 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond N-gram: Data-Aware X-GRAM Extraction for Efficient Embedding Parameter Scaling
Apr 23, 2026Large token-indexed lookup tables provide a compute-decoupled scaling path, but their practical gains are often limited by poor parameter efficiency and rapid memory growth. We attribute these limitations to Zipfian under-training of the long tail, heterogeneous demand across layers, and "slot collapse" that produces redundant embeddings. To address this, we propose X-GRAM, a frequency-aware dynamic token-injection framework. X-GRAM employs hybrid hashing and alias mixing to compress the tail while preserving head capacity, and refines retrieved vectors via normalized SwiGLU ShortConv to extract diverse local n-gram features. These signals are integrated into attention value streams and inter-layer residuals using depth-aware gating, effectively aligning static memory with dynamic context. This design introduces a memory-centric scaling axis that decouples model capacity from FLOPs. Extensive evaluations at the 0.73B and 1.15B scales show that X-GRAM improves average accuracy by as much as 4.4 points over the vanilla backbone and 3.2 points over strong retrieval baselines, while using substantially smaller tables in the 50% configuration. Overall, by decoupling capacity from compute through efficient memory management, X-GRAM offers a scalable and practical paradigm for future memory-augmented architectures. Code aviliable in https://github.com/Longyichen/X-gram.
Automatic Cross-Domain Transfer Learning for Linear Regression
May 08, 2020
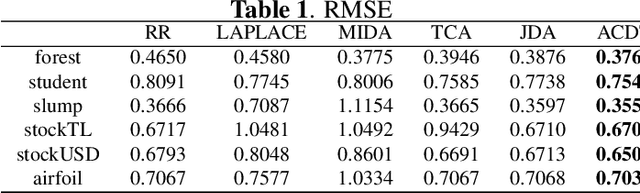
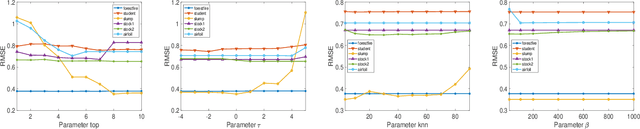

Transfer learning research attempts to make model induction transferable across different domains. This method assumes that specific information regarding to which domain each instance belongs is known. This paper helps to extend the capability of transfer learning for linear regression problems to situations where the domain information is uncertain or unknown; in fact, the framework can be extended to classification problems. For normal datasets, we assume that some latent domain information is available for transfer learning. The instances in each domain can be inferred by different parameters. We obtain this domain information from the distribution of the regression coefficients corresponding to the explanatory variable $x$ as well as the response variable $y$ based on a Dirichlet process, which is more reasonable. As a result, we transfer not only variable $x$ as usual but also variable $y$, which is challenging since the testing data have no response value. Previous work mainly overcomes the problem via pseudo-labelling based on transductive learning, which introduces serious bias. We provide a novel framework for analysing the problem and considering this general situation: the joint distribution of variable $x$ and variable $y$. Furthermore, our method controls the bias well compared with previous work. We perform linear regression on the new feature space that consists of different latent domains and the target domain, which is from the testing data. The experimental results show that the proposed model performs well on real datasets.