 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimpleTrack: Understanding and Rethinking 3D Multi-object Tracking
Nov 18, 2021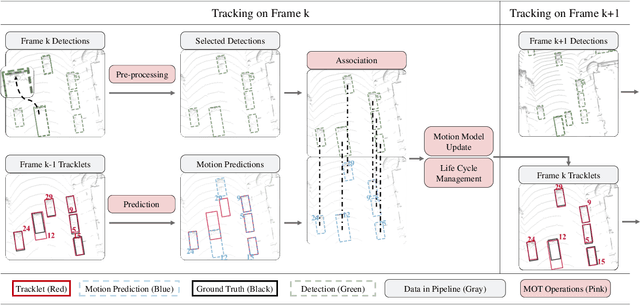
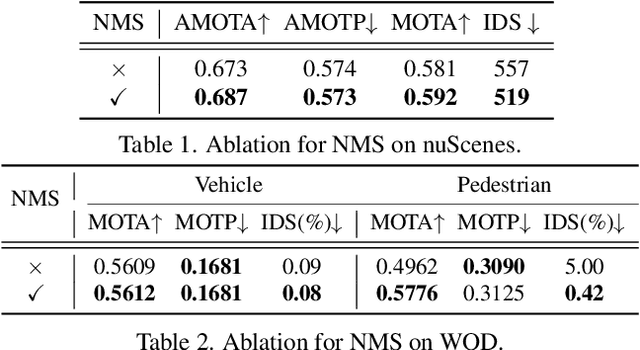
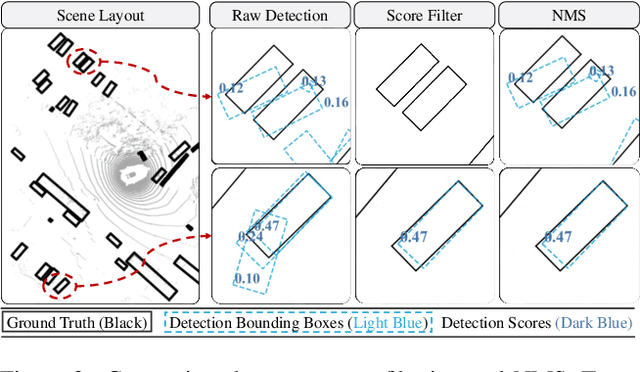
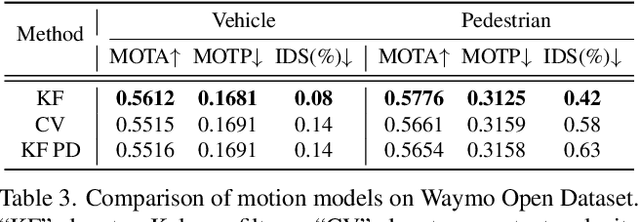
3D multi-object tracking (MOT) has witnessed numerous novel benchmarks and approaches in recent years, especially those under the "tracking-by-detection" paradigm. Despite their progress and usefulness, an in-depth analysis of their strengths and weaknesses is not yet available. In this paper, we summarize current 3D MOT methods into a unified framework by decomposing them into four constituent parts: pre-processing of detection, association, motion model, and life cycle management. We then ascribe the failure cases of existing algorithms to each component and investigate them in detail. Based on the analyses, we propose corresponding improvements which lead to a strong yet simple baseline: SimpleTrack. Comprehensive experimental results on Waymo Open Dataset and nuScenes demonstrate that our final method could achieve new state-of-the-art results with minor modifications. Furthermore, we take additional steps and rethink whether current benchmarks authentically reflect the ability of algorithms for real-world challenges. We delve into the details of existing benchmarks and find some intriguing facts. Finally, we analyze the distribution and causes of remaining failures in \name\ and propose future directions for 3D MOT. Our code is available at https://github.com/TuSimple/SimpleTrack.
Serving DNN Models with Multi-Instance GPUs: A Case of the Reconfigurable Machine Scheduling Problem
Sep 18, 2021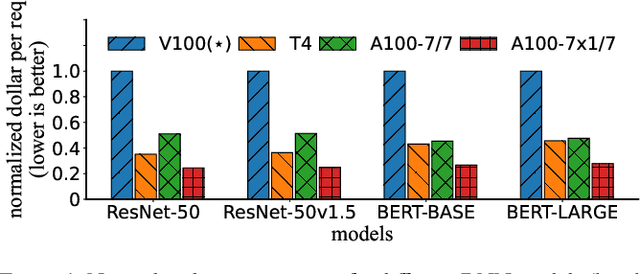
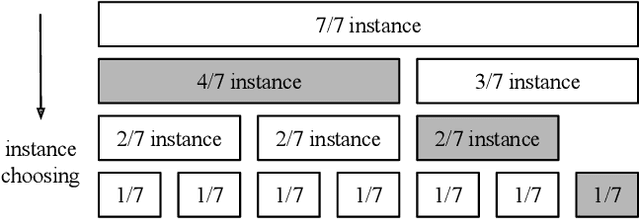
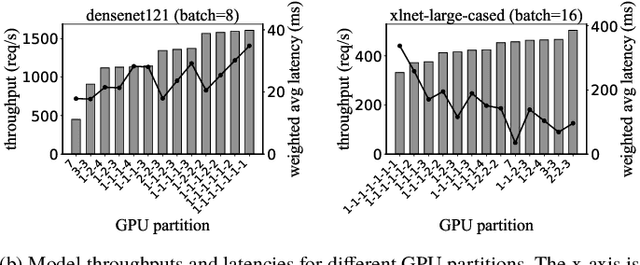
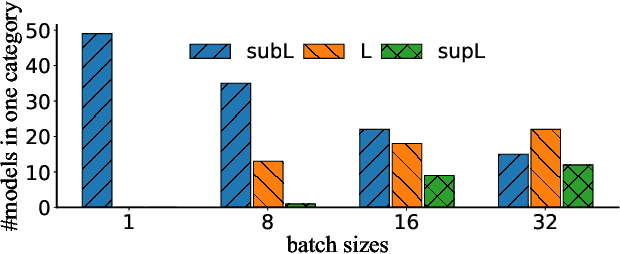
Multi-Instance GPU (MIG) is a new feature introduced by NVIDIA A100 GPUs that partitions one physical GPU into multiple GPU instances. With MIG, A100 can be the most cost-efficient GPU ever for serving Deep Neural Networks (DNNs). However, discovering the most efficient GPU partitions is challenging. The underlying problem is NP-hard; moreover, it is a new abstract problem, which we define as the Reconfigurable Machine Scheduling Problem (RMS). This paper studies serving DNNs with MIG, a new case of RMS. We further propose a solution, MIG-serving. MIG- serving is an algorithm pipeline that blends a variety of newly designed algorithms and customized classic algorithms, including a heuristic greedy algorithm, Genetic Algorithm (GA), and Monte Carlo Tree Search algorithm (MCTS). We implement MIG-serving on Kubernetes. Our experiments show that compared to using A100 as-is, MIG-serving can save up to 40% of GPUs while providing the same throughput.
Comparison between safety methods control barrier function vs. reachability analysis
Jun 24, 2021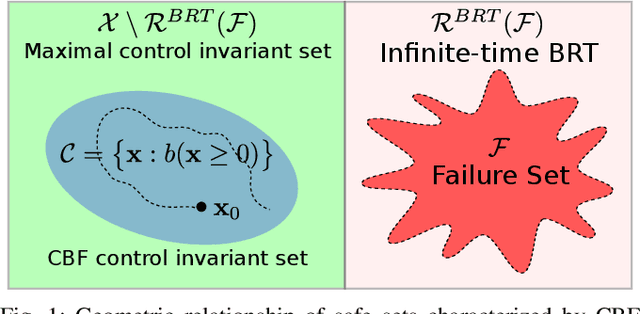
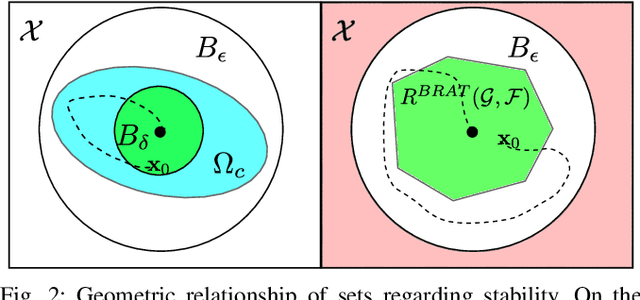
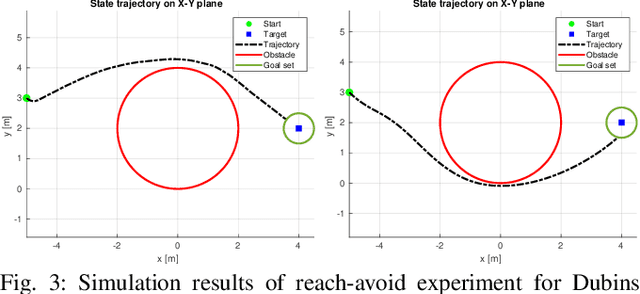

This report aims to compare two safety methods: control barrier function and Hamilton-Jacobi reachability analysis. We will consider the difference with a focus on the following aspects: generality of system dynamics, difficulty of construction and computation cost. A standard Dubins car model will be evaluated numerically to make the comparison more concrete.
Unsupervised Scale-consistent Depth Learning from Video
May 25, 2021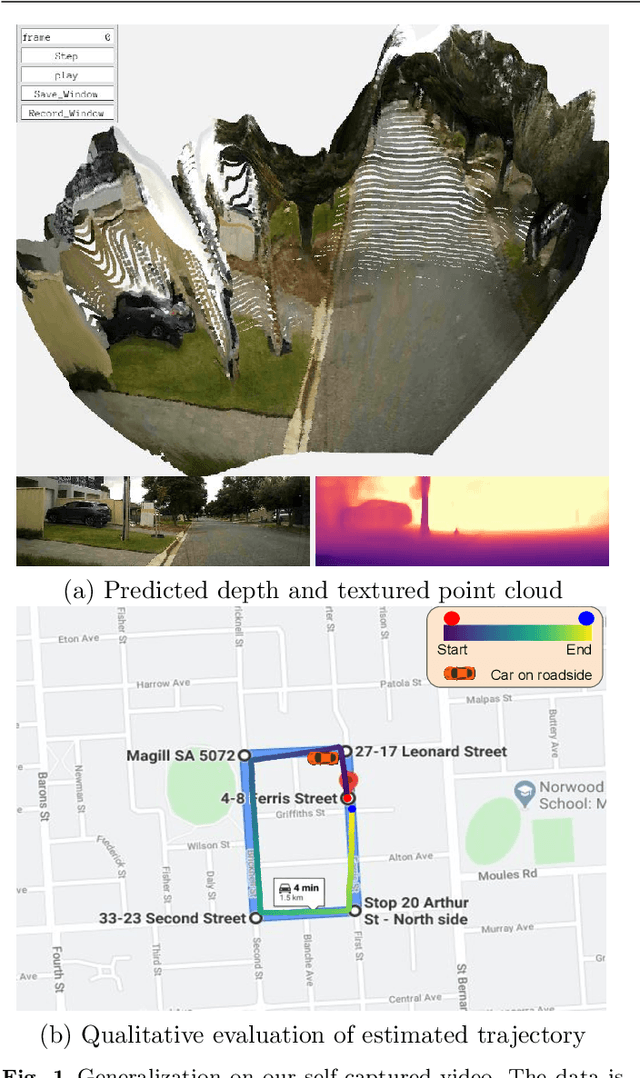
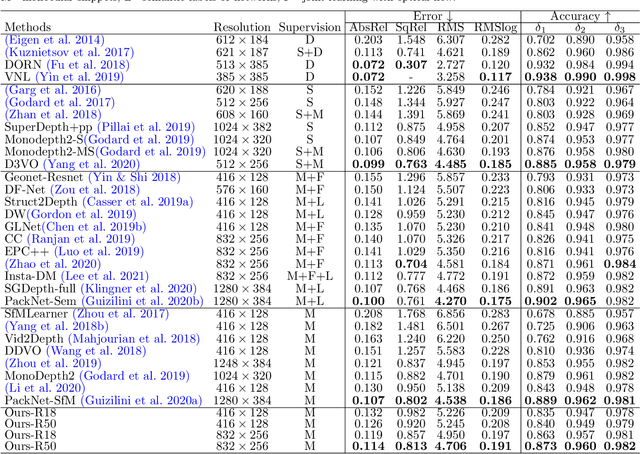
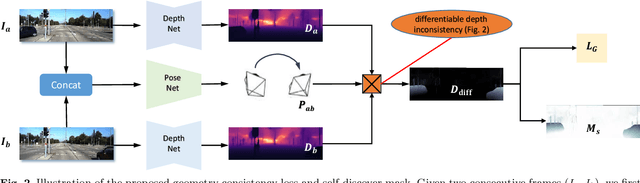
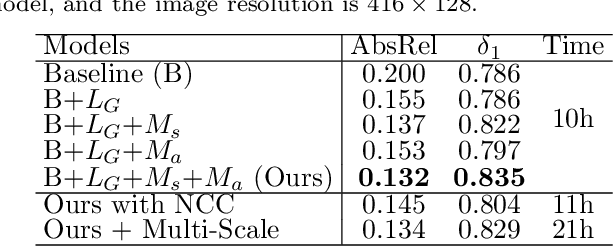
We propose a monocular depth estimator SC-Depth, which requires only unlabelled videos for training and enables the scale-consistent prediction at inference time. Our contributions include: (i) we propose a geometry consistency loss, which penalizes the inconsistency of predicted depths between adjacent views; (ii) we propose a self-discovered mask to automatically localize moving objects that violate the underlying static scene assumption and cause noisy signals during training; (iii) we demonstrate the efficacy of each component with a detailed ablation study and show high-quality depth estimation results in both KITTI and NYUv2 datasets. Moreover, thanks to the capability of scale-consistent prediction, we show that our monocular-trained deep networks are readily integrated into the ORB-SLAM2 system for more robust and accurate tracking. The proposed hybrid Pseudo-RGBD SLAM shows compelling results in KITTI, and it generalizes well to the KAIST dataset without additional training. Finally, we provide several demos for qualitative evaluation.
LiDAR R-CNN: An Efficient and Universal 3D Object Detector
Mar 29, 2021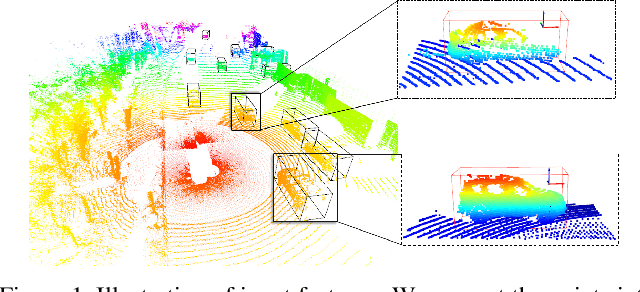
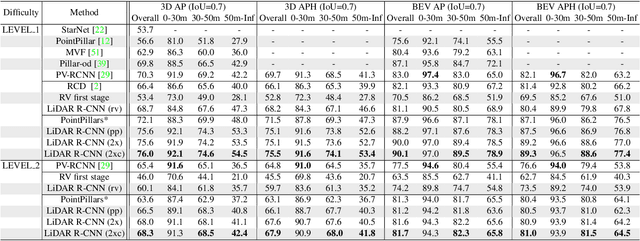
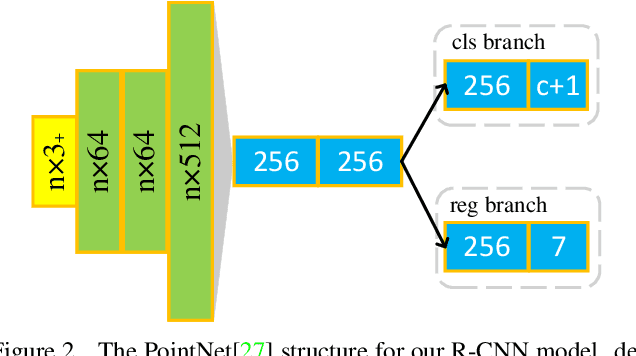
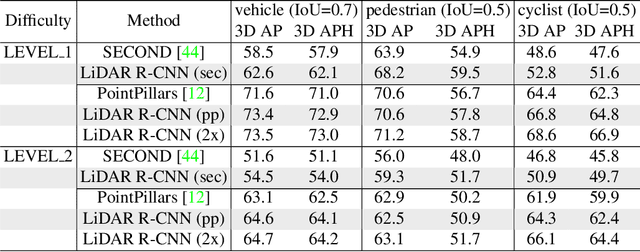
LiDAR-based 3D detection in point cloud is essential in the perception system of autonomous driving. In this paper, we present LiDAR R-CNN, a second stage detector that can generally improve any existing 3D detector. To fulfill the real-time and high precision requirement in practice, we resort to point-based approach other than the popular voxel-based approach. However, we find an overlooked issue in previous work: Naively applying point-based methods like PointNet could make the learned features ignore the size of proposals. To this end, we analyze this problem in detail and propose several methods to remedy it, which bring significant performance improvement. Comprehensive experimental results on real-world datasets like Waymo Open Dataset (WOD) and KITTI dataset with various popular detectors demonstrate the universality and superiority of our LiDAR R-CNN. In particular, based on one variant of PointPillars, our method could achieve new state-of-the-art results with minor cost. Codes will be released at https://github.com/tusimple/LiDAR_RCNN .
Model-free Vehicle Tracking and State Estimation in Point Cloud Sequences
Mar 10, 2021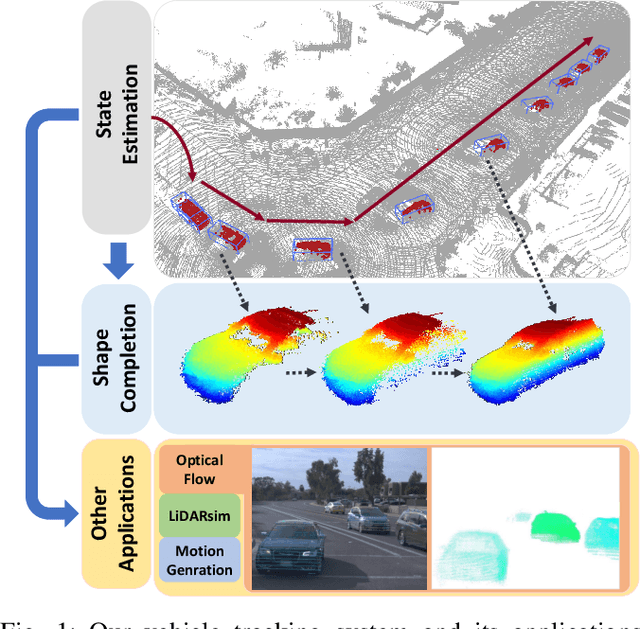
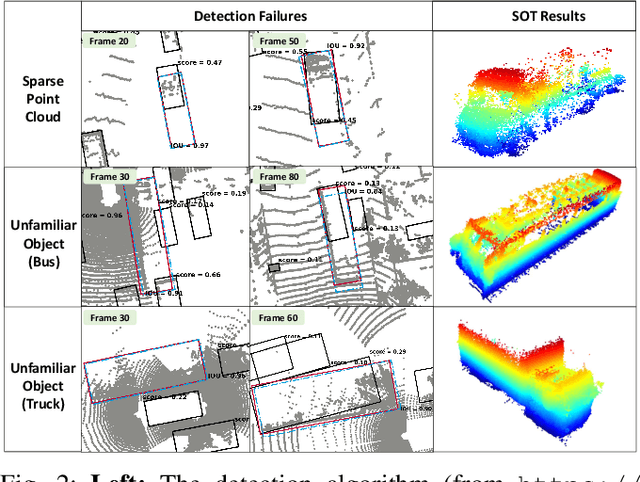
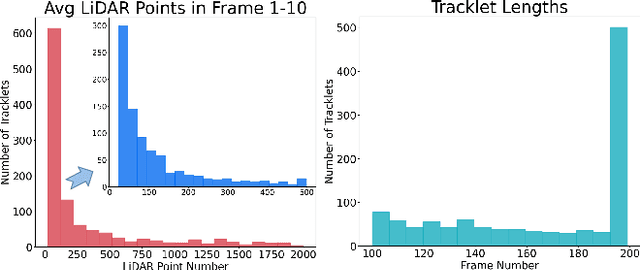
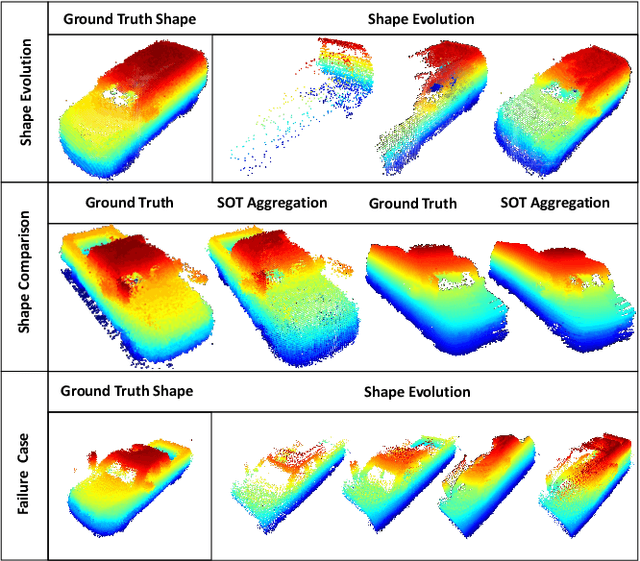
Estimating the states of surrounding traffic participants stays at the core of autonomous driving. In this paper, we study a novel setting of this problem: model-free single object tracking (SOT), which takes the object state in the first frame as input, and jointly solves state estimation and tracking in subsequent frames. The main purpose for this new setting is to break the strong limitation of the popular "detection and tracking" scheme in multi-object tracking. Moreover, we notice that shape completion by overlaying the point clouds, which is a by-product of our proposed task, not only improves the performance of state estimation but also has numerous applications. As no benchmark for this task is available so far, we construct a new dataset LiDAR-SOT and corresponding evaluation protocols based on the Waymo Open dataset. We then propose an optimization-based algorithm called SOTracker based on point cloud registration, vehicle shapes, and motion priors. Our quantitative and qualitative results prove the effectiveness of our SOTracker and reveal the challenging cases for SOT in point clouds, including the sparsity of LiDAR data, abrupt motion variation, etc. Finally, we also explore how the proposed task and algorithm may benefit other autonomous driving applications, including simulating LiDAR scans, generating motion data, and annotating optical flow. The code and protocols for our benchmark and algorithm are available at https://github.com/TuSimple/LiDAR_SOT/ . A video demonstration is at https://www.youtube.com/watch?v=BpHixKs91i8 .
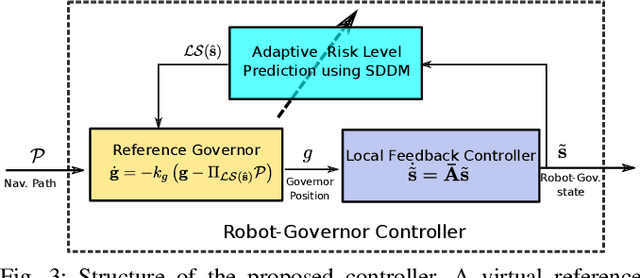
Safe Robot Navigation in Cluttered Environments using Invariant Ellipsoids and a Reference Governor
May 14, 2020
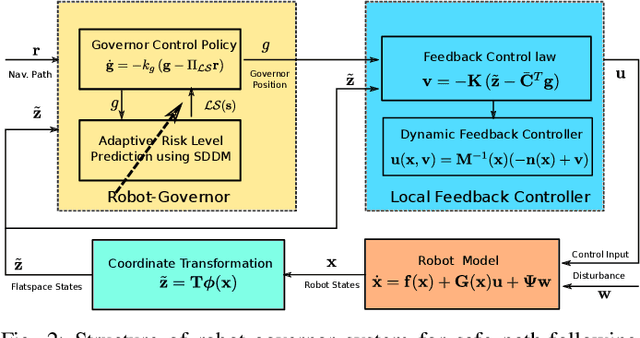
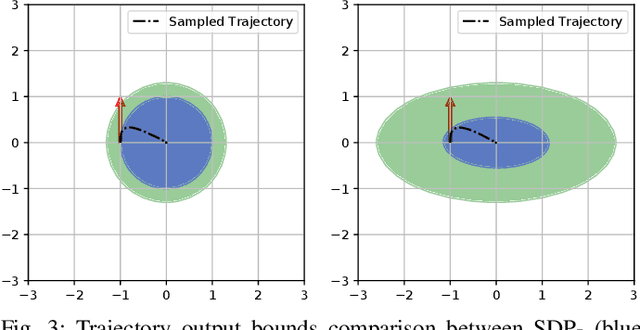
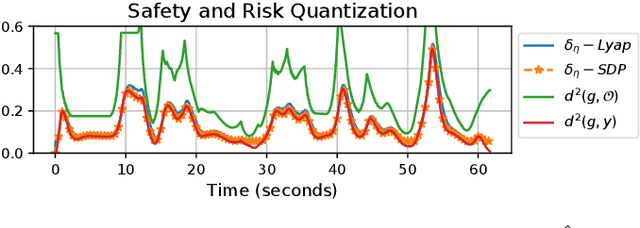
This paper considers the problem of safe autonomous navigation in unknown environments, relying on local obstacle sensing. We consider a control-affine nonlinear robot system subject to bounded input noise and rely on feedback linearization to determine ellipsoid output bounds on the closed-loop robot trajectory under stabilizing control. A virtual governor system is developed to adaptively track a desired navigation path, while relying on the robot trajectory bounds to slow down if safety is endangered and speed up otherwise. The main contribution is the derivation of theoretical guarantees for safe nonlinear system path-following control and its application to autonomous robot navigation in unknown environments.
DMLO: Deep Matching LiDAR Odometry
Apr 09, 2020
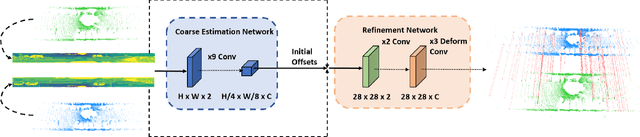
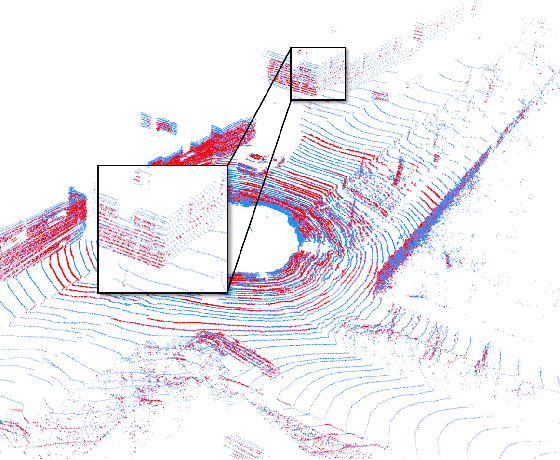

LiDAR odometry is a fundamental task for various areas such as robotics, autonomous driving. This problem is difficult since it requires the systems to be highly robust running in noisy real-world data. Existing methods are mostly local iterative methods. Feature-based global registration methods are not preferred since extracting accurate matching pairs in the nonuniform and sparse LiDAR data remains challenging. In this paper, we present Deep Matching LiDAR Odometry (DMLO), a novel learning-based framework which makes the feature matching method applicable to LiDAR odometry task. Unlike many recent learning-based methods, DMLO explicitly enforces geometry constraints in the framework. Specifically, DMLO decomposes the 6-DoF pose estimation into two parts, a learning-based matching network which provides accurate correspondences between two scans and rigid transformation estimation with a close-formed solution by Singular Value Decomposition (SVD). Comprehensive experimental results on real-world datasets KITTI and Argoverse demonstrate that our DMLO dramatically outperforms existing learning-based methods and comparable with the state-of-the-art geometry based approaches.
Fast and Safe Path-Following Control using a State-Dependent Directional Metric
Feb 25, 2020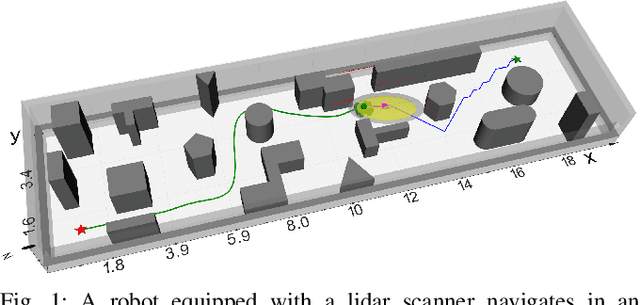
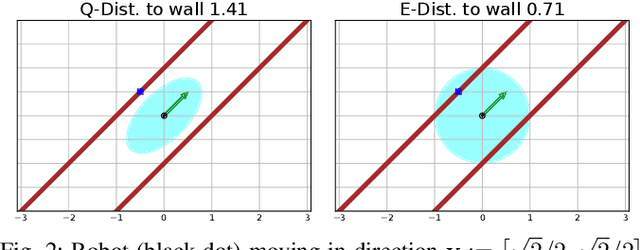
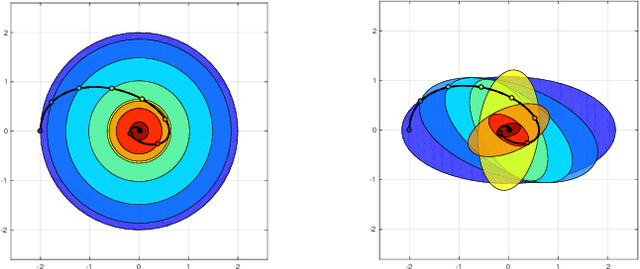
This paper considers the problem of fast and safe autonomous navigation in partially known environments. Our main contribution is a control policy design based on ellipsoidal trajectory bounds obtained from a quadratic state-dependent distance metric. The ellipsoidal bounds are used to embed directional preference in the control design, leading to system behavior that is adapted to the local environment geometry, carefully considering medial obstacles while paying less attention to lateral ones. We use a virtual reference governor system to adaptively follow a desired navigation path, slowing down when system safety may be violated and speeding up otherwise. The resulting controller is able to navigate complex environments faster than common Euclidean-norm and Lyapunov-function-based designs, while retaining stability and collision avoidance guarantees.
Unsupervised Scale-consistent Depth and Ego-motion Learning from Monocular Video
Oct 03, 2019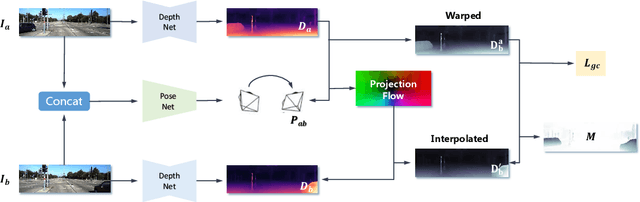



Recent work has shown that CNN-based depth and ego-motion estimators can be learned using unlabelled monocular videos. However, the performance is limited by unidentified moving objects that violate the underlying static scene assumption in geometric image reconstruction. More significantly, due to lack of proper constraints, networks output scale-inconsistent results over different samples, i.e., the ego-motion network cannot provide full camera trajectories over a long video sequence because of the per-frame scale ambiguity. This paper tackles these challenges by proposing a geometry consistency loss for scale-consistent predictions and an induced self-discovered mask for handling moving objects and occlusions. Since we do not leverage multi-task learning like recent works, our framework is much simpler and more efficient. Comprehensive evaluation results demonstrate that our depth estimator achieves the state-of-the-art performance on the KITTI dataset. Moreover, we show that our ego-motion network is able to predict a globally scale-consistent camera trajectory for long video sequences, and the resulting visual odometry accuracy is competitive with the recent model that is trained using stereo videos. To the best of our knowledge, this is the first work to show that deep networks trained using unlabelled monocular videos can predict globally scale-consistent camera trajectories over a long video sequence.