 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting AI Coding Agents in Open Source: A Validated Multi-Method Census of 180 Million Repositories
Jun 23, 2026Generative AI coding agents are entering the open-source supply chain, yet their diverse and often invisible traces leave their prevalence poorly understood. We introduce a multi-layered detection framework that integrates configuration-file scanning, commit-message analysis, author-identity matching, and bot-signature lookup across World of Code (180M+ Git repositories), classifying agent traces into four behavioral types. No single method captures more than a fraction of activity: multi-method detection identifies 850,157 Claude Code commits in one snapshot, of which bot-account lookup_the signal most adoption studies rely on_recovers only 28,154 (3.3%), a 30x relative-recall gap, so single-signal prevalence estimates are biased low by at least this factor. Every detection pattern is hand-validated (495 labels) with per-cell precision and Wilson confidence intervals. Across snapshots from December 2024 to April 2026, commit-attributed agents generate over 320,000 commits per month; Claude Code leads (886,122 commits across 17,295 projects) and dominates silent, configuration-file-only adoption (21,078 projects). Compared against an independent pull-request census (AIDev), the two channels capture nearly disjoint agent populations_a PR census misses 79% of commit-detected Claude Code adopters and essentially all Codex adopters_and different kinds of work: PR-deployed cloud agents (Codex, Cursor) surface as feature work, while commit-deployed in-editor agents (Claude Code, OpenHands, Aider) surface as maintenance. The observed work profile follows deployment and detection mode rather than the tool itself, so no single channel is representative.
Automating Low-Risk Code Review at Meta: RADAR, Risk Calibration, and Review Efficiency
May 28, 2026AI-assisted coding tools have altered software production. At Meta, significant lines of code per human-landed diff grew by 105.9% year over year and per-developer diff volume rose 51%, with agentic AI responsible for over 80% of that growth. Meanwhile, the share of diffs receiving timely review has declined, exposing a widening gap between code supply and reviewer bandwidth. We ask three questions that progress from feasibility through calibration to impact: (1) can risk-stratified automation operate at scale across diverse organizations, (2) how does tuning the risk threshold affect the trade-off between automation yield and safety, and (3) to what extent does automated review reduce end-to-end latency for AI-generated changes? We deployed RADAR (Risk Aware Diff Auto Review), a multi-stage funnel that classifies each diff by authorship and source type, applies eligibility gates, static heuristics, a machine-learned Diff Risk Score, LLM-based Automated Code Review, and deterministic validation before landing qualifying changes. We evaluate RADAR through telemetry covering 535K+ RADAR-reviewed diffs, observational before-after comparisons for policy changes, and difference-in-differences analysis of efficiency outcomes. RADAR has reviewed 535K+ diffs and landed 331K+. Relaxing the Diff Risk Score threshold from the 25th to the 50th percentile increased the approve rate to 60.31%. The revert rate for RADAR-reviewed diffs is 1/3 that of non-RADAR diffs, and the Production Incident rate is 1/50 that of non-RADAR diffs. RADAR reduces median time to close by over 330% and median diff review wall time by 35%. Risk-aware layered automation can materially reduce review bottlenecks created by AI-driven code growth without compromising production safety.
Cracks in The Stack: Hidden Vulnerabilities and Licensing Risks in LLM Pre-Training Datasets
Jan 05, 2025A critical part of creating code suggestion systems is the pre-training of Large Language Models on vast amounts of source code and natural language text, often of questionable origin or quality. This may contribute to the presence of bugs and vulnerabilities in code generated by LLMs. While efforts to identify bugs at or after code generation exist, it is preferable to pre-train or fine-tune LLMs on curated, high-quality, and compliant datasets. The need for vast amounts of training data necessitates that such curation be automated, minimizing human intervention. We propose an automated source code autocuration technique that leverages the complete version history of open-source software projects to improve the quality of training data. This approach leverages the version history of all OSS projects to identify training data samples that have been modified or have undergone changes in at least one OSS project, and pinpoint a subset of samples that include fixes for bugs or vulnerabilities. We evaluate this method using The Stack v2 dataset, and find that 17% of the code versions in the dataset have newer versions, with 17% of those representing bug fixes, including 2.36% addressing known CVEs. The deduplicated version of Stack v2 still includes blobs vulnerable to 6,947 known CVEs. Furthermore, 58% of the blobs in the dataset were never modified after creation, suggesting they likely represent software with minimal or no use. Misidentified blob origins present an additional challenge, as they lead to the inclusion of non-permissively licensed code, raising serious compliance concerns. By addressing these issues, the training of new models can avoid perpetuating buggy code patterns or license violations. We expect our results to inspire process improvements for automated data curation, with the potential to enhance the reliability of outputs generated by AI tools.
Towards Automation of Human Stage of Decay Identification: An Artificial Intelligence Approach
Aug 19, 2024Determining the stage of decomposition (SOD) is crucial for estimating the postmortem interval and identifying human remains. Currently, labor-intensive manual scoring methods are used for this purpose, but they are subjective and do not scale for the emerging large-scale archival collections of human decomposition photos. This study explores the feasibility of automating two common human decomposition scoring methods proposed by Megyesi and Gelderman using artificial intelligence (AI). We evaluated two popular deep learning models, Inception V3 and Xception, by training them on a large dataset of human decomposition images to classify the SOD for different anatomical regions, including the head, torso, and limbs. Additionally, an interrater study was conducted to assess the reliability of the AI models compared to human forensic examiners for SOD identification. The Xception model achieved the best classification performance, with macro-averaged F1 scores of .878, .881, and .702 for the head, torso, and limbs when predicting Megyesi's SODs, and .872, .875, and .76 for the head, torso, and limbs when predicting Gelderman's SODs. The interrater study results supported AI's ability to determine the SOD at a reliability level comparable to a human expert. This work demonstrates the potential of AI models trained on a large dataset of human decomposition images to automate SOD identification.
SLRNet: Semi-Supervised Semantic Segmentation Via Label Reuse for Human Decomposition Images
Feb 24, 2022



Semantic segmentation is a challenging computer vision task demanding a significant amount of pixel-level annotated data. Producing such data is a time-consuming and costly process, especially for domains with a scarcity of experts, such as medicine or forensic anthropology. While numerous semi-supervised approaches have been developed to make the most from the limited labeled data and ample amount of unlabeled data, domain-specific real-world datasets often have characteristics that both reduce the effectiveness of off-the-shelf state-of-the-art methods and also provide opportunities to create new methods that exploit these characteristics. We propose and evaluate a semi-supervised method that reuses available labels for unlabeled images of a dataset by exploiting existing similarities, while dynamically weighting the impact of these reused labels in the training process. We evaluate our method on a large dataset of human decomposition images and find that our method, while conceptually simple, outperforms state-of-the-art consistency and pseudo-labeling-based methods for the segmentation of this dataset. This paper includes graphic content of human decomposition.
Pseudo Pixel-level Labeling for Images with Evolving Content
May 20, 2021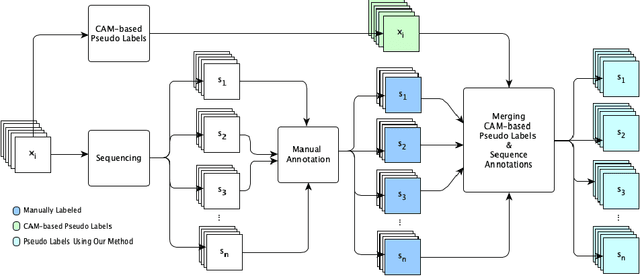
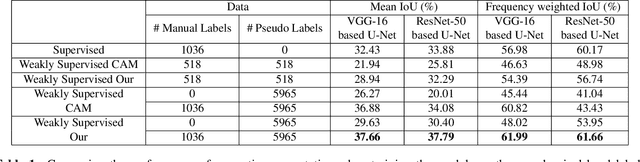

Annotating images for semantic segmentation requires intense manual labor and is a time-consuming and expensive task especially for domains with a scarcity of experts, such as Forensic Anthropology. We leverage the evolving nature of images depicting the decay process in human decomposition data to design a simple yet effective pseudo-pixel-level label generation technique to reduce the amount of effort for manual annotation of such images. We first identify sequences of images with a minimum variation that are most suitable to share the same or similar annotation using an unsupervised approach. Given one user-annotated image in each sequence, we propagate the annotation to the remaining images in the sequence by merging it with annotations produced by a state-of-the-art CAM-based pseudo label generation technique. To evaluate the quality of our pseudo-pixel-level labels, we train two semantic segmentation models with VGG and ResNet backbones on images labeled using our pseudo labeling method and those of a state-of-the-art method. The results indicate that using our pseudo-labels instead of those generated using the state-of-the-art method in the training process improves the mean-IoU and the frequency-weighted-IoU of the VGG and ResNet-based semantic segmentation models by 3.36%, 2.58%, 10.39%, and 12.91% respectively.
Representation of Developer Expertise in Open Source Software
May 20, 2020


With tens of millions of projects and developers, the OSS ecosystem is both vibrant and intimidating. On one hand, it hosts the source code for the most critical infrastructures and has the most brilliant developers as contributors, while on the other hand, poor quality or even malicious software, and novice developers abound. External contributions are critical to OSS projects, but the chances their contributions are accepted or even considered depend on the trust between maintainers and contributors. Such trust is built over repeated interactions and coding platforms provide signals of project or developer quality via measures of activity (commits), and social relationships (followers/stars) to facilitate trust. These signals, however, do not represent the specific expertise of a developer. We, therefore, aim to address this gap by defining the skill space for APIs, developers, and projects that reflects what developers know (and projects need) more precisely than could be obtained via aggregate activity counts, and more generally than pointing to individual files developers have changed in the past. Specifically, we use the World of Code infrastructure to extract the complete set of APIs in the files changed by all open source developers. We use that data to represent APIs, developers, and projects in the skill space, and evaluate if the alignment measures in the skill space can predict whether or not the developers use new APIs, join new projects, or get their pull requests accepted. We also check if the developers' representation in the skill space aligns with their self-reported expertise. Our results suggest that the proposed embedding in the skill space achieves our aims and may serve not only as a signal to increase trust (and efficiency) of open source ecosystems, but may also allow more detailed investigations of other phenomena related to developer proficiency and learning.
Detecting and Characterizing Bots that Commit Code
Mar 27, 2020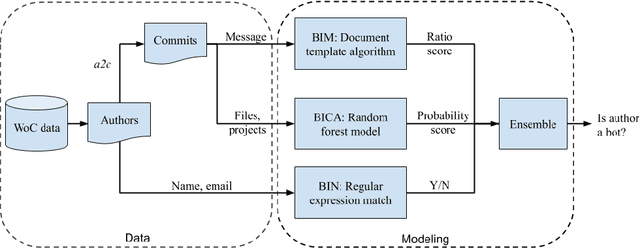

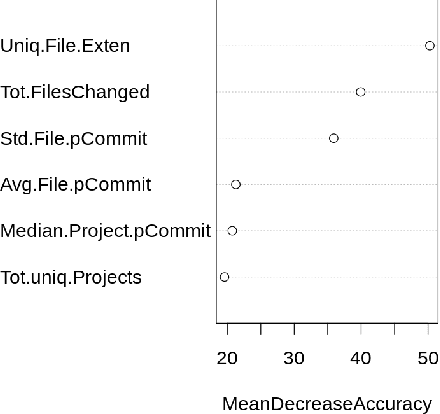
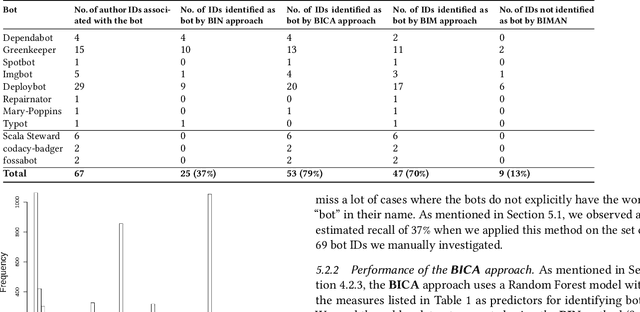
Background: Some developer activity traditionally performed manually, such as making code commits, opening, managing, or closing issues is increasingly subject to automation in many OSS projects. Specifically, such activity is often performed by tools that react to events or run at specific times. We refer to such automation tools as bots and, in many software mining scenarios related to developer productivity or code quality it is desirable to identify bots in order to separate their actions from actions of individuals. Aim: Find an automated way of identifying bots and code committed by these bots, and to characterize the types of bots based on their activity patterns. Method and Result: We propose BIMAN, a systematic approach to detect bots using author names, commit messages, files modified by the commit, and projects associated with the ommits. For our test data, the value for AUC-ROC was 0.9. We also characterized these bots based on the time patterns of their code commits and the types of files modified, and found that they primarily work with documentation files and web pages, and these files are most prevalent in HTML and JavaScript ecosystems. We have compiled a shareable dataset containing detailed information about 461 bots we found (all of whom have more than 1000 commits) and 13,762,430 commits they created.
Collaborative Learning of Semi-Supervised Clustering and Classification for Labeling Uncurated Data
Mar 09, 2020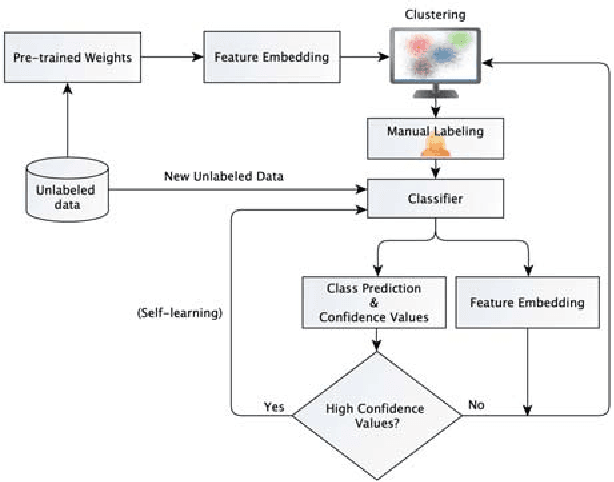


Domain-specific image collections present potential value in various areas of science and business but are often not curated nor have any way to readily extract relevant content. To employ contemporary supervised image analysis methods on such image data, they must first be cleaned and organized, and then manually labeled for the nomenclature employed in the specific domain, which is a time consuming and expensive endeavor. To address this issue, we designed and implemented the Plud system. Plud provides an iterative semi-supervised workflow to minimize the effort spent by an expert and handles realistic large collections of images. We believe it can support labeling datasets regardless of their size and type. Plud is an iterative sequence of unsupervised clustering, human assistance, and supervised classification. With each iteration 1) the labeled dataset grows, 2) the generality of the classification method and its accuracy increases, and 3) manual effort is reduced. We evaluated the effectiveness of our system, by applying it on over a million images documenting human decomposition. In our experiment comparing manual labeling with labeling conducted with the support of Plud, we found that it reduces the time needed to label data and produces highly accurate models for this new domain.
An Analytical Workflow for Clustering Forensic Images
Dec 29, 2019
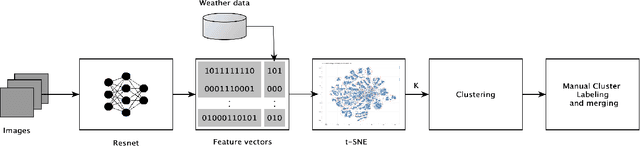
Large collections of images, if curated, drastically contribute to the quality of research in many domains. Unsupervised clustering is an intuitive, yet effective step towards curating such datasets. In this work, we present a workflow for unsupervisedly clustering a large collection of forensic images. The workflow utilizes classic clustering on deep feature representation of the images in addition to domain-related data to group them together. Our manual evaluation shows a purity of 89\% for the resulted clusters.