our FFCSN model achieves state-of-the-art results. Further, the proposed FFCSN model as well as its robust training strategy are shown to be generally applicable to other human-centric video analysis tasks such as emotion recognition from user-generated videos.
Zero-Shot Learning with Sparse Attribute Propagation
Dec 11, 2018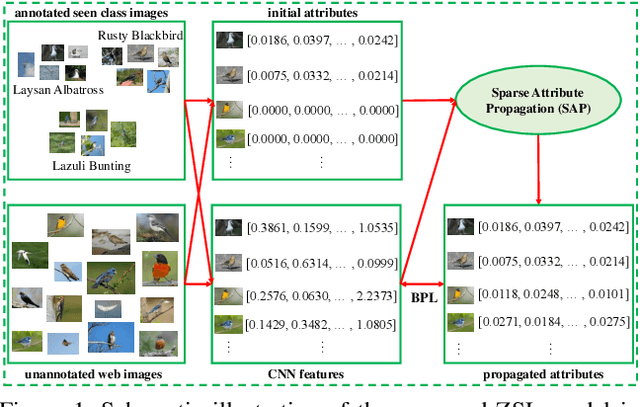
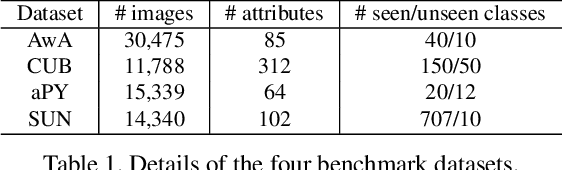
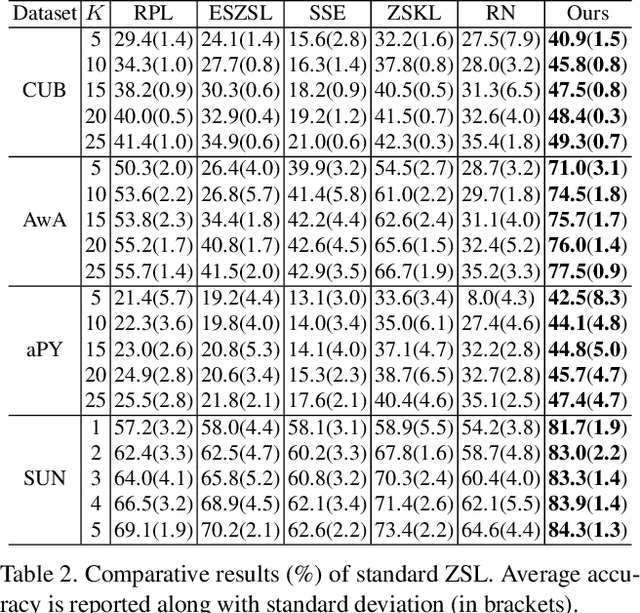

Zero-shot learning (ZSL) aims to recognize a set of unseen classes without any training images. The standard approach to ZSL requires a semantic descriptor for each class/instance, with attribute vector being the most widely used. Attribute annotation is expensive; it thus severely limits the scalability of ZSL. In this paper, we define a new ZSL setting where only a few images are annotated with attributes from each seen class. This is clearly more challenging yet more realistic than the conventional ZSL setting. To overcome the attribute sparsity under our new ZSL setting, we propose a novel inductive ZSL model termed sparse attribute propagation (SAP) by propagating attribute annotations to more unannotated images using sparse coding. This is followed by learning bidirectional projections between features and attributes for ZSL. An efficient solver is provided, together with rigorous theoretic algorithm analysis. With our SAP, we show that a ZSL training dataset can now be augmented by the abundant web images returned by image search engine, to further improve the model performance. Moreover, the general applicability of SAP is demonstrated on solving the social image annotation (SIA) problem. Extensive experiments show that our model achieves superior performance on both ZSL and SIA.
Recursive Visual Attention in Visual Dialog
Dec 06, 2018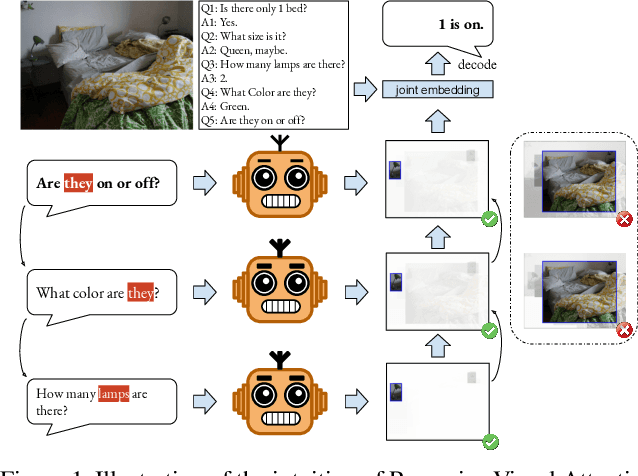
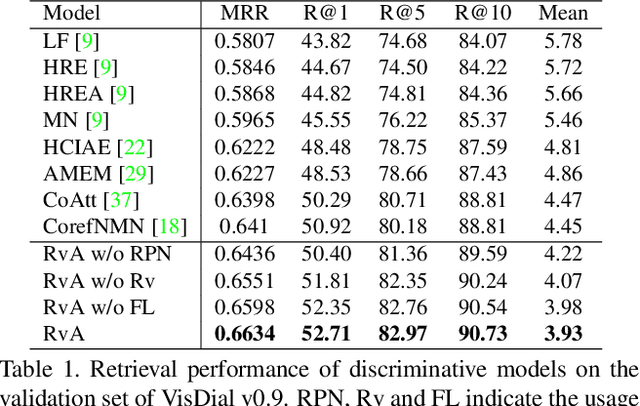
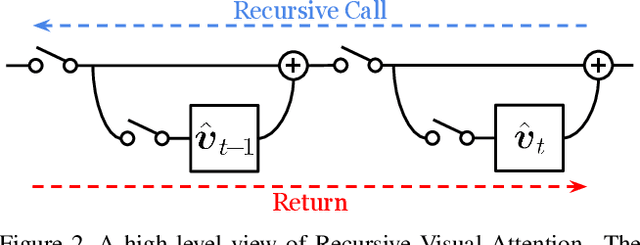
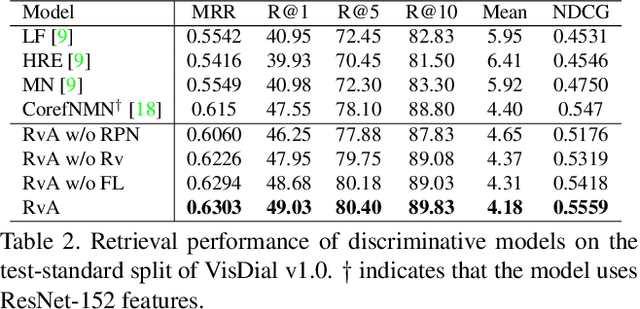
Visual dialog is a challenging vision-language task, which requires the agent to answer multi-round questions about an image. It typically needs to address two major problems: (1) How to answer visually-grounded questions, which is the core challenge in visual question answering (VQA); (2) How to infer the co-reference between questions and the dialog history. An example of visual co-reference is: pronouns (e.g., `they') in the question (e.g., `Are they on or off?') are linked with nouns (e.g., `lamps') appearing in the dialog history (e.g., `How many lamps are there?') and the object grounded in the image. In this work, to resolve the visual co-reference for visual dialog, we propose a novel attention mechanism called Recursive Visual Attention (RvA). Specifically, our dialog agent browses the dialog history until the agent has sufficient confidence in the visual co-reference resolution, and refines the visual attention recursively. The quantitative and qualitative experimental results on the large-scale VisDial v0.9 and v1.0 datasets demonstrate that the proposed RvA not only outperforms the state-of-the-art methods, but also achieves reasonable recursion and interpretable attention maps without additional annotations.