 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCBNetV2: A Composite Backbone Network Architecture for Object Detection
Jul 29, 2021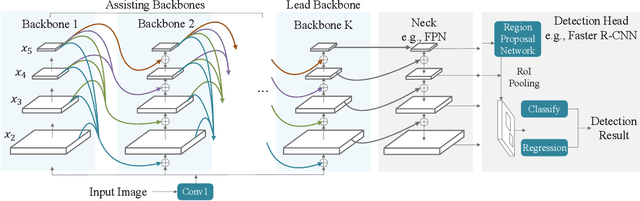
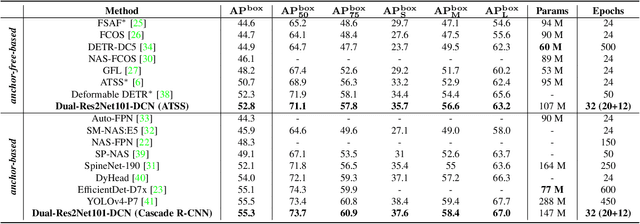
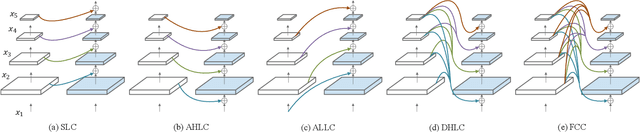
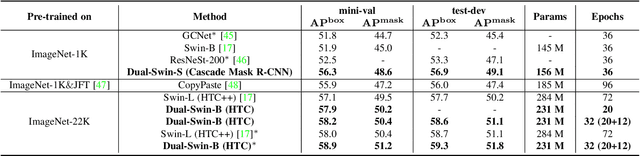
Modern top-performing object detectors depend heavily on backbone networks, whose advances bring consistent performance gains through exploring more effective network structures. In this paper, we propose a novel and flexible backbone framework, namely CBNetV2, to construct high-performance detectors using existing open-sourced pre-trained backbones under the pre-training fine-tuning paradigm. In particular, CBNetV2 architecture groups multiple identical backbones, which are connected through composite connections. Specifically, it integrates the high- and low-level features of multiple backbone networks and gradually expands the receptive field to more efficiently perform object detection. We also propose a better training strategy with assistant supervision for CBNet-based detectors. Without additional pre-training of the composite backbone, CBNetV2 can be adapted to various backbones (CNN-based vs. Transformer-based) and head designs of most mainstream detectors (one-stage vs. two-stage, anchor-based vs. anchor-free-based). Experiments provide strong evidence that, compared with simply increasing the depth and width of the network, CBNetV2 introduces a more efficient, effective, and resource-friendly way to build high-performance backbone networks. Particularly, our Dual-Swin-L achieves 59.4% box AP and 51.6% mask AP on COCO test-dev under the single-model and single-scale testing protocol, which is significantly better than the state-of-the-art result (57.7% box AP and 50.2% mask AP) achieved by Swin-L, while the training schedule is reduced by 6$\times$. With multi-scale testing, we push the current best single model result to a new record of 60.1% box AP and 52.3% mask AP without using extra training data. Code is available at https://github.com/VDIGPKU/CBNetV2.
CMUA-Watermark: A Cross-Model Universal Adversarial Watermark for Combating Deepfakes
May 23, 2021

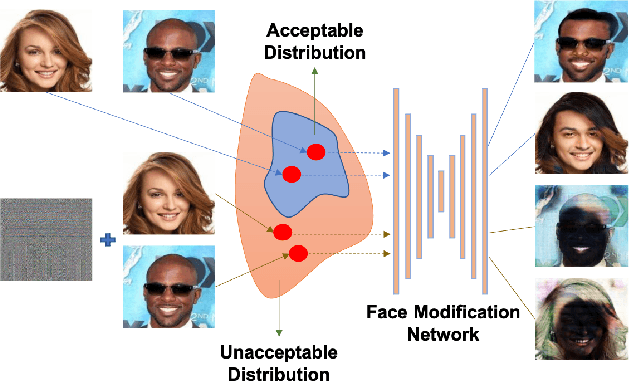

Malicious application of deepfakes (i.e., technologies can generate target faces or face attributes) has posed a huge threat to our society. The fake multimedia content generated by deepfake models can harm the reputation and even threaten the property of the person who has been impersonated. Fortunately, the adversarial watermark could be used for combating deepfake models, leading them to generate distorted images. The existing methods require an individual training process for every facial image, to generate the adversarial watermark against a specific deepfake model, which are extremely inefficient. To address this problem, we propose a universal adversarial attack method on deepfake models, to generate a Cross-Model Universal Adversarial Watermark (CMUA-Watermark) that can protect thousands of facial images from multiple deepfake models. Specifically, we first propose a cross-model universal attack pipeline by attacking multiple deepfake models and combining gradients from these models iteratively. Then we introduce a batch-based method to alleviate the conflict of adversarial watermarks generated by different facial images. Finally, we design a more reasonable and comprehensive evaluation method for evaluating the effectiveness of the adversarial watermark. Experimental results demonstrate that the proposed CMUA-Watermark can effectively distort the fake facial images generated by deepfake models and successfully protect facial images from deepfakes in real scenes.
MathBERT: A Pre-Trained Model for Mathematical Formula Understanding
May 02, 2021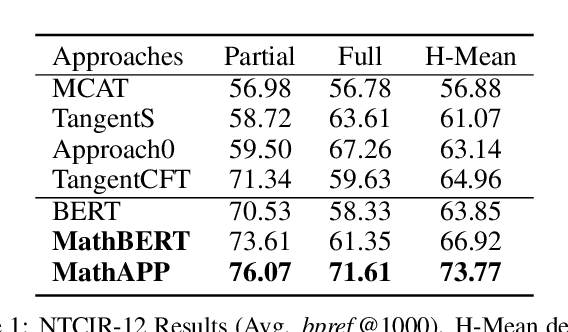
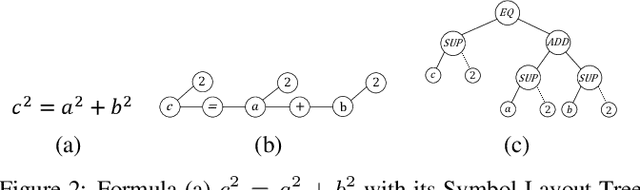
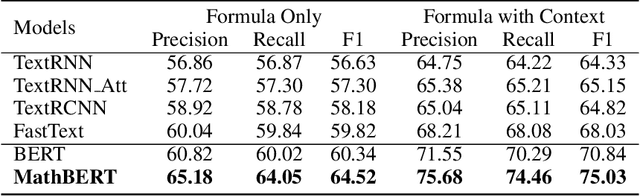
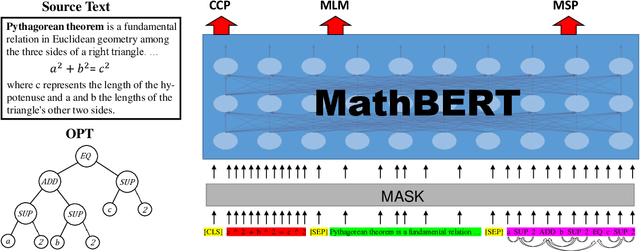
Large-scale pre-trained models like BERT, have obtained a great success in various Natural Language Processing (NLP) tasks, while it is still a challenge to adapt them to the math-related tasks. Current pre-trained models neglect the structural features and the semantic correspondence between formula and its context. To address these issues, we propose a novel pre-trained model, namely \textbf{MathBERT}, which is jointly trained with mathematical formulas and their corresponding contexts. In addition, in order to further capture the semantic-level structural features of formulas, a new pre-training task is designed to predict the masked formula substructures extracted from the Operator Tree (OPT), which is the semantic structural representation of formulas. We conduct various experiments on three downstream tasks to evaluate the performance of MathBERT, including mathematical information retrieval, formula topic classification and formula headline generation. Experimental results demonstrate that MathBERT significantly outperforms existing methods on all those three tasks. Moreover, we qualitatively show that this pre-trained model effectively captures the semantic-level structural information of formulas. To the best of our knowledge, MathBERT is the first pre-trained model for mathematical formula understanding.
Automatic Description Construction for Math Expression via Topic Relation Graph
Apr 24, 2021
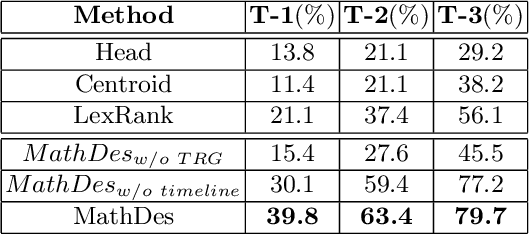
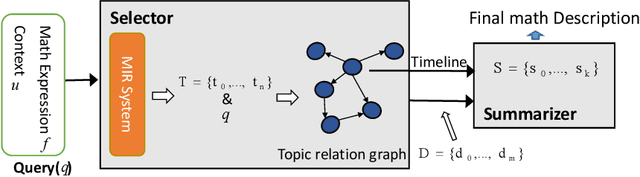
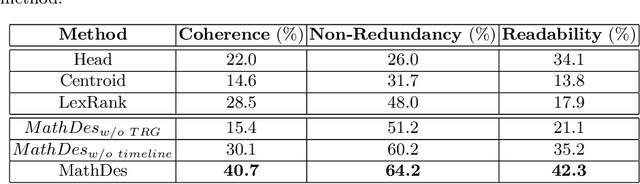
Math expressions are important parts of scientific and educational documents, but some of them may be challenging for junior scholars or students to understand. Nevertheless, constructing textual descriptions for math expressions is nontrivial. In this paper, we explore the feasibility to automatically construct descriptions for math expressions. But there are two challenges that need to be addressed: 1) finding relevant documents since a math equation understanding usually requires several topics, but these topics are often explained in different documents. 2) the sparsity of the collected relevant documents making it difficult to extract reasonable descriptions. Different documents mainly focus on different topics which makes model hard to extract salient information and organize them to form a description of math expressions. To address these issues, we propose a hybrid model (MathDes) which contains two important modules: Selector and Summarizer. In the Selector, a Topic Relation Graph (TRG) is proposed to obtain the relevant documents which contain the comprehensive information of math expressions. TRG is a graph built according to the citations between expressions. In the Summarizer, a summarization model under the Integer Linear Programming (ILP) framework is proposed. This module constructs the final description with the help of a timeline that is extracted from TRG. The experimental results demonstrate that our methods are promising for this task and outperform the baselines in all aspects.
Community-based Cyberreading for Information Understanding
Mar 27, 2021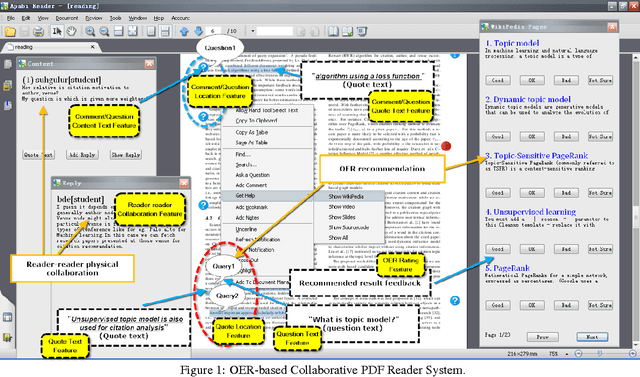
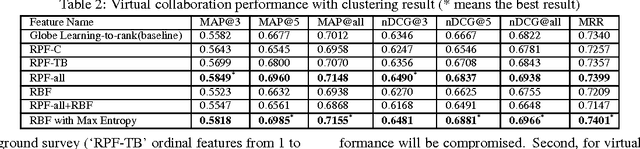
Although the content in scientific publications is increasingly challenging, it is necessary to investigate another important problem, that of scientific information understanding. For this proposed problem, we investigate novel methods to assist scholars (readers) to better understand scientific publications by enabling physical and virtual collaboration. For physical collaboration, an algorithm will group readers together based on their profiles and reading behavior, and will enable the cyberreading collaboration within a online reading group. For virtual collaboration, instead of pushing readers to communicate with others, we cluster readers based on their estimated information needs. For each cluster, a learning to rank model will be generated to recommend readers' communitized resources (i.e., videos, slides, and wikis) to help them understand the target publication.
RPATTACK: Refined Patch Attack on General Object Detectors
Mar 23, 2021

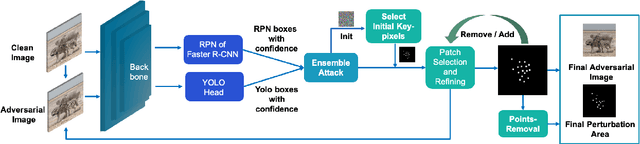

Nowadays, general object detectors like YOLO and Faster R-CNN as well as their variants are widely exploited in many applications. Many works have revealed that these detectors are extremely vulnerable to adversarial patch attacks. The perturbed regions generated by previous patch-based attack works on object detectors are very large which are not necessary for attacking and perceptible for human eyes. To generate much less but more efficient perturbation, we propose a novel patch-based method for attacking general object detectors. Firstly, we propose a patch selection and refining scheme to find the pixels which have the greatest importance for attack and remove the inconsequential perturbations gradually. Then, for a stable ensemble attack, we balance the gradients of detectors to avoid over-optimizing one of them during the training phase. Our RPAttack can achieve an amazing missed detection rate of 100% for both Yolo v4 and Faster R-CNN while only modifies 0.32% pixels on VOC 2007 test set. Our code is available at https://github.com/VDIGPKU/RPAttack.
OPANAS: One-Shot Path Aggregation Network Architecture Search for Object Detection
Mar 11, 2021



Recently, neural architecture search (NAS) has been exploited to design feature pyramid networks (FPNs) and achieved promising results for visual object detection. Encouraged by the success, we propose a novel One-Shot Path Aggregation Network Architecture Search (OPANAS) algorithm, which significantly improves both searching efficiency and detection accuracy. Specifically, we first introduce six heterogeneous information paths to build our search space, namely top-down, bottom-up, fusing-splitting, scale-equalizing, skip-connect and none. Second, we propose a novel search space of FPNs, in which each FPN candidate is represented by a densely-connected directed acyclic graph (each node is a feature pyramid and each edge is one of the six heterogeneous information paths). Third, we propose an efficient one-shot search method to find the optimal path aggregation architecture, that is, we first train a super-net and then find the optimal candidate with an evolutionary algorithm. Experimental results demonstrate the efficacy of the proposed OPANAS for object detection: (1) OPANAS is more efficient than state-of-the-art methods (e.g., NAS-FPN and Auto-FPN), at significantly smaller searching cost (e.g., only 4 GPU days on MS-COCO); (2) the optimal architecture found by OPANAS significantly improves main-stream detectors including RetinaNet, Faster R-CNN and Cascade R-CNN, by 2.3-3.2 % mAP comparing to their FPN counterparts; and (3) a new state-of-the-art accuracy-speed trade-off (52.2 % mAP at 7.6 FPS) at smaller training costs than comparable state-of-the-arts. Code will be released at https://github.com/VDIGPKU/OPANAS.
Persistence Homology for Link Prediction: An Interactive View
Feb 20, 2021
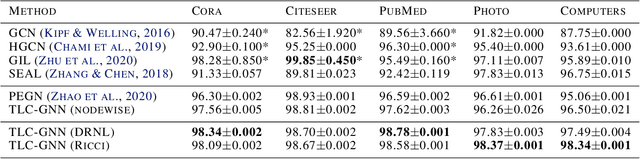
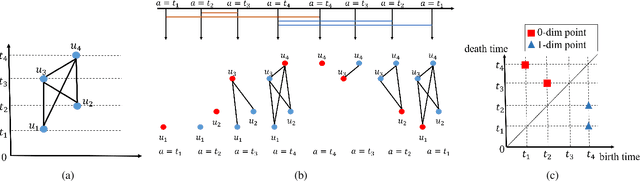
Link prediction is an important learning task for graph-structured data. In this paper, we propose a novel topological approach to characterize interactions between two nodes. Our topological feature, based on the extended persistence homology, encodes rich structural information regarding the multi-hop paths connecting nodes. Based on this feature, we propose a graph neural network method that outperforms state-of-the-arts on different benchmarks. As another contribution, we propose a novel algorithm to more efficiently compute the extended persistent diagrams for graphs. This algorithm can be generally applied to accelerate many other topological methods for graph learning tasks.
ConvMath: A Convolutional Sequence Network for Mathematical Expression Recognition
Dec 23, 2020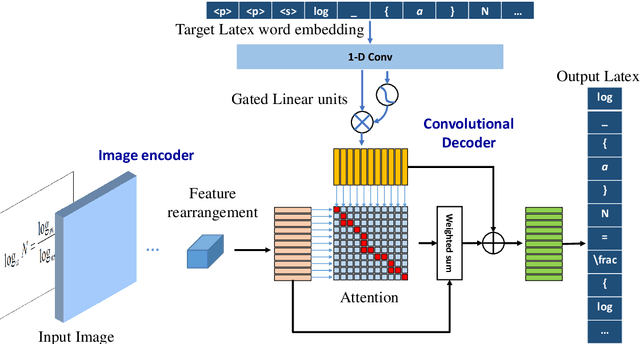
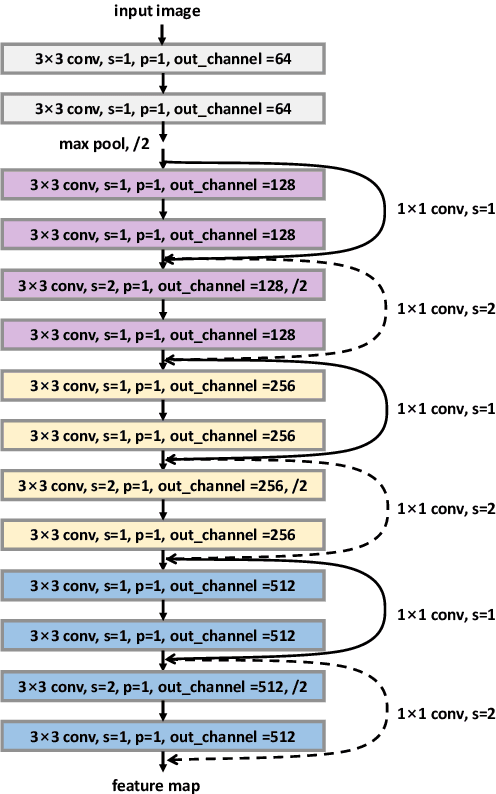
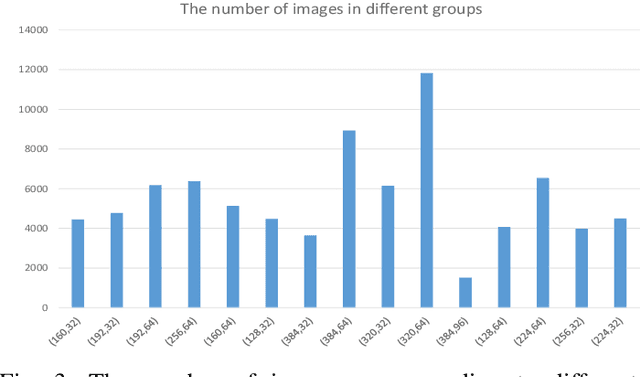

Despite the recent advances in optical character recognition (OCR), mathematical expressions still face a great challenge to recognize due to their two-dimensional graphical layout. In this paper, we propose a convolutional sequence modeling network, ConvMath, which converts the mathematical expression description in an image into a LaTeX sequence in an end-to-end way. The network combines an image encoder for feature extraction and a convolutional decoder for sequence generation. Compared with other Long Short Term Memory(LSTM) based encoder-decoder models, ConvMath is entirely based on convolution, thus it is easy to perform parallel computation. Besides, the network adopts multi-layer attention mechanism in the decoder, which allows the model to align output symbols with source feature vectors automatically, and alleviates the problem of lacking coverage while training the model. The performance of ConvMath is evaluated on an open dataset named IM2LATEX-100K, including 103556 samples. The experimental results demonstrate that the proposed network achieves state-of-the-art accuracy and much better efficiency than previous methods.
GSTO: Gated Scale-Transfer Operation for Multi-Scale Feature Learning in Pixel Labeling
Jun 28, 2020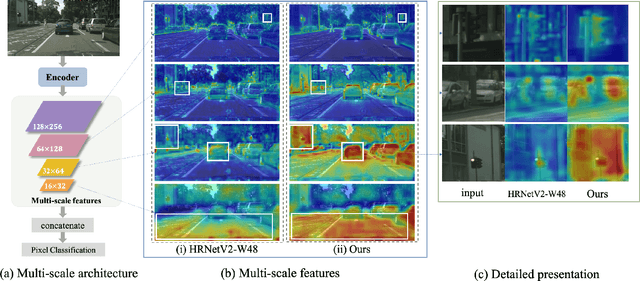
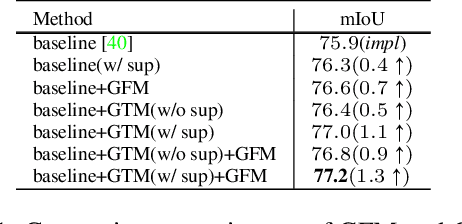
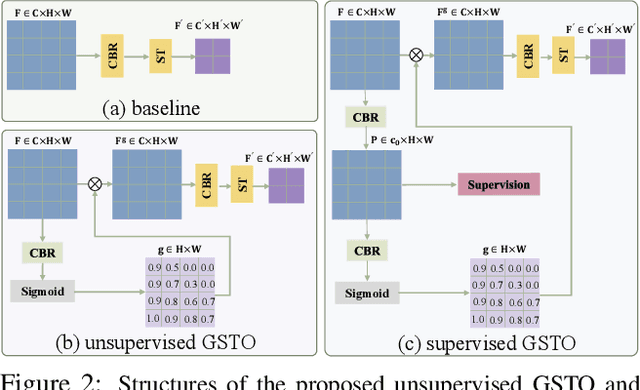
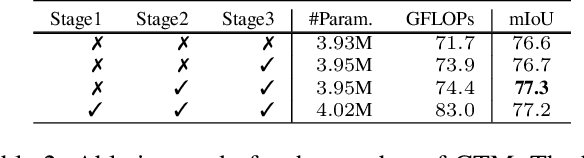
Existing CNN-based methods for pixel labeling heavily depend on multi-scale features to meet the requirements of both semantic comprehension and detail preservation. State-of-the-art pixel labeling neural networks widely exploit conventional scale-transfer operations, i.e., up-sampling and down-sampling to learn multi-scale features. In this work, we find that these operations lead to scale-confused features and suboptimal performance because they are spatial-invariant and directly transit all feature information cross scales without spatial selection. To address this issue, we propose the Gated Scale-Transfer Operation (GSTO) to properly transit spatial-filtered features to another scale. Specifically, GSTO can work either with or without extra supervision. Unsupervised GSTO is learned from the feature itself while the supervised one is guided by the supervised probability matrix. Both forms of GSTO are lightweight and plug-and-play, which can be flexibly integrated into networks or modules for learning better multi-scale features. In particular, by plugging GSTO into HRNet, we get a more powerful backbone (namely GSTO-HRNet) for pixel labeling, and it achieves new state-of-the-art results on the COCO benchmark for human pose estimation and other benchmarks for semantic segmentation including Cityscapes, LIP and Pascal Context, with negligible extra computational cost. Moreover, experiment results demonstrate that GSTO can also significantly boost the performance of multi-scale feature aggregation modules like PPM and ASPP. Code will be made available at https://github.com/VDIGPKU/GSTO.