 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Provable Splitting Approach for Symmetric Nonnegative Matrix Factorization
Jan 25, 2023



The symmetric Nonnegative Matrix Factorization (NMF), a special but important class of the general NMF, has found numerous applications in data analysis such as various clustering tasks. Unfortunately, designing fast algorithms for the symmetric NMF is not as easy as for its nonsymmetric counterpart, since the latter admits the splitting property that allows state-of-the-art alternating-type algorithms. To overcome this issue, we first split the decision variable and transform the symmetric NMF to a penalized nonsymmetric one, paving the way for designing efficient alternating-type algorithms. We then show that solving the penalized nonsymmetric reformulation returns a solution to the original symmetric NMF. Moreover, we design a family of alternating-type algorithms and show that they all admit strong convergence guarantee: the generated sequence of iterates is convergent and converges at least sublinearly to a critical point of the original symmetric NMF. Finally, we conduct experiments on both synthetic data and real image clustering to support our theoretical results and demonstrate the performance of the alternating-type algorithms.
Principled and Efficient Transfer Learning of Deep Models via Neural Collapse
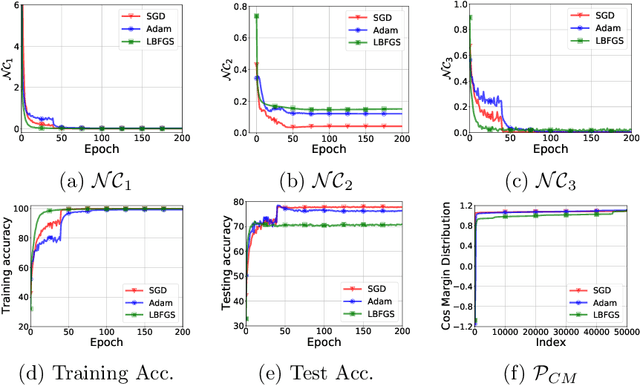
Jan 04, 2023With the ever-growing model size and the limited availability of labeled training data, transfer learning has become an increasingly popular approach in many science and engineering domains. For classification problems, this work delves into the mystery of transfer learning through an intriguing phenomenon termed neural collapse (NC), where the last-layer features and classifiers of learned deep networks satisfy: (i) the within-class variability of the features collapses to zero, and (ii) the between-class feature means are maximally and equally separated. Through the lens of NC, our findings for transfer learning are the following: (i) when pre-training models, preventing intra-class variability collapse (to a certain extent) better preserves the intrinsic structures of the input data, so that it leads to better model transferability; (ii) when fine-tuning models on downstream tasks, obtaining features with more NC on downstream data results in better test accuracy on the given task. The above results not only demystify many widely used heuristics in model pre-training (e.g., data augmentation, projection head, self-supervised learning), but also leads to more efficient and principled fine-tuning method on downstream tasks that we demonstrate through extensive experimental results.
Revisiting Sparse Convolutional Model for Visual Recognition
Oct 24, 2022



Despite strong empirical performance for image classification, deep neural networks are often regarded as ``black boxes'' and they are difficult to interpret. On the other hand, sparse convolutional models, which assume that a signal can be expressed by a linear combination of a few elements from a convolutional dictionary, are powerful tools for analyzing natural images with good theoretical interpretability and biological plausibility. However, such principled models have not demonstrated competitive performance when compared with empirically designed deep networks. This paper revisits the sparse convolutional modeling for image classification and bridges the gap between good empirical performance (of deep learning) and good interpretability (of sparse convolutional models). Our method uses differentiable optimization layers that are defined from convolutional sparse coding as drop-in replacements of standard convolutional layers in conventional deep neural networks. We show that such models have equally strong empirical performance on CIFAR-10, CIFAR-100, and ImageNet datasets when compared to conventional neural networks. By leveraging stable recovery property of sparse modeling, we further show that such models can be much more robust to input corruptions as well as adversarial perturbations in testing through a simple proper trade-off between sparse regularization and data reconstruction terms. Source code can be found at https://github.com/Delay-Xili/SDNet.
Are All Losses Created Equal: A Neural Collapse Perspective
Oct 08, 2022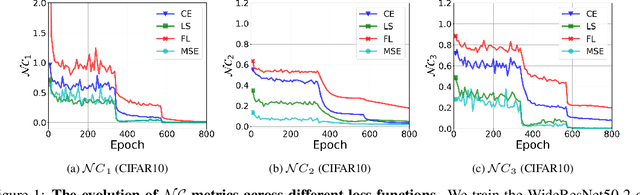
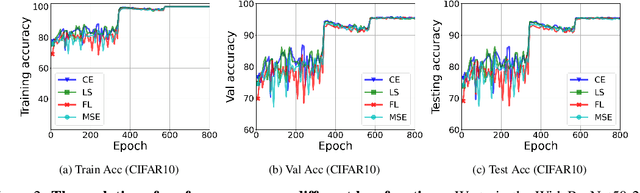
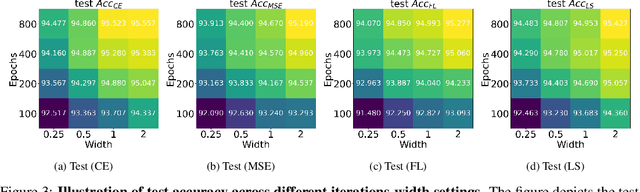
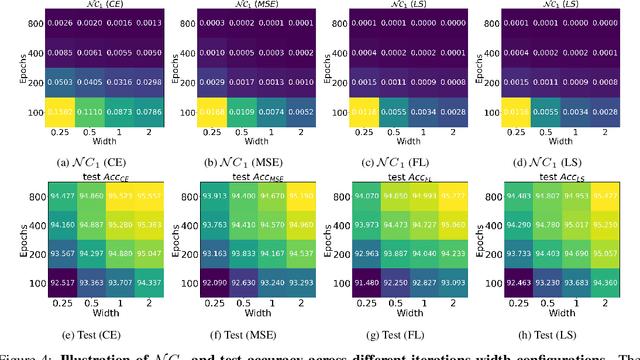
While cross entropy (CE) is the most commonly used loss to train deep neural networks for classification tasks, many alternative losses have been developed to obtain better empirical performance. Among them, which one is the best to use is still a mystery, because there seem to be multiple factors affecting the answer, such as properties of the dataset, the choice of network architecture, and so on. This paper studies the choice of loss function by examining the last-layer features of deep networks, drawing inspiration from a recent line work showing that the global optimal solution of CE and mean-square-error (MSE) losses exhibits a Neural Collapse phenomenon. That is, for sufficiently large networks trained until convergence, (i) all features of the same class collapse to the corresponding class mean and (ii) the means associated with different classes are in a configuration where their pairwise distances are all equal and maximized. We extend such results and show through global solution and landscape analyses that a broad family of loss functions including commonly used label smoothing (LS) and focal loss (FL) exhibits Neural Collapse. Hence, all relevant losses(i.e., CE, LS, FL, MSE) produce equivalent features on training data. Based on the unconstrained feature model assumption, we provide either the global landscape analysis for LS loss or the local landscape analysis for FL loss and show that the (only!) global minimizers are neural collapse solutions, while all other critical points are strict saddles whose Hessian exhibit negative curvature directions either in the global scope for LS loss or in the local scope for FL loss near the optimal solution. The experiments further show that Neural Collapse features obtained from all relevant losses lead to largely identical performance on test data as well, provided that the network is sufficiently large and trained until convergence.
A Validation Approach to Over-parameterized Matrix and Image Recovery
Sep 21, 2022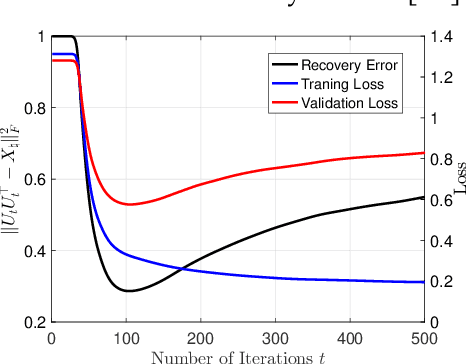
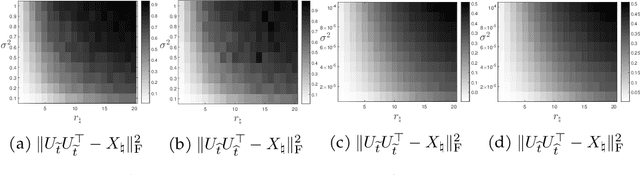
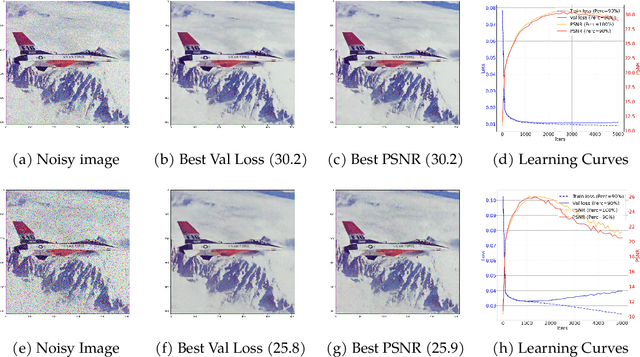
In this paper, we study the problem of recovering a low-rank matrix from a number of noisy random linear measurements. We consider the setting where the rank of the ground-truth matrix is unknown a prior and use an overspecified factored representation of the matrix variable, where the global optimal solutions overfit and do not correspond to the underlying ground-truth. We then solve the associated nonconvex problem using gradient descent with small random initialization. We show that as long as the measurement operators satisfy the restricted isometry property (RIP) with its rank parameter scaling with the rank of ground-truth matrix rather than scaling with the overspecified matrix variable, gradient descent iterations are on a particular trajectory towards the ground-truth matrix and achieve nearly information-theoretically optimal recovery when stop appropriately. We then propose an efficient early stopping strategy based on the common hold-out method and show that it detects nearly optimal estimator provably. Moreover, experiments show that the proposed validation approach can also be efficiently used for image restoration with deep image prior which over-parameterizes an image with a deep network.
Neural Collapse with Normalized Features: A Geometric Analysis over the Riemannian Manifold
Sep 19, 2022

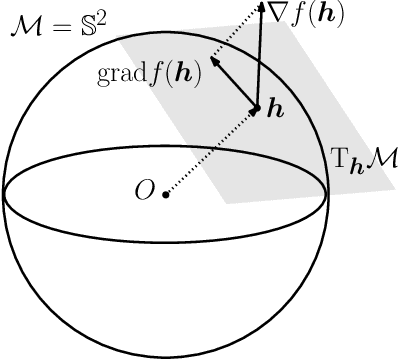

When training overparameterized deep networks for classification tasks, it has been widely observed that the learned features exhibit a so-called "neural collapse" phenomenon. More specifically, for the output features of the penultimate layer, for each class the within-class features converge to their means, and the means of different classes exhibit a certain tight frame structure, which is also aligned with the last layer's classifier. As feature normalization in the last layer becomes a common practice in modern representation learning, in this work we theoretically justify the neural collapse phenomenon for normalized features. Based on an unconstrained feature model, we simplify the empirical loss function in a multi-class classification task into a nonconvex optimization problem over the Riemannian manifold by constraining all features and classifiers over the sphere. In this context, we analyze the nonconvex landscape of the Riemannian optimization problem over the product of spheres, showing a benign global landscape in the sense that the only global minimizers are the neural collapse solutions while all other critical points are strict saddles with negative curvature. Experimental results on practical deep networks corroborate our theory and demonstrate that better representations can be learned faster via feature normalization.
Sparsity-guided Network Design for Frame Interpolation
Sep 09, 2022
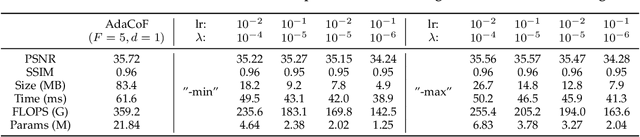
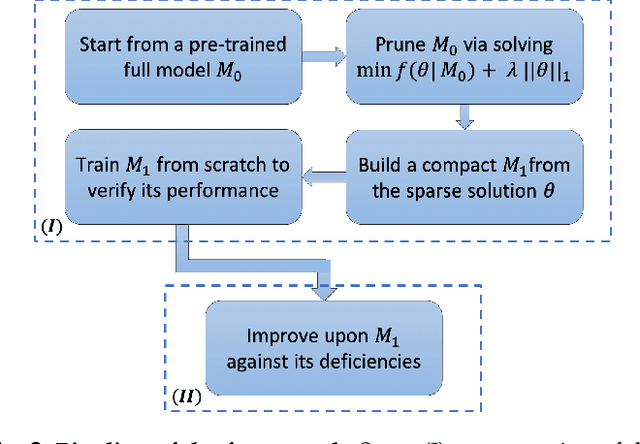
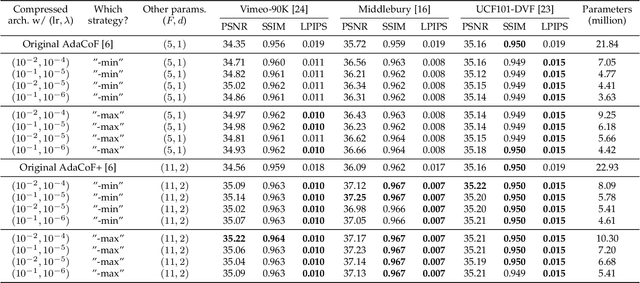
DNN-based frame interpolation, which generates intermediate frames from two consecutive frames, is often dependent on model architectures with a large number of features, preventing their deployment on systems with limited resources, such as mobile devices. We present a compression-driven network design for frame interpolation that leverages model pruning through sparsity-inducing optimization to greatly reduce the model size while attaining higher performance. Concretely, we begin by compressing the recently proposed AdaCoF model and demonstrating that a 10 times compressed AdaCoF performs similarly to its original counterpart, where different strategies for using layerwise sparsity information as a guide are comprehensively investigated under a variety of hyperparameter settings. We then enhance this compressed model by introducing a multi-resolution warping module, which improves visual consistency with multi-level details. As a result, we achieve a considerable performance gain with a quarter of the size of the original AdaCoF. In addition, our model performs favorably against other state-of-the-art approaches on a wide variety of datasets. We note that the suggested compression-driven framework is generic and can be easily transferred to other DNN-based frame interpolation algorithms. The source code is available at https://github.com/tding1/CDFI.
Error Analysis of Tensor-Train Cross Approximation
Jul 09, 2022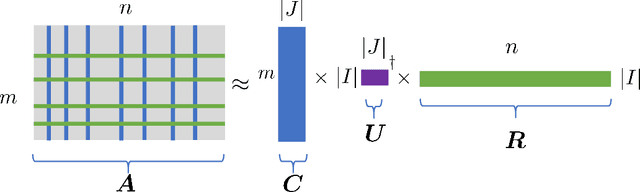
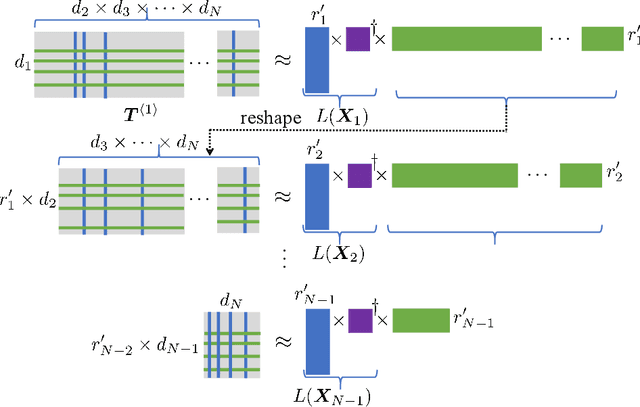
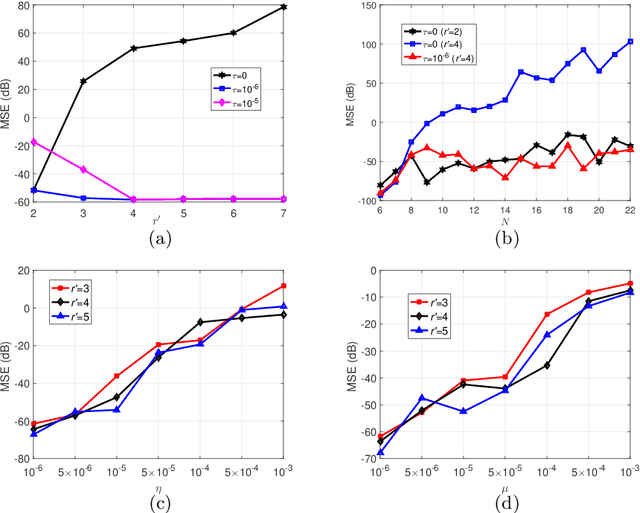
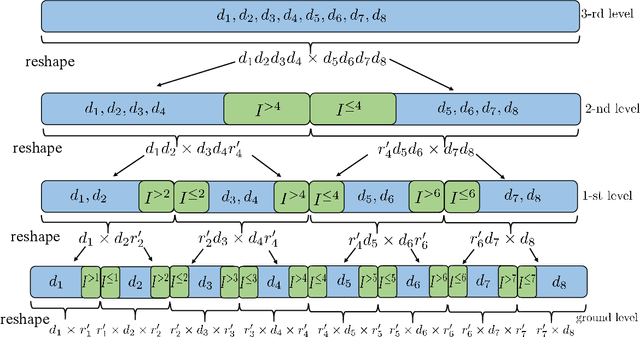
Tensor train decomposition is widely used in machine learning and quantum physics due to its concise representation of high-dimensional tensors, overcoming the curse of dimensionality. Cross approximation-originally developed for representing a matrix from a set of selected rows and columns-is an efficient method for constructing a tensor train decomposition of a tensor from few of its entries. While tensor train cross approximation has achieved remarkable performance in practical applications, its theoretical analysis, in particular regarding the error of the approximation, is so far lacking. To our knowledge, existing results only provide element-wise approximation accuracy guarantees, which lead to a very loose bound when extended to the entire tensor. In this paper, we bridge this gap by providing accuracy guarantees in terms of the entire tensor for both exact and noisy measurements. Our results illustrate how the choice of selected subtensors affects the quality of the cross approximation and that the approximation error caused by model error and/or measurement error may not grow exponentially with the order of the tensor. These results are verified by numerical experiments, and may have important implications for the usefulness of cross approximations for high-order tensors, such as those encountered in the description of quantum many-body states.
On the Optimization Landscape of Neural Collapse under MSE Loss: Global Optimality with Unconstrained Features
Mar 12, 2022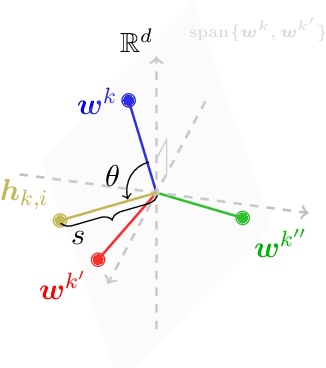
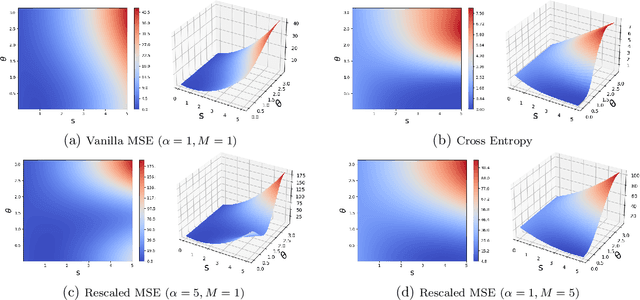

When training deep neural networks for classification tasks, an intriguing empirical phenomenon has been widely observed in the last-layer classifiers and features, where (i) the class means and the last-layer classifiers all collapse to the vertices of a Simplex Equiangular Tight Frame (ETF) up to scaling, and (ii) cross-example within-class variability of last-layer activations collapses to zero. This phenomenon is called Neural Collapse (NC), which seems to take place regardless of the choice of loss functions. In this work, we justify NC under the mean squared error (MSE) loss, where recent empirical evidence shows that it performs comparably or even better than the de-facto cross-entropy loss. Under a simplified unconstrained feature model, we provide the first global landscape analysis for vanilla nonconvex MSE loss and show that the (only!) global minimizers are neural collapse solutions, while all other critical points are strict saddles whose Hessian exhibit negative curvature directions. Furthermore, we justify the usage of rescaled MSE loss by probing the optimization landscape around the NC solutions, showing that the landscape can be improved by tuning the rescaling hyperparameters. Finally, our theoretical findings are experimentally verified on practical network architectures.
Robust Training under Label Noise by Over-parameterization
Feb 28, 2022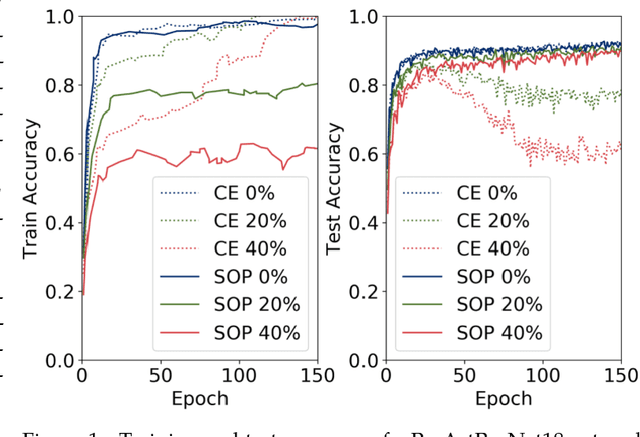
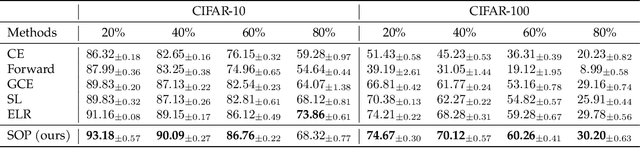
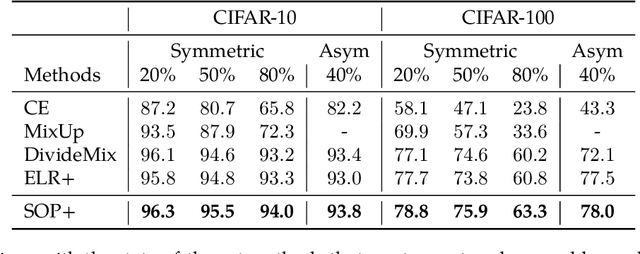
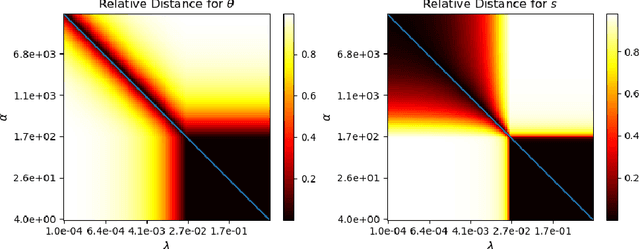
Recently, over-parameterized deep networks, with increasingly more network parameters than training samples, have dominated the performances of modern machine learning. However, when the training data is corrupted, it has been well-known that over-parameterized networks tend to overfit and do not generalize. In this work, we propose a principled approach for robust training of over-parameterized deep networks in classification tasks where a proportion of training labels are corrupted. The main idea is yet very simple: label noise is sparse and incoherent with the network learned from clean data, so we model the noise and learn to separate it from the data. Specifically, we model the label noise via another sparse over-parameterization term, and exploit implicit algorithmic regularizations to recover and separate the underlying corruptions. Remarkably, when trained using such a simple method in practice, we demonstrate state-of-the-art test accuracy against label noise on a variety of real datasets. Furthermore, our experimental results are corroborated by theory on simplified linear models, showing that exact separation between sparse noise and low-rank data can be achieved under incoherent conditions. The work opens many interesting directions for improving over-parameterized models by using sparse over-parameterization and implicit regularization.