 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tale of Two Cities: Pessimism and Opportunism in Offline Dynamic Pricing
Nov 12, 2024This paper studies offline dynamic pricing without data coverage assumption, thereby allowing for any price including the optimal one not being observed in the offline data. Previous approaches that rely on the various coverage assumptions such as that the optimal prices are observable, would lead to suboptimal decisions and consequently, reduced profits. We address this challenge by framing the problem to a partial identification framework. Specifically, we establish a partial identification bound for the demand parameter whose associated price is unobserved by leveraging the inherent monotonicity property in the pricing problem. We further incorporate pessimistic and opportunistic strategies within the proposed partial identification framework to derive the estimated policy. Theoretically, we establish rate-optimal finite-sample regret guarantees for both strategies. Empirically, we demonstrate the superior performance of the newly proposed methods via a synthetic environment. This research provides practitioners with valuable insights into offline pricing strategies in the challenging no-coverage setting, ultimately fostering sustainable growth and profitability of the company.
Learning Robust Treatment Rules for Censored Data
Aug 17, 2024



There is a fast-growing literature on estimating optimal treatment rules directly by maximizing the expected outcome. In biomedical studies and operations applications, censored survival outcome is frequently observed, in which case the restricted mean survival time and survival probability are of great interest. In this paper, we propose two robust criteria for learning optimal treatment rules with censored survival outcomes; the former one targets at an optimal treatment rule maximizing the restricted mean survival time, where the restriction is specified by a given quantile such as median; the latter one targets at an optimal treatment rule maximizing buffered survival probabilities, where the predetermined threshold is adjusted to account the restricted mean survival time. We provide theoretical justifications for the proposed optimal treatment rules and develop a sampling-based difference-of-convex algorithm for learning them. In simulation studies, our estimators show improved performance compared to existing methods. We also demonstrate the proposed method using AIDS clinical trial data.
Distributional Off-policy Evaluation with Bellman Residual Minimization
Feb 02, 2024We consider the problem of distributional off-policy evaluation which serves as the foundation of many distributional reinforcement learning (DRL) algorithms. In contrast to most existing works (that rely on supremum-extended statistical distances such as supremum-Wasserstein distance), we study the expectation-extended statistical distance for quantifying the distributional Bellman residuals and show that it can upper bound the expected error of estimating the return distribution. Based on this appealing property, by extending the framework of Bellman residual minimization to DRL, we propose a method called Energy Bellman Residual Minimizer (EBRM) to estimate the return distribution. We establish a finite-sample error bound for the EBRM estimator under the realizability assumption. Furthermore, we introduce a variant of our method based on a multi-step bootstrapping procedure to enable multi-step extension. By selecting an appropriate step level, we obtain a better error bound for this variant of EBRM compared to a single-step EBRM, under some non-realizability settings. Finally, we demonstrate the superior performance of our method through simulation studies, comparing with several existing methods.
Robust Offline Policy Evaluation and Optimization with Heavy-Tailed Rewards
Oct 28, 2023



This paper endeavors to augment the robustness of offline reinforcement learning (RL) in scenarios laden with heavy-tailed rewards, a prevalent circumstance in real-world applications. We propose two algorithmic frameworks, ROAM and ROOM, for robust off-policy evaluation (OPE) and offline policy optimization (OPO), respectively. Central to our frameworks is the strategic incorporation of the median-of-means method with offline RL, enabling straightforward uncertainty estimation for the value function estimator. This not only adheres to the principle of pessimism in OPO but also adeptly manages heavy-tailed rewards. Theoretical results and extensive experiments demonstrate that our two frameworks outperform existing methods on the logged dataset exhibits heavy-tailed reward distributions.
Off-policy Evaluation in Doubly Inhomogeneous Environments
Jun 14, 2023This work aims to study off-policy evaluation (OPE) under scenarios where two key reinforcement learning (RL) assumptions -- temporal stationarity and individual homogeneity are both violated. To handle the ``double inhomogeneities", we propose a class of latent factor models for the reward and observation transition functions, under which we develop a general OPE framework that consists of both model-based and model-free approaches. To our knowledge, this is the first paper that develops statistically sound OPE methods in offline RL with double inhomogeneities. It contributes to a deeper understanding of OPE in environments, where standard RL assumptions are not met, and provides several practical approaches in these settings. We establish the theoretical properties of the proposed value estimators and empirically show that our approach outperforms competing methods that ignore either temporal nonstationarity or individual heterogeneity. Finally, we illustrate our method on a data set from the Medical Information Mart for Intensive Care.
A Policy Gradient Method for Confounded POMDPs
May 26, 2023



In this paper, we propose a policy gradient method for confounded partially observable Markov decision processes (POMDPs) with continuous state and observation spaces in the offline setting. We first establish a novel identification result to non-parametrically estimate any history-dependent policy gradient under POMDPs using the offline data. The identification enables us to solve a sequence of conditional moment restrictions and adopt the min-max learning procedure with general function approximation for estimating the policy gradient. We then provide a finite-sample non-asymptotic bound for estimating the gradient uniformly over a pre-specified policy class in terms of the sample size, length of horizon, concentratability coefficient and the measure of ill-posedness in solving the conditional moment restrictions. Lastly, by deploying the proposed gradient estimation in the gradient ascent algorithm, we show the global convergence of the proposed algorithm in finding the history-dependent optimal policy under some technical conditions. To the best of our knowledge, this is the first work studying the policy gradient method for POMDPs under the offline setting.
Sequential Knockoffs for Variable Selection in Reinforcement Learning
Mar 24, 2023



In real-world applications of reinforcement learning, it is often challenging to obtain a state representation that is parsimonious and satisfies the Markov property without prior knowledge. Consequently, it is common practice to construct a state which is larger than necessary, e.g., by concatenating measurements over contiguous time points. However, needlessly increasing the dimension of the state can slow learning and obfuscate the learned policy. We introduce the notion of a minimal sufficient state in a Markov decision process (MDP) as the smallest subvector of the original state under which the process remains an MDP and shares the same optimal policy as the original process. We propose a novel sequential knockoffs (SEEK) algorithm that estimates the minimal sufficient state in a system with high-dimensional complex nonlinear dynamics. In large samples, the proposed method controls the false discovery rate, and selects all sufficient variables with probability approaching one. As the method is agnostic to the reinforcement learning algorithm being applied, it benefits downstream tasks such as policy optimization. Empirical experiments verify theoretical results and show the proposed approach outperforms several competing methods in terms of variable selection accuracy and regret.
Personalized Pricing with Invalid Instrumental Variables: Identification, Estimation, and Policy Learning
Feb 24, 2023



Pricing based on individual customer characteristics is widely used to maximize sellers' revenues. This work studies offline personalized pricing under endogeneity using an instrumental variable approach. Standard instrumental variable methods in causal inference/econometrics either focus on a discrete treatment space or require the exclusion restriction of instruments from having a direct effect on the outcome, which limits their applicability in personalized pricing. In this paper, we propose a new policy learning method for Personalized pRicing using Invalid iNsTrumental variables (PRINT) for continuous treatment that allow direct effects on the outcome. Specifically, relying on the structural models of revenue and price, we establish the identifiability condition of an optimal pricing strategy under endogeneity with the help of invalid instrumental variables. Based on this new identification, which leads to solving conditional moment restrictions with generalized residual functions, we construct an adversarial min-max estimator and learn an optimal pricing strategy. Furthermore, we establish an asymptotic regret bound to find an optimal pricing strategy. Finally, we demonstrate the effectiveness of the proposed method via extensive simulation studies as well as a real data application from an US online auto loan company.
PASTA: Pessimistic Assortment Optimization
Feb 08, 2023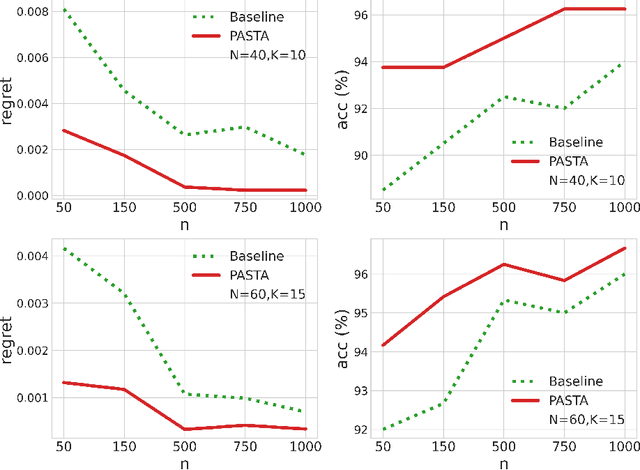
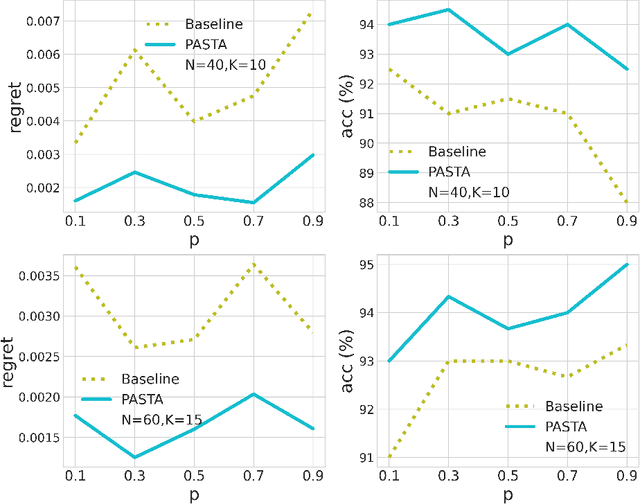
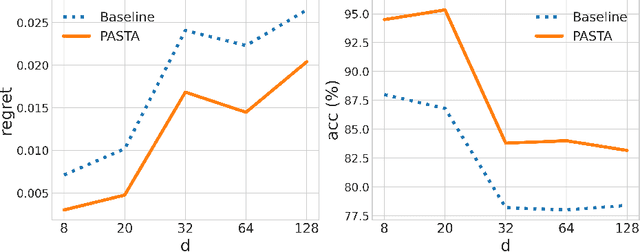
We consider a class of assortment optimization problems in an offline data-driven setting. A firm does not know the underlying customer choice model but has access to an offline dataset consisting of the historically offered assortment set, customer choice, and revenue. The objective is to use the offline dataset to find an optimal assortment. Due to the combinatorial nature of assortment optimization, the problem of insufficient data coverage is likely to occur in the offline dataset. Therefore, designing a provably efficient offline learning algorithm becomes a significant challenge. To this end, we propose an algorithm referred to as Pessimistic ASsortment opTimizAtion (PASTA for short) designed based on the principle of pessimism, that can correctly identify the optimal assortment by only requiring the offline data to cover the optimal assortment under general settings. In particular, we establish a regret bound for the offline assortment optimization problem under the celebrated multinomial logit model. We also propose an efficient computational procedure to solve our pessimistic assortment optimization problem. Numerical studies demonstrate the superiority of the proposed method over the existing baseline method.
STEEL: Singularity-aware Reinforcement Learning
Jan 31, 2023



Batch reinforcement learning (RL) aims at finding an optimal policy in a dynamic environment in order to maximize the expected total rewards by leveraging pre-collected data. A fundamental challenge behind this task is the distributional mismatch between the batch data generating process and the distribution induced by target policies. Nearly all existing algorithms rely on the absolutely continuous assumption on the distribution induced by target policies with respect to the data distribution so that the batch data can be used to calibrate target policies via the change of measure. However, the absolute continuity assumption could be violated in practice, especially when the state-action space is large or continuous. In this paper, we propose a new batch RL algorithm without requiring absolute continuity in the setting of an infinite-horizon Markov decision process with continuous states and actions. We call our algorithm STEEL: SingulariTy-awarE rEinforcement Learning. Our algorithm is motivated by a new error analysis on off-policy evaluation, where we use maximum mean discrepancy, together with distributionally robust optimization, to characterize the error of off-policy evaluation caused by the possible singularity and to enable the power of model extrapolation. By leveraging the idea of pessimism and under some mild conditions, we derive a finite-sample regret guarantee for our proposed algorithm without imposing absolute continuity. Compared with existing algorithms, STEEL only requires some minimal data-coverage assumption and thus greatly enhances the applicability and robustness of batch RL. Extensive simulation studies and one real experiment on personalized pricing demonstrate the superior performance of our method when facing possible singularity in batch RL.