 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence Enables Real-Time and Intuitive Control of Prostheses via Nerve Interface
Mar 16, 2022
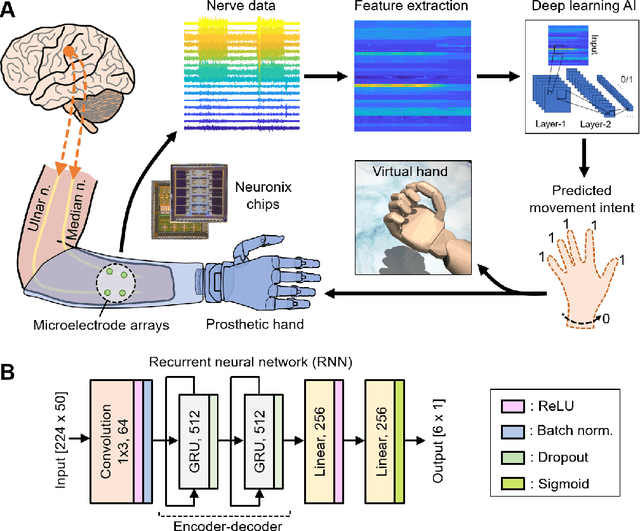
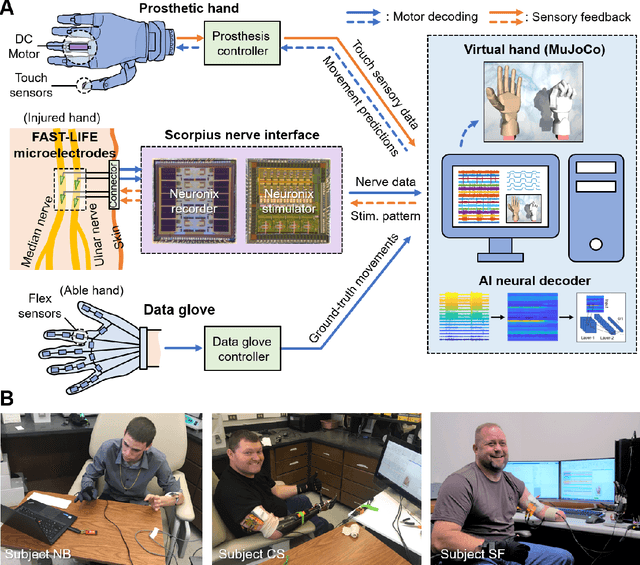
Objective: The next generation prosthetic hand that moves and feels like a real hand requires a robust neural interconnection between the human minds and machines. Methods: Here we present a neuroprosthetic system to demonstrate that principle by employing an artificial intelligence (AI) agent to translate the amputee's movement intent through a peripheral nerve interface. The AI agent is designed based on the recurrent neural network (RNN) and could simultaneously decode six degree-of-freedom (DOF) from multichannel nerve data in real-time. The decoder's performance is characterized in motor decoding experiments with three human amputees. Results: First, we show the AI agent enables amputees to intuitively control a prosthetic hand with individual finger and wrist movements up to 97-98% accuracy. Second, we demonstrate the AI agent's real-time performance by measuring the reaction time and information throughput in a hand gesture matching task. Third, we investigate the AI agent's long-term uses and show the decoder's robust predictive performance over a 16-month implant duration. Conclusion & significance: Our study demonstrates the potential of AI-enabled nerve technology, underling the next generation of dexterous and intuitive prosthetic hands.
Information Gain Propagation: a new way to Graph Active Learning with Soft Labels
Mar 02, 2022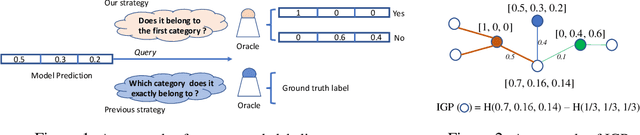
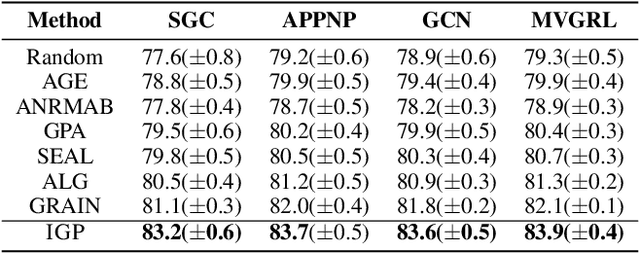
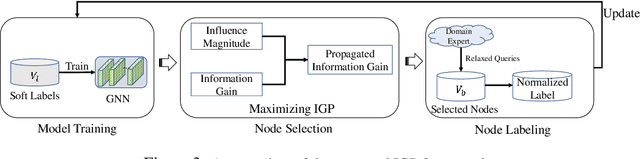
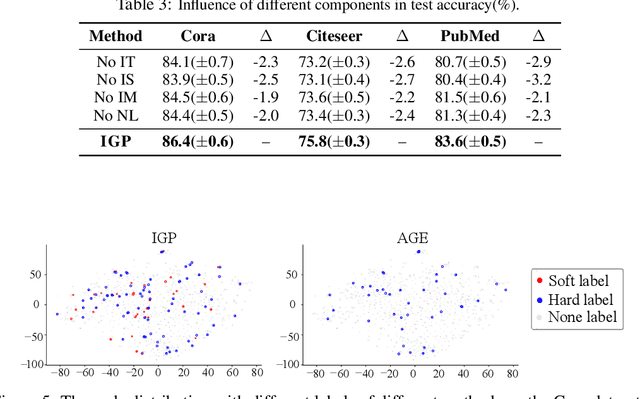
Graph Neural Networks (GNNs) have achieved great success in various tasks, but their performance highly relies on a large number of labeled nodes, which typically requires considerable human effort. GNN-based Active Learning (AL) methods are proposed to improve the labeling efficiency by selecting the most valuable nodes to label. Existing methods assume an oracle can correctly categorize all the selected nodes and thus just focus on the node selection. However, such an exact labeling task is costly, especially when the categorization is out of the domain of individual expert (oracle). The paper goes further, presenting a soft-label approach to AL on GNNs. Our key innovations are: i) relaxed queries where a domain expert (oracle) only judges the correctness of the predicted labels (a binary question) rather than identifying the exact class (a multi-class question), and ii) new criteria of maximizing information gain propagation for active learner with relaxed queries and soft labels. Empirical studies on public datasets demonstrate that our method significantly outperforms the state-of-the-art GNN-based AL methods in terms of both accuracy and labeling cost.
* 17 pages, 7 figures
PaSca: a Graph Neural Architecture Search System under the Scalable Paradigm
Mar 01, 2022
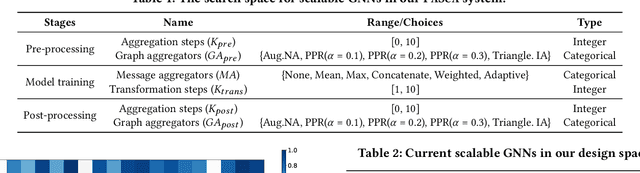
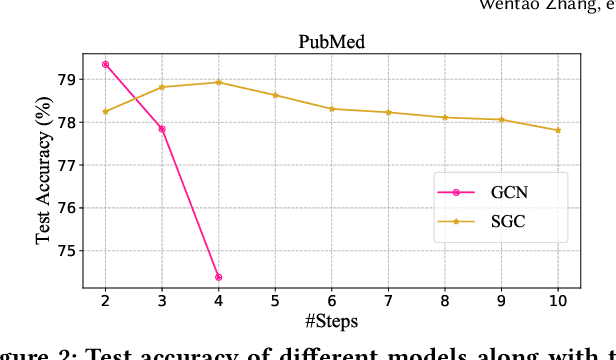

Graph neural networks (GNNs) have achieved state-of-the-art performance in various graph-based tasks. However, as mainstream GNNs are designed based on the neural message passing mechanism, they do not scale well to data size and message passing steps. Although there has been an emerging interest in the design of scalable GNNs, current researches focus on specific GNN design, rather than the general design space, limiting the discovery of potential scalable GNN models. This paper proposes PasCa, a new paradigm and system that offers a principled approach to systemically construct and explore the design space for scalable GNNs, rather than studying individual designs. Through deconstructing the message passing mechanism, PasCa presents a novel Scalable Graph Neural Architecture Paradigm (SGAP), together with a general architecture design space consisting of 150k different designs. Following the paradigm, we implement an auto-search engine that can automatically search well-performing and scalable GNN architectures to balance the trade-off between multiple criteria (e.g., accuracy and efficiency) via multi-objective optimization. Empirical studies on ten benchmark datasets demonstrate that the representative instances (i.e., PasCa-V1, V2, and V3) discovered by our system achieve consistent performance among competitive baselines. Concretely, PasCa-V3 outperforms the state-of-the-art GNN method JK-Net by 0.4\% in terms of predictive accuracy on our large industry dataset while achieving up to $28.3\times$ training speedups.
* 13 pages, 8 figures. arXiv admin note: text overlap with arXiv:2104.09880
Dense-to-Sparse Gate for Mixture-of-Experts
Dec 29, 2021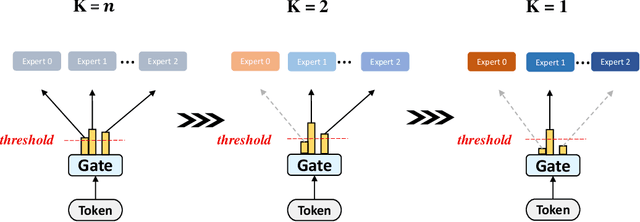

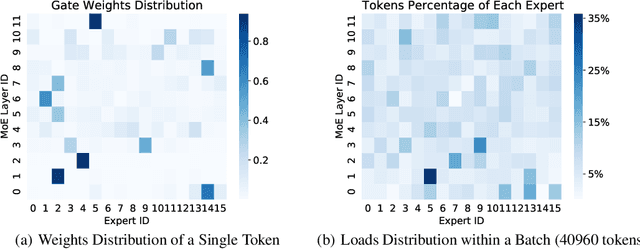
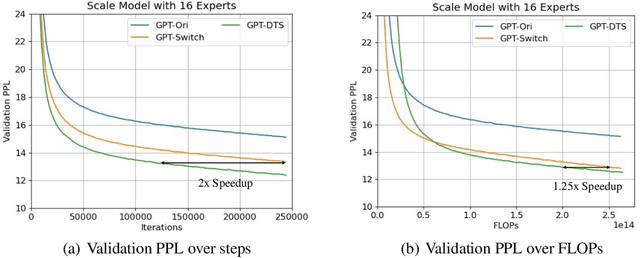
Mixture-of-experts (MoE) is becoming popular due to its success in improving the model quality, especially in Transformers. By routing tokens with a sparse gate to a few experts that each only contains part of the full model, MoE keeps the model size unchanged and significantly reduces per-token computation, which effectively scales neural networks. However, we found that the current approach of jointly training experts and the sparse gate introduces a negative impact on model accuracy, diminishing the efficiency of expensive large-scale model training. In this work, we proposed Dense-To-Sparse gate (DTS-Gate) for MoE training. Specifically, instead of using a permanent sparse gate, DTS-Gate begins as a dense gate that routes tokens to all experts, then gradually and adaptively becomes sparser while routes to fewer experts. MoE with DTS-Gate naturally decouples the training of experts and the sparse gate by training all experts at first and then learning the sparse gate. Experiments show that compared with the state-of-the-art Switch-Gate in GPT-MoE(1.5B) model with OpenWebText dataset(40GB), DTS-Gate can obtain 2.0x speed-up to reach the same validation perplexity, as well as higher FLOPs-efficiency of a 1.42x speed-up.
Feature extraction and classification algorithm, which one is more essential? An experimental study on a specific task of vibration signal diagnosis
Dec 17, 2021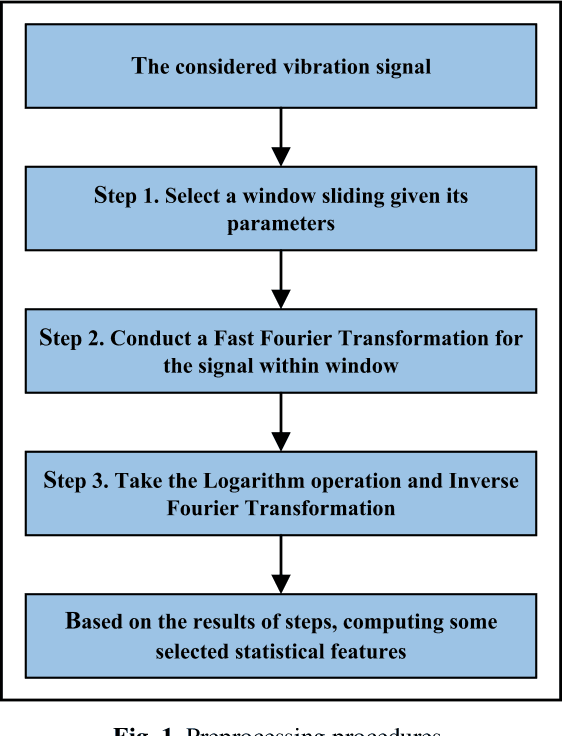

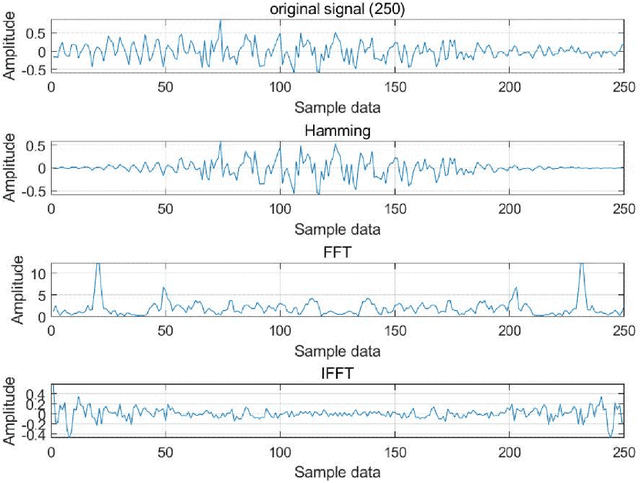

With the development of machine learning, a data-driven model has been widely used in vibration signal fault diagnosis. Most data-driven machine learning algorithms are built based on well-designed features, but feature extraction is usually required to be completed in advance. In the deep learning era, feature extraction and classifier learning are conducted simultaneously, which will lead to an end-to-end learning system. This paper explores which one of the two key factors, i.e., feature extraction and classification algorithm, is more essential for a specific task of vibration signal diagnosis during a learning system is generated. Feature extractions from vibration signal based on both well-known Gaussian model and statistical characteristics are discussed, respectively. And several classification algorithms are selected to experimentally validate the comparative impact of both feature extraction and classification algorithm on prediction performance.
HET: Scaling out Huge Embedding Model Training via Cache-enabled Distributed Framework
Dec 14, 2021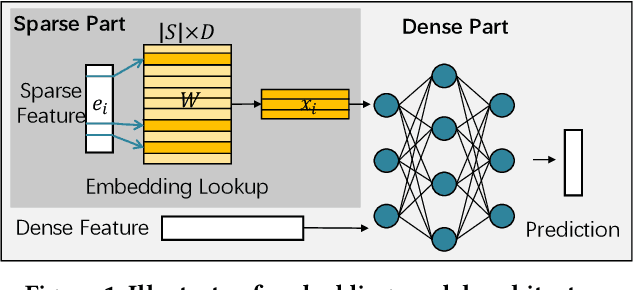
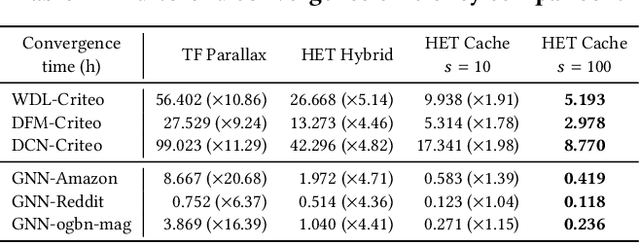
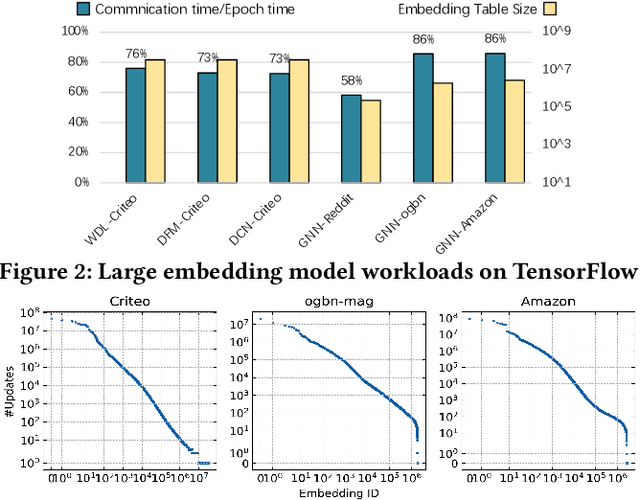
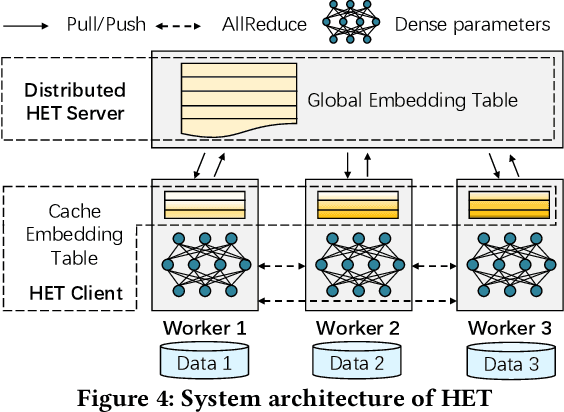
Embedding models have been an effective learning paradigm for high-dimensional data. However, one open issue of embedding models is that their representations (latent factors) often result in large parameter space. We observe that existing distributed training frameworks face a scalability issue of embedding models since updating and retrieving the shared embedding parameters from servers usually dominates the training cycle. In this paper, we propose HET, a new system framework that significantly improves the scalability of huge embedding model training. We embrace skewed popularity distributions of embeddings as a performance opportunity and leverage it to address the communication bottleneck with an embedding cache. To ensure consistency across the caches, we incorporate a new consistency model into HET design, which provides fine-grained consistency guarantees on a per-embedding basis. Compared to previous work that only allows staleness for read operations, HET also utilizes staleness for write operations. Evaluations on six representative tasks show that HET achieves up to 88% embedding communication reductions and up to 20.68x performance speedup over the state-of-the-art baselines.
RIM: Reliable Influence-based Active Learning on Graphs
Oct 28, 2021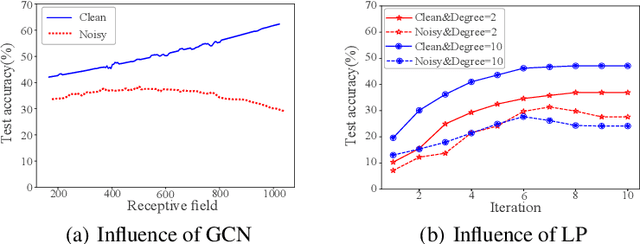
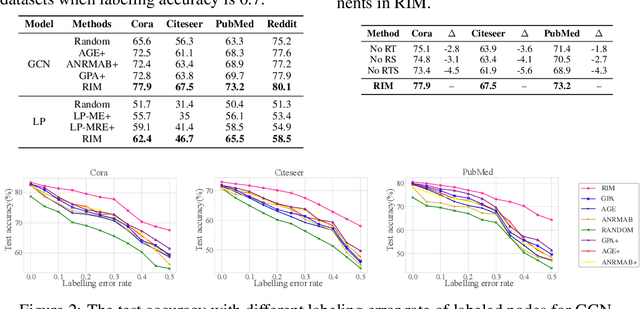
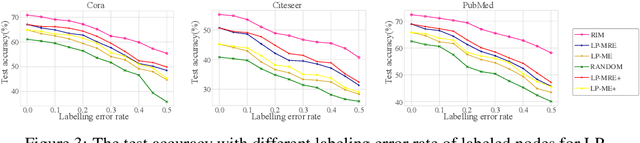

Message passing is the core of most graph models such as Graph Convolutional Network (GCN) and Label Propagation (LP), which usually require a large number of clean labeled data to smooth out the neighborhood over the graph. However, the labeling process can be tedious, costly, and error-prone in practice. In this paper, we propose to unify active learning (AL) and message passing towards minimizing labeling costs, e.g., making use of few and unreliable labels that can be obtained cheaply. We make two contributions towards that end. First, we open up a perspective by drawing a connection between AL enforcing message passing and social influence maximization, ensuring that the selected samples effectively improve the model performance. Second, we propose an extension to the influence model that incorporates an explicit quality factor to model label noise. In this way, we derive a fundamentally new AL selection criterion for GCN and LP--reliable influence maximization (RIM)--by considering quantity and quality of influence simultaneously. Empirical studies on public datasets show that RIM significantly outperforms current AL methods in terms of accuracy and efficiency.
Node Dependent Local Smoothing for Scalable Graph Learning
Oct 27, 2021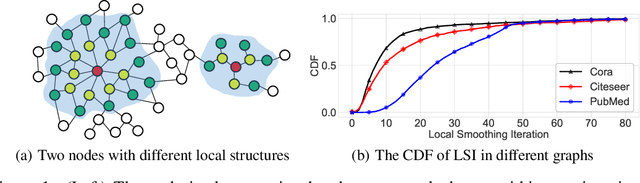

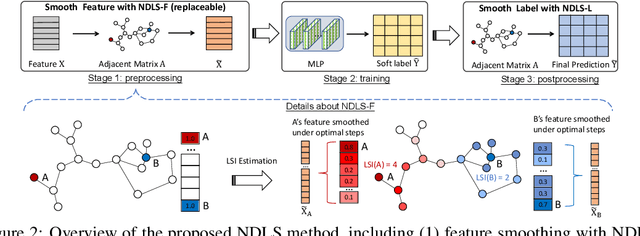
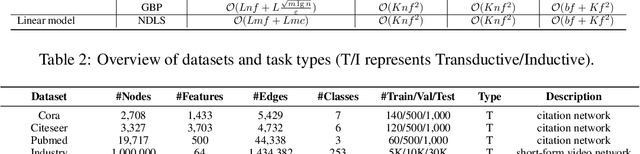
Recent works reveal that feature or label smoothing lies at the core of Graph Neural Networks (GNNs). Concretely, they show feature smoothing combined with simple linear regression achieves comparable performance with the carefully designed GNNs, and a simple MLP model with label smoothing of its prediction can outperform the vanilla GCN. Though an interesting finding, smoothing has not been well understood, especially regarding how to control the extent of smoothness. Intuitively, too small or too large smoothing iterations may cause under-smoothing or over-smoothing and can lead to sub-optimal performance. Moreover, the extent of smoothness is node-specific, depending on its degree and local structure. To this end, we propose a novel algorithm called node-dependent local smoothing (NDLS), which aims to control the smoothness of every node by setting a node-specific smoothing iteration. Specifically, NDLS computes influence scores based on the adjacency matrix and selects the iteration number by setting a threshold on the scores. Once selected, the iteration number can be applied to both feature smoothing and label smoothing. Experimental results demonstrate that NDLS enjoys high accuracy -- state-of-the-art performance on node classifications tasks, flexibility -- can be incorporated with any models, scalability and efficiency -- can support large scale graphs with fast training.
* 19 pages, 5 figures
Graph Attention Multi-Layer Perceptron
Sep 09, 2021

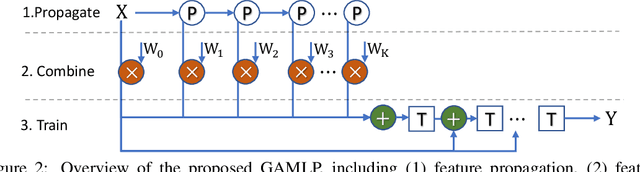
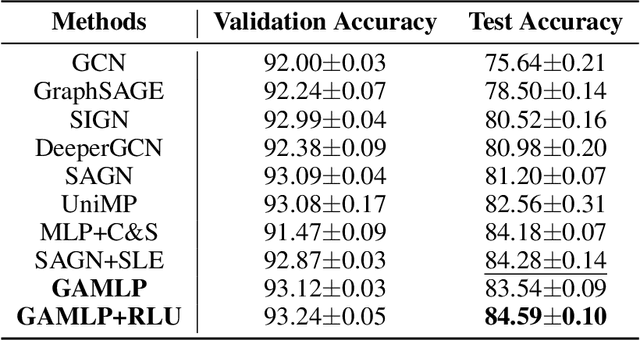
Graph neural networks (GNNs) have recently achieved state-of-the-art performance in many graph-based applications. Despite the high expressive power, they typically need to perform an expensive recursive neighborhood expansion in multiple training epochs and face a scalability issue. Moreover, most of them are inflexible since they are restricted to fixed-hop neighborhoods and insensitive to actual receptive field demands for different nodes. We circumvent these limitations by introducing a scalable and flexible Graph Attention Multilayer Perceptron (GAMLP). With the separation of the non-linear transformation and feature propagation, GAMLP significantly improves the scalability and efficiency by performing the propagation procedure in a pre-compute manner. With three principled receptive field attention, each node in GAMLP is flexible and adaptive in leveraging the propagated features over the different sizes of reception field. We conduct extensive evaluations on the three large open graph benchmarks (e.g., ogbn-papers100M, ogbn-products and ogbn-mag), demonstrating that GAMLP not only achieves the state-of-art performance, but also additionally provide high scalability and efficiency.
Improving Ranking Correlation of Supernet with Candidates Enhancement and Progressive Training
Aug 12, 2021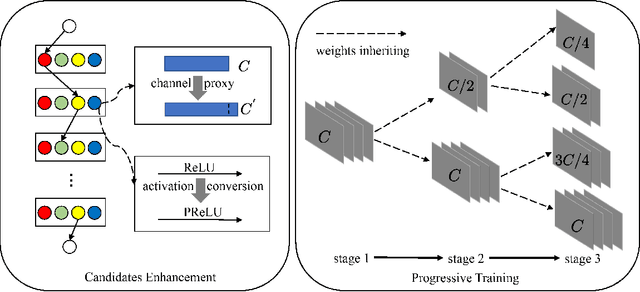
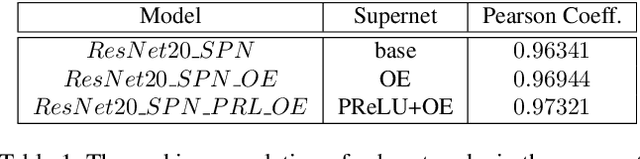
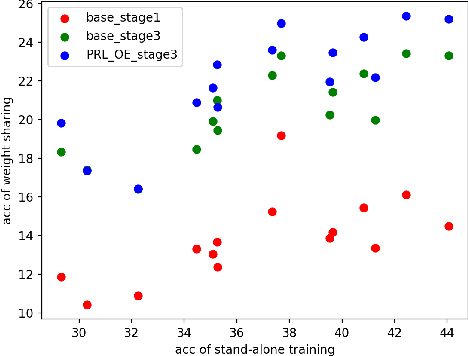
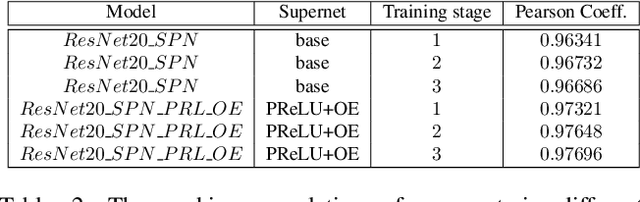
One-shot neural architecture search (NAS) applies weight-sharing supernet to reduce the unaffordable computation overhead of automated architecture designing. However, the weight-sharing technique worsens the ranking consistency of performance due to the interferences between different candidate networks. To address this issue, we propose a candidates enhancement method and progressive training pipeline to improve the ranking correlation of supernet. Specifically, we carefully redesign the sub-networks in the supernet and map the original supernet to a new one of high capacity. In addition, we gradually add narrow branches of supernet to reduce the degree of weight sharing which effectively alleviates the mutual interference between sub-networks. Finally, our method ranks the 1st place in the Supernet Track of CVPR2021 1st Lightweight NAS Challenge.