 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Model Schedule for Deep Learning Training
Feb 16, 2023Recent years have seen an increase in the development of large deep learning (DL) models, which makes training efficiency crucial. Common practice is struggling with the trade-off between usability and performance. On one hand, DL frameworks such as PyTorch use dynamic graphs to facilitate model developers at a price of sub-optimal model training performance. On the other hand, practitioners propose various approaches to improving the training efficiency by sacrificing some of the flexibility, ranging from making the graph static for more thorough optimization (e.g., XLA) to customizing optimization towards large-scale distributed training (e.g., DeepSpeed and Megatron-LM). In this paper, we aim to address the tension between usability and training efficiency through separation of concerns. Inspired by DL compilers that decouple the platform-specific optimizations of a tensor-level operator from its arithmetic definition, this paper proposes a schedule language to decouple model execution from definition. Specifically, the schedule works on a PyTorch model and uses a set of schedule primitives to convert the model for common model training optimizations such as high-performance kernels, effective 3D parallelism, and efficient activation checkpointing. Compared to existing optimization solutions, we optimize the model as-needed through high-level primitives, and thus preserving programmability and debuggability for users to a large extent. Our evaluation results show that by scheduling the existing hand-crafted optimizations in a systematic way, we are able to improve training throughput by up to 3.35x on a single machine with 8 NVIDIA V100 GPUs, and by up to 1.32x on multiple machines with up to 64 GPUs, when compared to the out-of-the-box performance of DeepSpeed and Megatron-LM.
Binarized Neural Machine Translation
Feb 09, 2023



The rapid scaling of language models is motivating research using low-bitwidth quantization. In this work, we propose a novel binarization technique for Transformers applied to machine translation (BMT), the first of its kind. We identify and address the problem of inflated dot-product variance when using one-bit weights and activations. Specifically, BMT leverages additional LayerNorms and residual connections to improve binarization quality. Experiments on the WMT dataset show that a one-bit weight-only Transformer can achieve the same quality as a float one, while being 16x smaller in size. One-bit activations incur varying degrees of quality drop, but mitigated by the proposed architectural changes. We further conduct a scaling law study using production-scale translation datasets, which shows that one-bit weight Transformers scale and generalize well in both in-domain and out-of-domain settings. Implementation in JAX/Flax will be open sourced.
Benchmarking GNN-Based Recommender Systems on Intel Optane Persistent Memory
Jul 25, 2022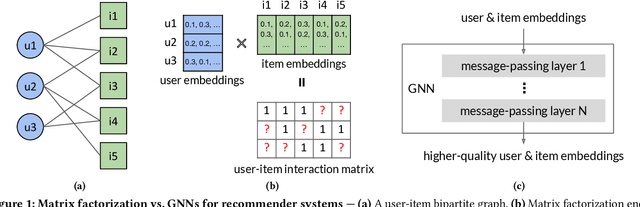
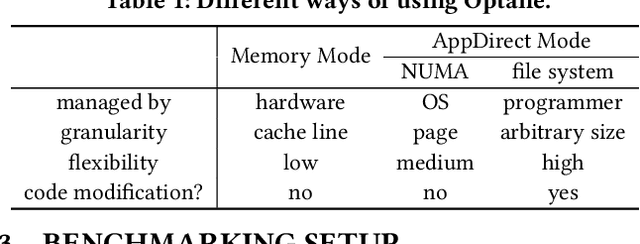

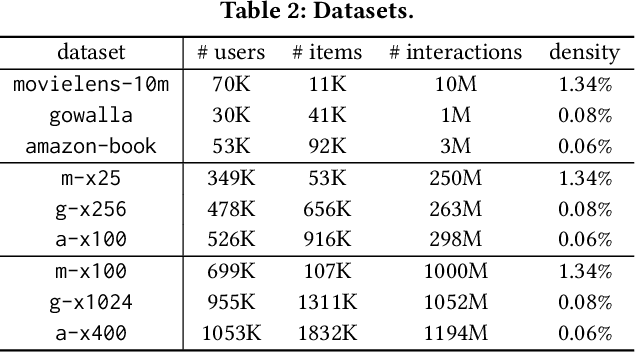
Graph neural networks (GNNs), which have emerged as an effective method for handling machine learning tasks on graphs, bring a new approach to building recommender systems, where the task of recommendation can be formulated as the link prediction problem on user-item bipartite graphs. Training GNN-based recommender systems (GNNRecSys) on large graphs incurs a large memory footprint, easily exceeding the DRAM capacity on a typical server. Existing solutions resort to distributed subgraph training, which is inefficient due to the high cost of dynamically constructing subgraphs and significant redundancy across subgraphs. The emerging Intel Optane persistent memory allows a single machine to have up to 6 TB of memory at an affordable cost, thus making single-machine GNNRecSys training feasible, which eliminates the inefficiencies in distributed training. One major concern of using Optane for GNNRecSys is Optane's relatively low bandwidth compared with DRAMs. This limitation can be particularly detrimental to achieving high performance for GNNRecSys workloads since their dominant compute kernels are sparse and memory access intensive. To understand whether Optane is a good fit for GNNRecSys training, we perform an in-depth characterization of GNNRecSys workloads and a comprehensive benchmarking study. Our benchmarking results show that when properly configured, Optane-based single-machine GNNRecSys training outperforms distributed training by a large margin, especially when handling deep GNN models. We analyze where the speedup comes from, provide guidance on how to configure Optane for GNNRecSys workloads, and discuss opportunities for further optimizations.
Structured Pruning is All You Need for Pruning CNNs at Initialization
Mar 04, 2022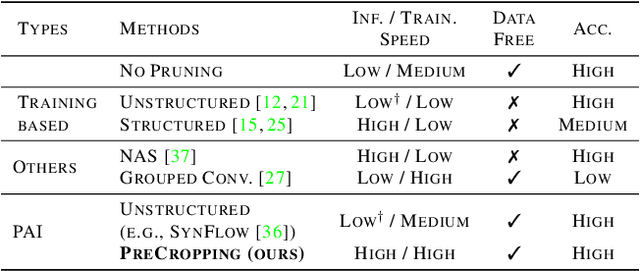
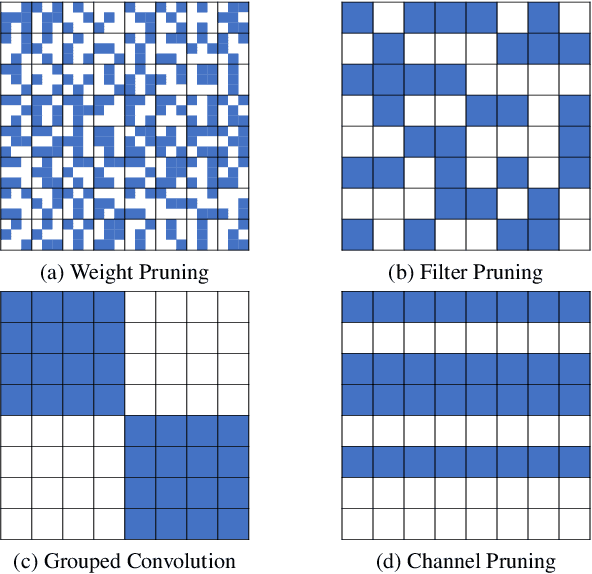
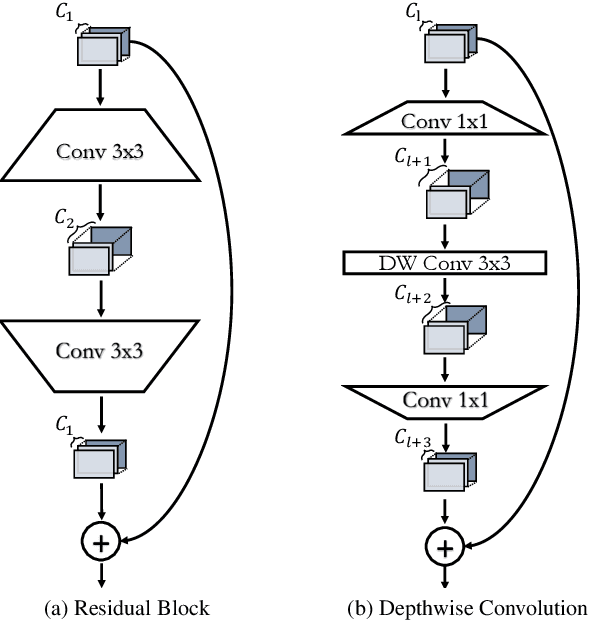
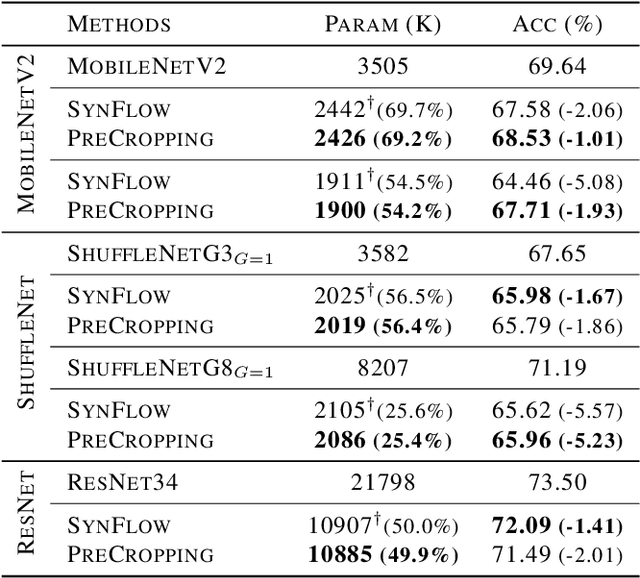
Pruning is a popular technique for reducing the model size and computational cost of convolutional neural networks (CNNs). However, a slow retraining or fine-tuning procedure is often required to recover the accuracy loss caused by pruning. Recently, a new research direction on weight pruning, pruning-at-initialization (PAI), is proposed to directly prune CNNs before training so that fine-tuning or retraining can be avoided. While PAI has shown promising results in reducing the model size, existing approaches rely on fine-grained weight pruning which requires unstructured sparse matrix computation, making it difficult to achieve real speedup in practice unless the sparsity is very high. This work is the first to show that fine-grained weight pruning is in fact not necessary for PAI. Instead, the layerwise compression ratio is the main critical factor to determine the accuracy of a CNN model pruned at initialization. Based on this key observation, we propose PreCropping, a structured hardware-efficient model compression scheme. PreCropping directly compresses the model at the channel level following the layerwise compression ratio. Compared to weight pruning, the proposed scheme is regular and dense in both storage and computation without sacrificing accuracy. In addition, since PreCropping compresses CNNs at initialization, the computational and memory costs of CNNs are reduced for both training and inference on commodity hardware. We empirically demonstrate our approaches on several modern CNN architectures, including ResNet, ShuffleNet, and MobileNet for both CIFAR-10 and ImageNet.
Understanding Hyperdimensional Computing for Parallel Single-Pass Learning
Feb 10, 2022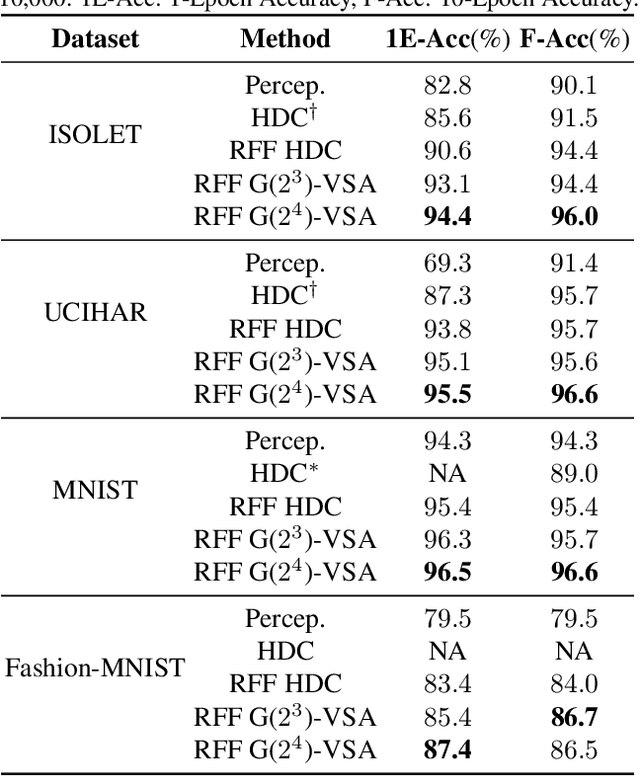
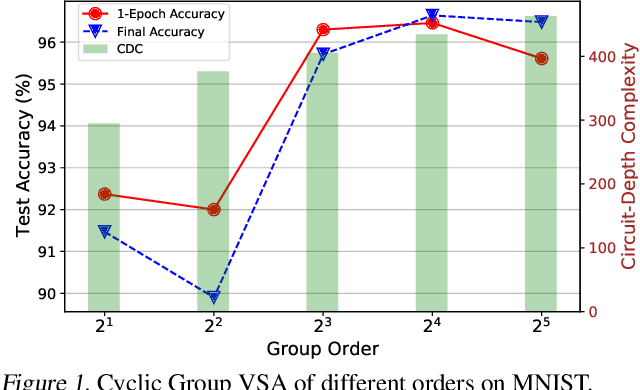

Hyperdimensional computing (HDC) is an emerging learning paradigm that computes with high dimensional binary vectors. It is attractive because of its energy efficiency and low latency, especially on emerging hardware -- but HDC suffers from low model accuracy, with little theoretical understanding of what limits its performance. We propose a new theoretical analysis of the limits of HDC via a consideration of what similarity matrices can be "expressed" by binary vectors, and we show how the limits of HDC can be approached using random Fourier features (RFF). We extend our analysis to the more general class of vector symbolic architectures (VSA), which compute with high-dimensional vectors (hypervectors) that are not necessarily binary. We propose a new class of VSAs, finite group VSAs, which surpass the limits of HDC. Using representation theory, we characterize which similarity matrices can be "expressed" by finite group VSA hypervectors, and we show how these VSAs can be constructed. Experimental results show that our RFF method and group VSA can both outperform the state-of-the-art HDC model by up to 7.6\% while maintaining hardware efficiency.
GARNET: Reduced-Rank Topology Learning for Robust and Scalable Graph Neural Networks
Feb 01, 2022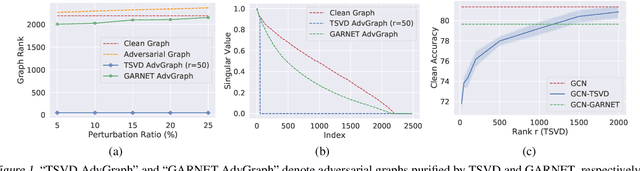
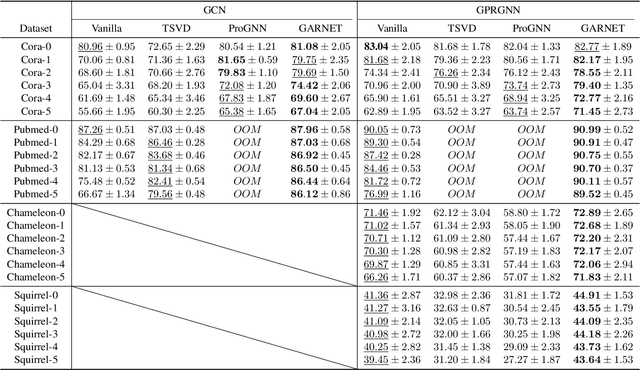
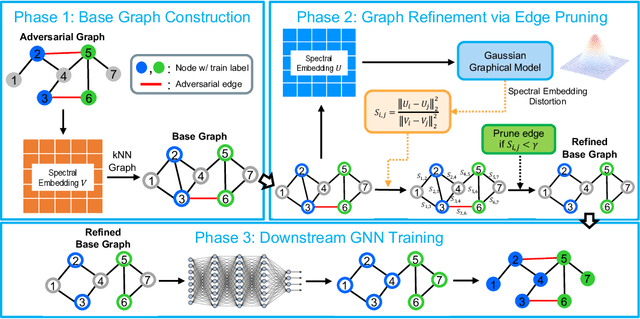
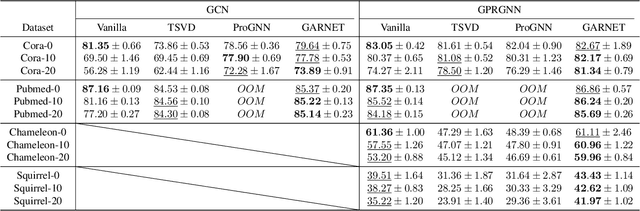
Graph neural networks (GNNs) have been increasingly deployed in various applications that involve learning on non-Euclidean data. However, recent studies show that GNNs are vulnerable to graph adversarial attacks. Although there are several defense methods to improve GNN robustness by eliminating adversarial components, they may also impair the underlying clean graph structure that contributes to GNN training. In addition, few of those defense models can scale to large graphs due to their high computational complexity and memory usage. In this paper, we propose GARNET, a scalable spectral method to boost the adversarial robustness of GNN models. GARNET first leverages weighted spectral embedding to construct a base graph, which is not only resistant to adversarial attacks but also contains critical (clean) graph structure for GNN training. Next, GARNET further refines the base graph by pruning additional uncritical edges based on probabilistic graphical model. GARNET has been evaluated on various datasets, including a large graph with millions of nodes. Our extensive experiment results show that GARNET achieves adversarial accuracy improvement and runtime speedup over state-of-the-art GNN (defense) models by up to 13.27% and 14.7x, respectively.
PokeBNN: A Binary Pursuit of Lightweight Accuracy
Nov 30, 2021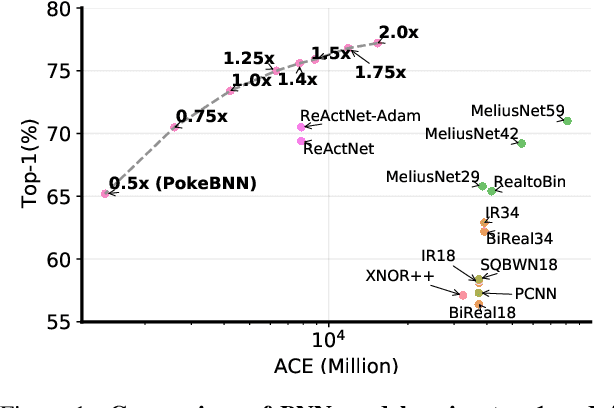
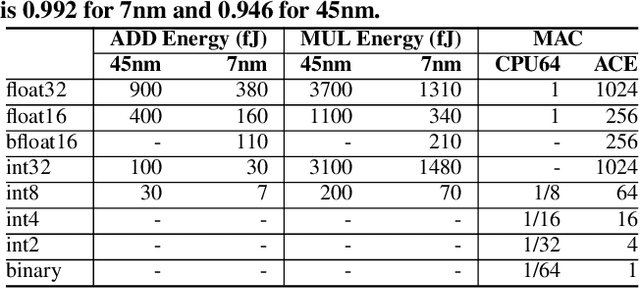

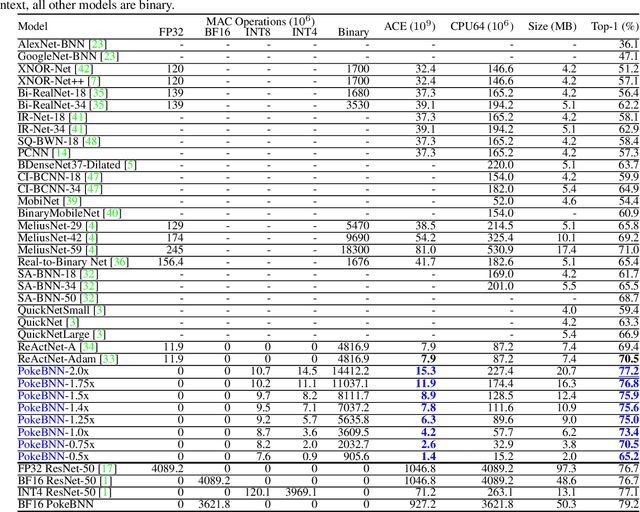
Top-1 ImageNet optimization promotes enormous networks that may be impractical in inference settings. Binary neural networks (BNNs) have the potential to significantly lower the compute intensity but existing models suffer from low quality. To overcome this deficiency, we propose PokeConv, a binary convolution block which improves quality of BNNs by techniques such as adding multiple residual paths, and tuning the activation function. We apply it to ResNet-50 and optimize ResNet's initial convolutional layer which is hard to binarize. We name the resulting network family PokeBNN. These techniques are chosen to yield favorable improvements in both top-1 accuracy and the network's cost. In order to enable joint optimization of the cost together with accuracy, we define arithmetic computation effort (ACE), a hardware- and energy-inspired cost metric for quantized and binarized networks. We also identify a need to optimize an under-explored hyper-parameter controlling the binarization gradient approximation. We establish a new, strong state-of-the-art (SOTA) on top-1 accuracy together with commonly-used CPU64 cost, ACE cost and network size metrics. ReActNet-Adam, the previous SOTA in BNNs, achieved a 70.5% top-1 accuracy with 7.9 ACE. A small variant of PokeBNN achieves 70.5% top-1 with 2.6 ACE, more than 3x reduction in cost; a larger PokeBNN achieves 75.6% top-1 with 7.8 ACE, more than 5% improvement in accuracy without increasing the cost. PokeBNN implementation in JAX/Flax and reproduction instructions are open sourced.
BulletTrain: Accelerating Robust Neural Network Training via Boundary Example Mining
Sep 29, 2021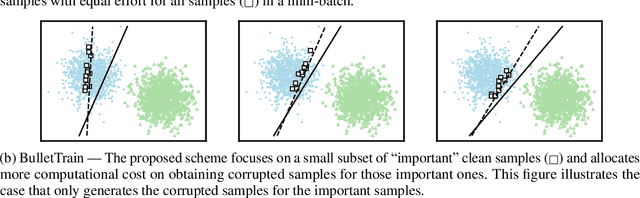

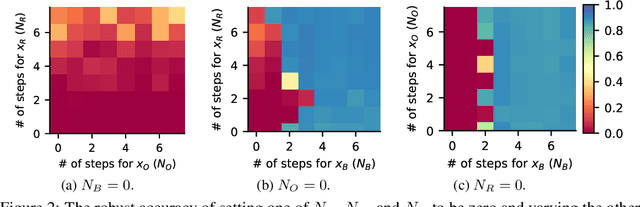
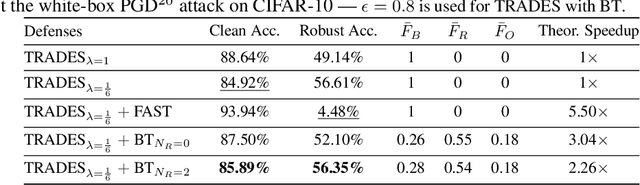
Neural network robustness has become a central topic in machine learning in recent years. Most training algorithms that improve the model's robustness to adversarial and common corruptions also introduce a large computational overhead, requiring as many as ten times the number of forward and backward passes in order to converge. To combat this inefficiency, we propose BulletTrain $-$ a boundary example mining technique to drastically reduce the computational cost of robust training. Our key observation is that only a small fraction of examples are beneficial for improving robustness. BulletTrain dynamically predicts these important examples and optimizes robust training algorithms to focus on the important examples. We apply our technique to several existing robust training algorithms and achieve a 2.1$\times$ speed-up for TRADES and MART on CIFAR-10 and a 1.7$\times$ speed-up for AugMix on CIFAR-10-C and CIFAR-100-C without any reduction in clean and robust accuracy.
Dense Pruning of Pointwise Convolutions in the Frequency Domain
Sep 16, 2021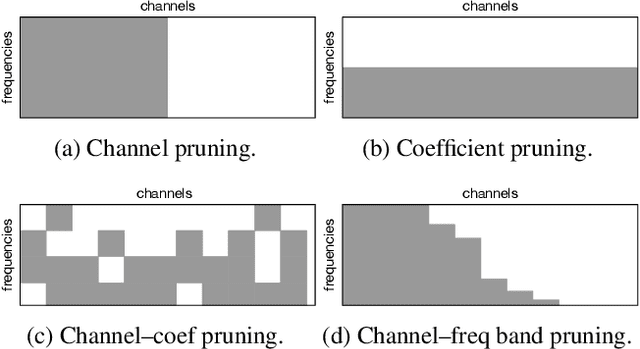

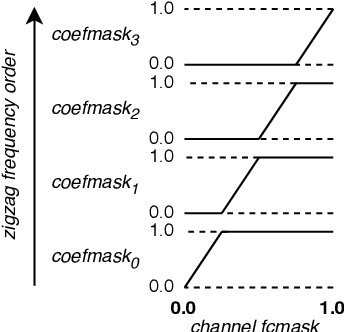

Depthwise separable convolutions and frequency-domain convolutions are two recent ideas for building efficient convolutional neural networks. They are seemingly incompatible: the vast majority of operations in depthwise separable CNNs are in pointwise convolutional layers, but pointwise layers use 1x1 kernels, which do not benefit from frequency transformation. This paper unifies these two ideas by transforming the activations, not the kernels. Our key insights are that 1) pointwise convolutions commute with frequency transformation and thus can be computed in the frequency domain without modification, 2) each channel within a given layer has a different level of sensitivity to frequency domain pruning, and 3) each channel's sensitivity to frequency pruning is approximately monotonic with respect to frequency. We leverage this knowledge by proposing a new technique which wraps each pointwise layer in a discrete cosine transform (DCT) which is truncated to selectively prune coefficients above a given threshold as per the needs of each channel. To learn which frequencies should be pruned from which channels, we introduce a novel learned parameter which specifies each channel's pruning threshold. We add a new regularization term which incentivizes the model to decrease the number of retained frequencies while still maintaining task accuracy. Unlike weight pruning techniques which rely on sparse operators, our contiguous frequency band pruning results in fully dense computation. We apply our technique to MobileNetV2 and in the process reduce computation time by 22% and incur <1% accuracy degradation.
Enabling Design Methodologies and Future Trends for Edge AI: Specialization and Co-design
Mar 30, 2021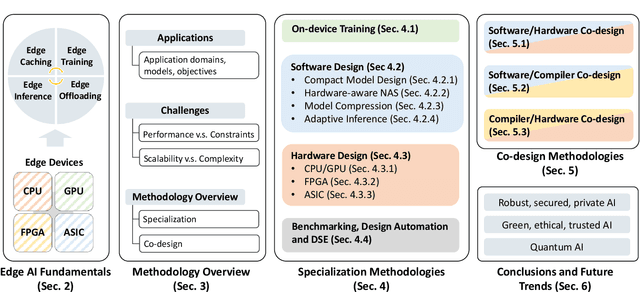
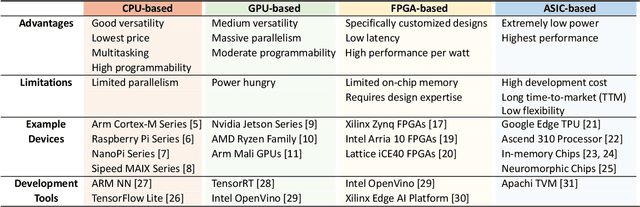

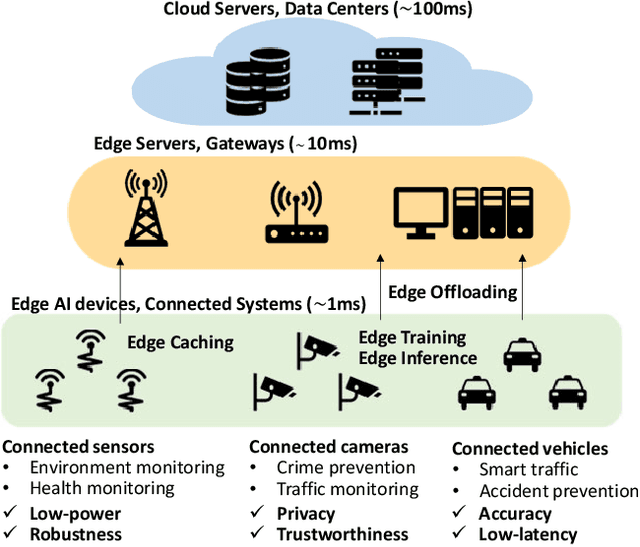
Artificial intelligence (AI) technologies have dramatically advanced in recent years, resulting in revolutionary changes in people's lives. Empowered by edge computing, AI workloads are migrating from centralized cloud architectures to distributed edge systems, introducing a new paradigm called edge AI. While edge AI has the promise of bringing significant increases in autonomy and intelligence into everyday lives through common edge devices, it also raises new challenges, especially for the development of its algorithms and the deployment of its services, which call for novel design methodologies catered to these unique challenges. In this paper, we provide a comprehensive survey of the latest enabling design methodologies that span the entire edge AI development stack. We suggest that the key methodologies for effective edge AI development are single-layer specialization and cross-layer co-design. We discuss representative methodologies in each category in detail, including on-device training methods, specialized software design, dedicated hardware design, benchmarking and design automation, software/hardware co-design, software/compiler co-design, and compiler/hardware co-design. Moreover, we attempt to reveal hidden cross-layer design opportunities that can further boost the solution quality of future edge AI and provide insights into future directions and emerging areas that require increased research focus.