 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloud Infrastructure Management in the Age of AI Agents
Jun 13, 2025Cloud infrastructure is the cornerstone of the modern IT industry. However, managing this infrastructure effectively requires considerable manual effort from the DevOps engineering team. We make a case for developing AI agents powered by large language models (LLMs) to automate cloud infrastructure management tasks. In a preliminary study, we investigate the potential for AI agents to use different cloud/user interfaces such as software development kits (SDK), command line interfaces (CLI), Infrastructure-as-Code (IaC) platforms, and web portals. We report takeaways on their effectiveness on different management tasks, and identify research challenges and potential solutions.
SQUiD: Synthesizing Relational Databases from Unstructured Text
May 25, 2025Relational databases are central to modern data management, yet most data exists in unstructured forms like text documents. To bridge this gap, we leverage large language models (LLMs) to automatically synthesize a relational database by generating its schema and populating its tables from raw text. We introduce SQUiD, a novel neurosymbolic framework that decomposes this task into four stages, each with specialized techniques. Our experiments show that SQUiD consistently outperforms baselines across diverse datasets.
Direct Nonlinear Acceleration
May 28, 2019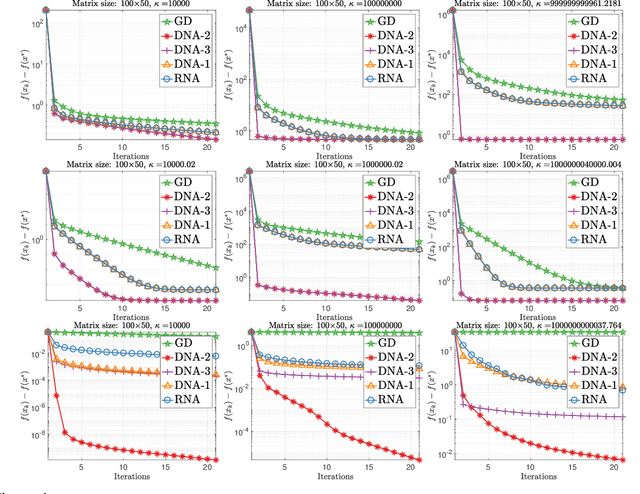
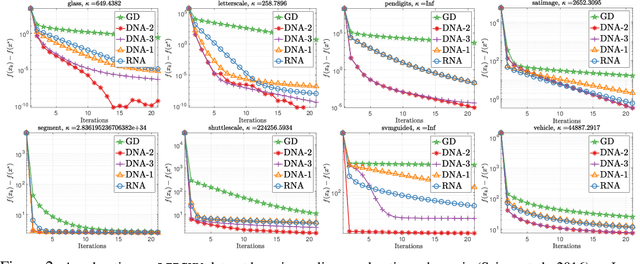
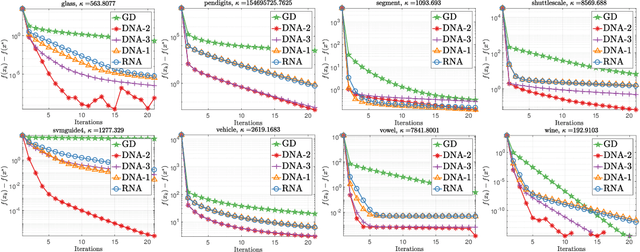
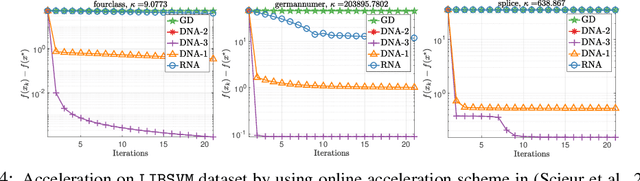
Optimization acceleration techniques such as momentum play a key role in state-of-the-art machine learning algorithms. Recently, generic vector sequence extrapolation techniques, such as regularized nonlinear acceleration (RNA) of Scieur et al., were proposed and shown to accelerate fixed point iterations. In contrast to RNA which computes extrapolation coefficients by (approximately) setting the gradient of the objective function to zero at the extrapolated point, we propose a more direct approach, which we call direct nonlinear acceleration (DNA). In DNA, we aim to minimize (an approximation of) the function value at the extrapolated point instead. We adopt a regularized approach with regularizers designed to prevent the model from entering a region in which the functional approximation is less precise. While the computational cost of DNA is comparable to that of RNA, our direct approach significantly outperforms RNA on both synthetic and real-world datasets. While the focus of this paper is on convex problems, we obtain very encouraging results in accelerating the training of neural networks.