 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLSA4Rec: Mamba Combined with Low-Rank Decomposed Self-Attention for Sequential Recommendation
Jul 18, 2024



In applications such as e-commerce, online education, and streaming services, sequential recommendation systems play a critical role. Despite the excellent performance of self-attention-based sequential recommendation models in capturing dependencies between items in user interaction history, their quadratic complexity and lack of structural bias limit their applicability. Recently, some works have replaced the self-attention module in sequential recommenders with Mamba, which has linear complexity and structural bias. However, these works have not noted the complementarity between the two approaches. To address this issue, this paper proposes a new hybrid recommendation framework, Mamba combined with Low-Rank decomposed Self-Attention for Sequential Recommendation (MLSA4Rec), whose complexity is linear with respect to the length of the user's historical interaction sequence. Specifically, MLSA4Rec designs an efficient Mamba-LSA interaction module. This module introduces a low-rank decomposed self-attention (LSA) module with linear complexity and injects structural bias into it through Mamba. The LSA module analyzes user preferences from a different perspective and dynamically guides Mamba to focus on important information in user historical interactions through a gated information transmission mechanism. Finally, MLSA4Rec combines user preference information refined by the Mamba and LSA modules to accurately predict the user's next possible interaction. To our knowledge, this is the first study to combine Mamba and self-attention in sequential recommendation systems. Experimental results show that MLSA4Rec outperforms existing self-attention and Mamba-based sequential recommendation models in recommendation accuracy on three real-world datasets, demonstrating the great potential of Mamba and self-attention working together.
SES: Bridging the Gap Between Explainability and Prediction of Graph Neural Networks
Jul 16, 2024



Despite the Graph Neural Networks' (GNNs) proficiency in analyzing graph data, achieving high-accuracy and interpretable predictions remains challenging. Existing GNN interpreters typically provide post-hoc explanations disjointed from GNNs' predictions, resulting in misrepresentations. Self-explainable GNNs offer built-in explanations during the training process. However, they cannot exploit the explanatory outcomes to augment prediction performance, and they fail to provide high-quality explanations of node features and require additional processes to generate explainable subgraphs, which is costly. To address the aforementioned limitations, we propose a self-explained and self-supervised graph neural network (SES) to bridge the gap between explainability and prediction. SES comprises two processes: explainable training and enhanced predictive learning. During explainable training, SES employs a global mask generator co-trained with a graph encoder and directly produces crucial structure and feature masks, reducing time consumption and providing node feature and subgraph explanations. In the enhanced predictive learning phase, mask-based positive-negative pairs are constructed utilizing the explanations to compute a triplet loss and enhance the node representations by contrastive learning.
Graph Structure Prompt Learning: A Novel Methodology to Improve Performance of Graph Neural Networks
Jul 16, 2024



Graph neural networks (GNNs) are widely applied in graph data modeling. However, existing GNNs are often trained in a task-driven manner that fails to fully capture the intrinsic nature of the graph structure, resulting in sub-optimal node and graph representations. To address this limitation, we propose a novel Graph structure Prompt Learning method (GPL) to enhance the training of GNNs, which is inspired by prompt mechanisms in natural language processing. GPL employs task-independent graph structure losses to encourage GNNs to learn intrinsic graph characteristics while simultaneously solving downstream tasks, producing higher-quality node and graph representations. In extensive experiments on eleven real-world datasets, after being trained by GPL, GNNs significantly outperform their original performance on node classification, graph classification, and edge prediction tasks (up to 10.28%, 16.5%, and 24.15%, respectively). By allowing GNNs to capture the inherent structural prompts of graphs in GPL, they can alleviate the issue of over-smooth and achieve new state-of-the-art performances, which introduces a novel and effective direction for GNN research with potential applications in various domains.
Distinguish Any Fake Videos: Unleashing the Power of Large-scale Data and Motion Features
May 24, 2024



The development of AI-Generated Content (AIGC) has empowered the creation of remarkably realistic AI-generated videos, such as those involving Sora. However, the widespread adoption of these models raises concerns regarding potential misuse, including face video scams and copyright disputes. Addressing these concerns requires the development of robust tools capable of accurately determining video authenticity. The main challenges lie in the dataset and neural classifier for training. Current datasets lack a varied and comprehensive repository of real and generated content for effective discrimination. In this paper, we first introduce an extensive video dataset designed specifically for AI-Generated Video Detection (GenVidDet). It includes over 2.66 M instances of both real and generated videos, varying in categories, frames per second, resolutions, and lengths. The comprehensiveness of GenVidDet enables the training of a generalizable video detector. We also present the Dual-Branch 3D Transformer (DuB3D), an innovative and effective method for distinguishing between real and generated videos, enhanced by incorporating motion information alongside visual appearance. DuB3D utilizes a dual-branch architecture that adaptively leverages and fuses raw spatio-temporal data and optical flow. We systematically explore the critical factors affecting detection performance, achieving the optimal configuration for DuB3D. Trained on GenVidDet, DuB3D can distinguish between real and generated video content with 96.77% accuracy, and strong generalization capability even for unseen types.
GREASE: Generate Factual and Counterfactual Explanations for GNN-based Recommendations
Aug 04, 2022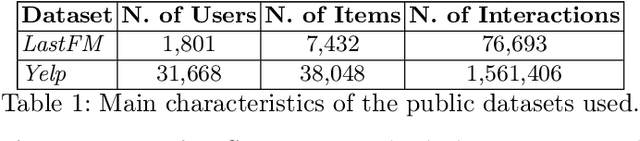
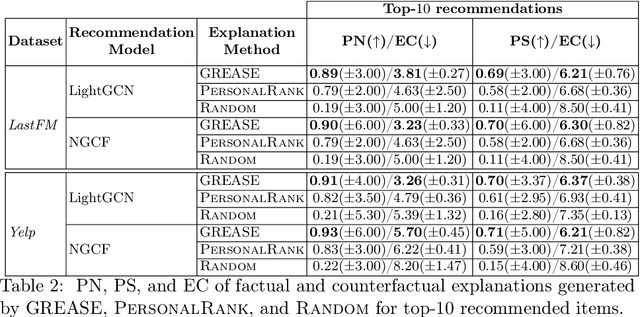
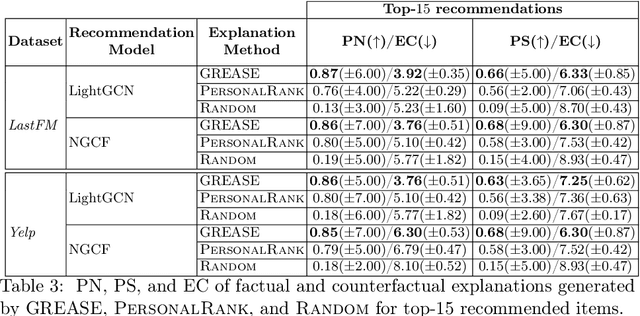
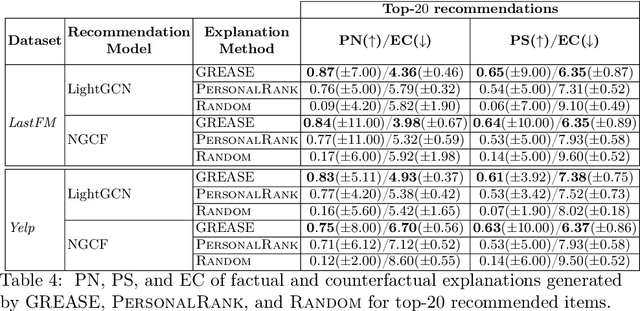
Recently, graph neural networks (GNNs) have been widely used to develop successful recommender systems. Although powerful, it is very difficult for a GNN-based recommender system to attach tangible explanations of why a specific item ends up in the list of suggestions for a given user. Indeed, explaining GNN-based recommendations is unique, and existing GNN explanation methods are inappropriate for two reasons. First, traditional GNN explanation methods are designed for node, edge, or graph classification tasks rather than ranking, as in recommender systems. Second, standard machine learning explanations are usually intended to support skilled decision-makers. Instead, recommendations are designed for any end-user, and thus their explanations should be provided in user-understandable ways. In this work, we propose GREASE, a novel method for explaining the suggestions provided by any black-box GNN-based recommender system. Specifically, GREASE first trains a surrogate model on a target user-item pair and its $l$-hop neighborhood. Then, it generates both factual and counterfactual explanations by finding optimal adjacency matrix perturbations to capture the sufficient and necessary conditions for an item to be recommended, respectively. Experimental results conducted on real-world datasets demonstrate that GREASE can generate concise and effective explanations for popular GNN-based recommender models.
Automatic Curriculum Learning With Over-repetition Penalty for Dialogue Policy Learning
Dec 28, 2020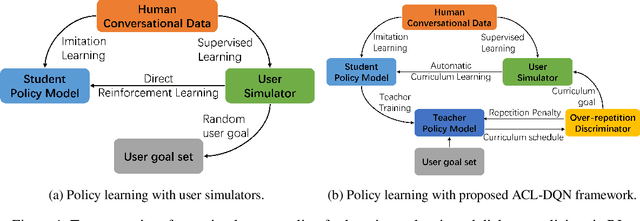

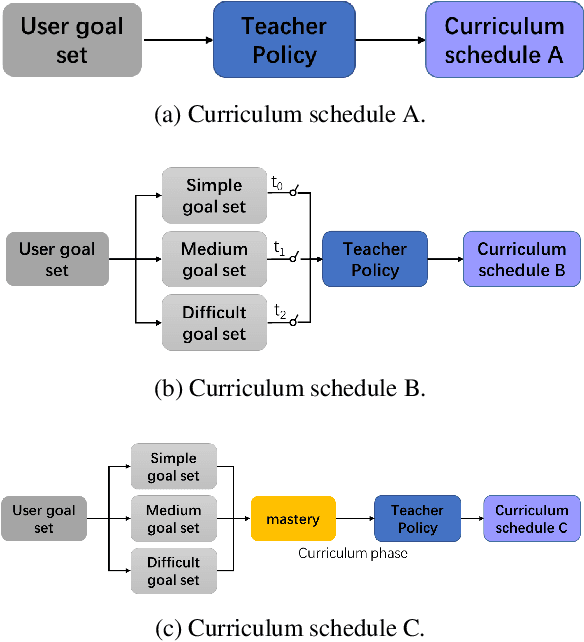
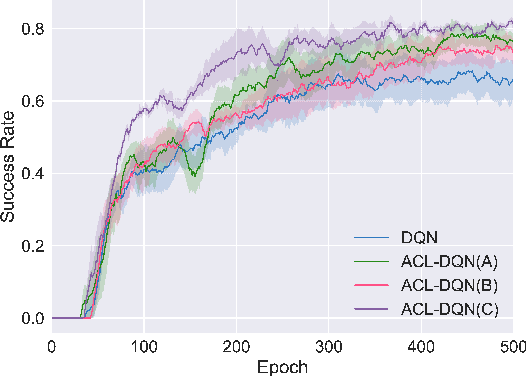
Dialogue policy learning based on reinforcement learning is difficult to be applied to real users to train dialogue agents from scratch because of the high cost. User simulators, which choose random user goals for the dialogue agent to train on, have been considered as an affordable substitute for real users. However, this random sampling method ignores the law of human learning, making the learned dialogue policy inefficient and unstable. We propose a novel framework, Automatic Curriculum Learning-based Deep Q-Network (ACL-DQN), which replaces the traditional random sampling method with a teacher policy model to realize the dialogue policy for automatic curriculum learning. The teacher model arranges a meaningful ordered curriculum and automatically adjusts it by monitoring the learning progress of the dialogue agent and the over-repetition penalty without any requirement of prior knowledge. The learning progress of the dialogue agent reflects the relationship between the dialogue agent's ability and the sampled goals' difficulty for sample efficiency. The over-repetition penalty guarantees the sampled diversity. Experiments show that the ACL-DQN significantly improves the effectiveness and stability of dialogue tasks with a statistically significant margin. Furthermore, the framework can be further improved by equipping with different curriculum schedules, which demonstrates that the framework has strong generalizability.
EdgeCNN: Convolutional Neural Network Classification Model with small inputs for Edge Computing
Sep 30, 2019
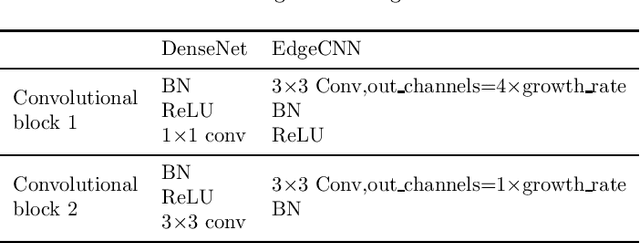
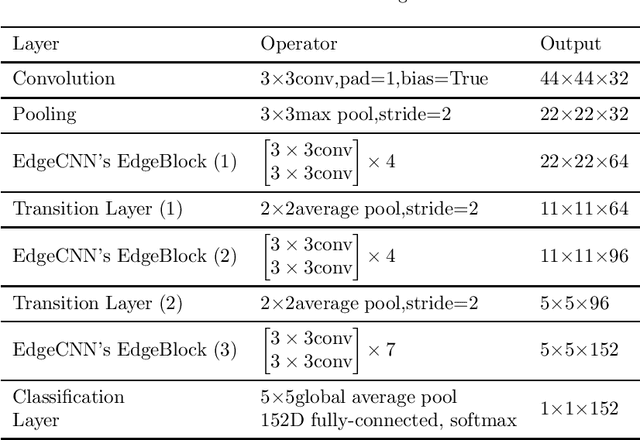
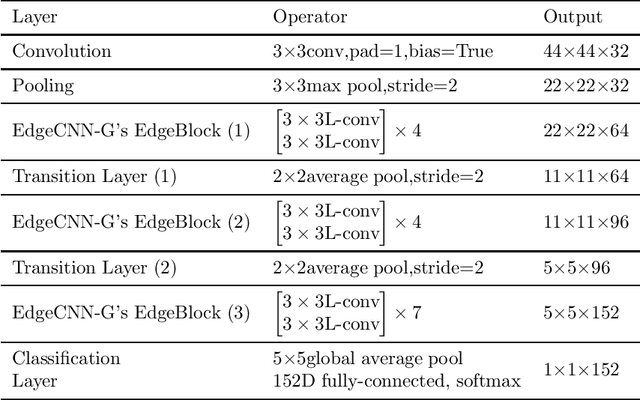
With the development of Internet of Things (IoT), data is increasingly appearing on the edge of the network. Processing tasks on the edge of the network can effectively solve the problems of personal privacy leaks and server overload. As a result, it has attracted a great deal of attention and made substantial progress. This progress includes efficient convolutional neural network (CNN) models such as MobileNet and ShuffleNet. However, all of these networks appear as a common network model and they usually need to identify multiple targets when applied. So the size of the input is very large. In some specific cases, only the target needs to be classified. Therefore, a small input network can be designed to reduce computation. In addition, other efficient neural network models are primarily designed for mobile phones. Mobile phones have faster memory access, which allows them to use group convolution. In particular, this paper finds that the recently widely used group convolution is not suitable for devices with very slow memory access. Therefore, the EdgeCNN of this paper is designed for edge computing devices with low memory access speed and low computing resources. EdgeCNN has been run successfully on the Raspberry Pi 3B+ at a speed of 1.37 frames per second. The accuracy of facial expression classification for the FER-2013 and RAF-DB datasets outperforms other proposed networks that are compatible with the Raspberry Pi 3B+. The implementation of EdgeCNN is available at https://github.com/yangshunzhi1994/EdgeCNN