 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-rank Distributional Matrix Completion
Jun 02, 2026We study a distributional generalization of the matrix completion problem in which each entry of the target matrix is a probability distribution rather than a scalar. In this setting, only a subset of matrix entries is observed, and even for observed entries, the underlying distributions are not directly accessible; instead, we observe finitely many samples drawn from them. To represent distributional entries, we employ kernel mean embeddings and introduce a notion of Tucker rank for distribution-valued matrices to capture their low-rank structure. The infinite-dimensional nature of kernel embeddings poses significant methodological challenges. To address this, we introduce functional unfolding operators that link the proposed distributional low-rank structure to the classical Tucker rank for finite-dimensional tensors. Based on this framework, we propose a novel estimator for distributional matrix completion. We establish non-asymptotic error bounds that characterize the statistical performance of the estimator. Extensive experiments on synthetic data and a real-world application demonstrate the effectiveness of the proposed method.
Revisiting Neural Processes via Fourier Transform and Volterra Series
May 31, 2026Modeling unknown latent functions from finite, irregularly sampled measurements is a recurring challenge across science and engineering. Neural processes (NPs), a family of probabilistic functional models, are promising solutions -- especially when endowed with domain-specific symmetries like translation equivariance, which improve sample efficiency and generalization. Yet existing translation-equivariant NPs face two limitations: (i) they stack generic components with non-linearities, obscuring the induced function class and limiting interpretability; and (ii) convolutional designs rely on kernels with local receptive fields and require dense uniform input grids, while attention-based methods avoid these issues but scale quadratically with the number of observations. We address both with two contributions. First, using the Volterra expansion, we characterize continuous translation-equivariant operators as sums of higher-order convolutions, yielding analytical transparency while admitting efficient approximation by first-order convolutions. Second, we introduce set Fourier convolutions (SFConvs), a frequency-domain parameterization that operates directly on irregularly sampled points, achieves approximately global receptive fields, and scales linearly in the number of observations. Building on these ideas, we propose two conditional NPs (CNPs): SFConvCNPs, which stack SFConv blocks with non-linearities, and SFVConvCNPs, which integrate the Volterra formulation. Experiments on synthetic and real-world datasets demonstrate our methods' efficacy against state-of-the-art baselines.
Density-aware Sample-specific Attack
May 28, 2026Despite recent progress in backdoor attacks, existing methods remain susceptible to post-training defenses that erase the backdoor through fine-tuning or pruning. We revisit the core objectives of backdoor attacks and derive principled criteria characterizing optimal sample-specific trigger construction under a Bayes-optimal model of the victim's training. Our analysis reveals that both attack success and clean-accuracy preservation are simultaneously optimized when triggered samples are steered into low-density regions of the clean data distribution, a distributional condition that controls all moments of the poisoned distribution at once rather than a handful of input-space summary statistics. We introduce a bilevel optimization framework that estimates density ratios via conditional time-score matching and optimizes a mixture-model objective to place triggered samples in these sparse regions. Extensive evaluations on MNIST, CIFAR-10, GTSRB, and TinyImageNet demonstrate that our method achieves above 99\% attack success rate before defense and retains 50--85 percentage points higher post-defense ASR than the strongest baselines under fine-tuning defenses. Against neuron-pruning defenses, the method exhibits complete immunity, with zero neurons identified for removal across all pruning thresholds. These results expose a fundamental gap in current defense paradigms and underscore the need for defenses that operate beyond the support of the clean distribution.
Fair Regression under Demographic Parity: A Unified Framework
Jan 15, 2026We propose a unified framework for fair regression tasks formulated as risk minimization problems subject to a demographic parity constraint. Unlike many existing approaches that are limited to specific loss functions or rely on challenging non-convex optimization, our framework is applicable to a broad spectrum of regression tasks. Examples include linear regression with squared loss, binary classification with cross-entropy loss, quantile regression with pinball loss, and robust regression with Huber loss. We derive a novel characterization of the fair risk minimizer, which yields a computationally efficient estimation procedure for general loss functions. Theoretically, we establish the asymptotic consistency of the proposed estimator and derive its convergence rates under mild assumptions. We illustrate the method's versatility through detailed discussions of several common loss functions. Numerical results demonstrate that our approach effectively minimizes risk while satisfying fairness constraints across various regression settings.
Distributional Off-policy Evaluation with Bellman Residual Minimization
Feb 02, 2024We consider the problem of distributional off-policy evaluation which serves as the foundation of many distributional reinforcement learning (DRL) algorithms. In contrast to most existing works (that rely on supremum-extended statistical distances such as supremum-Wasserstein distance), we study the expectation-extended statistical distance for quantifying the distributional Bellman residuals and show that it can upper bound the expected error of estimating the return distribution. Based on this appealing property, by extending the framework of Bellman residual minimization to DRL, we propose a method called Energy Bellman Residual Minimizer (EBRM) to estimate the return distribution. We establish a finite-sample error bound for the EBRM estimator under the realizability assumption. Furthermore, we introduce a variant of our method based on a multi-step bootstrapping procedure to enable multi-step extension. By selecting an appropriate step level, we obtain a better error bound for this variant of EBRM compared to a single-step EBRM, under some non-realizability settings. Finally, we demonstrate the superior performance of our method through simulation studies, comparing with several existing methods.
Directed Cyclic Graph for Causal Discovery from Multivariate Functional Data
Oct 31, 2023Discovering causal relationship using multivariate functional data has received a significant amount of attention very recently. In this article, we introduce a functional linear structural equation model for causal structure learning when the underlying graph involving the multivariate functions may have cycles. To enhance interpretability, our model involves a low-dimensional causal embedded space such that all the relevant causal information in the multivariate functional data is preserved in this lower-dimensional subspace. We prove that the proposed model is causally identifiable under standard assumptions that are often made in the causal discovery literature. To carry out inference of our model, we develop a fully Bayesian framework with suitable prior specifications and uncertainty quantification through posterior summaries. We illustrate the superior performance of our method over existing methods in terms of causal graph estimation through extensive simulation studies. We also demonstrate the proposed method using a brain EEG dataset.
Implicit Regularization for Group Sparsity
Jan 29, 2023



We study the implicit regularization of gradient descent towards structured sparsity via a novel neural reparameterization, which we call a diagonally grouped linear neural network. We show the following intriguing property of our reparameterization: gradient descent over the squared regression loss, without any explicit regularization, biases towards solutions with a group sparsity structure. In contrast to many existing works in understanding implicit regularization, we prove that our training trajectory cannot be simulated by mirror descent. We analyze the gradient dynamics of the corresponding regression problem in the general noise setting and obtain minimax-optimal error rates. Compared to existing bounds for implicit sparse regularization using diagonal linear networks, our analysis with the new reparameterization shows improved sample complexity. In the degenerate case of size-one groups, our approach gives rise to a new algorithm for sparse linear regression. Finally, we demonstrate the efficacy of our approach with several numerical experiments.
Extending the Use of MDL for High-Dimensional Problems: Variable Selection, Robust Fitting, and Additive Modeling
Jan 26, 2022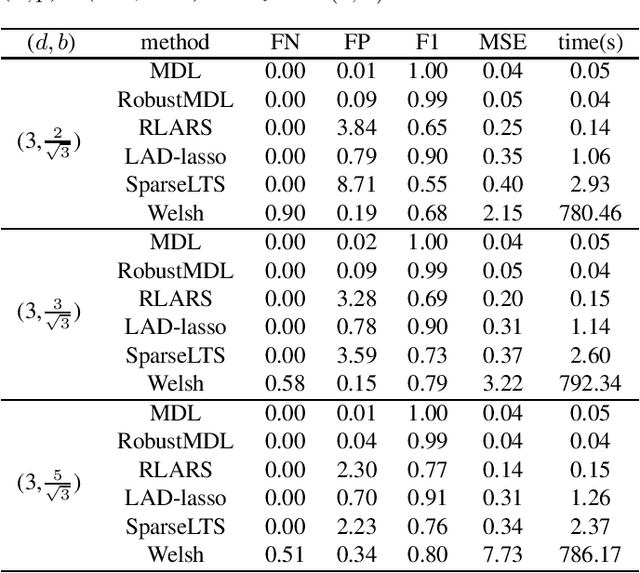
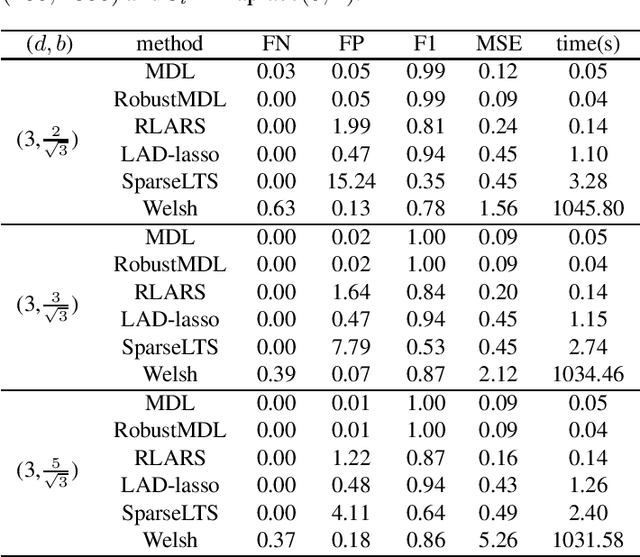
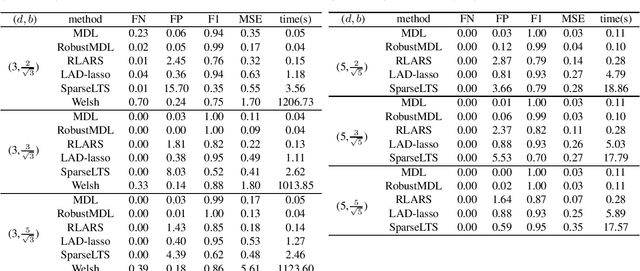
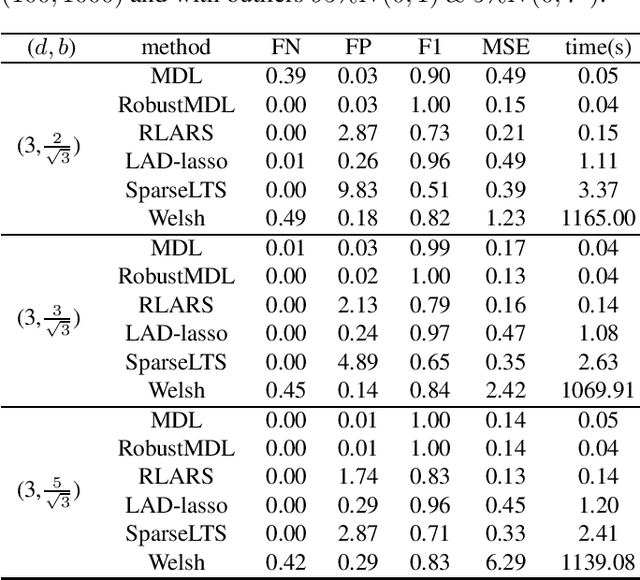
In the signal processing and statistics literature, the minimum description length (MDL) principle is a popular tool for choosing model complexity. Successful examples include signal denoising and variable selection in linear regression, for which the corresponding MDL solutions often enjoy consistent properties and produce very promising empirical results. This paper demonstrates that MDL can be extended naturally to the high-dimensional setting, where the number of predictors $p$ is larger than the number of observations $n$. It first considers the case of linear regression, then allows for outliers in the data, and lastly extends to the robust fitting of nonparametric additive models. Results from numerical experiments are presented to demonstrate the efficiency and effectiveness of the MDL approach.
Projected State-action Balancing Weights for Offline Reinforcement Learning
Sep 10, 2021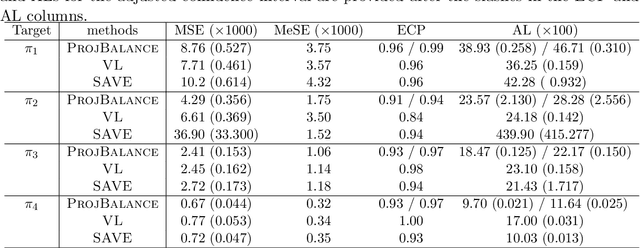
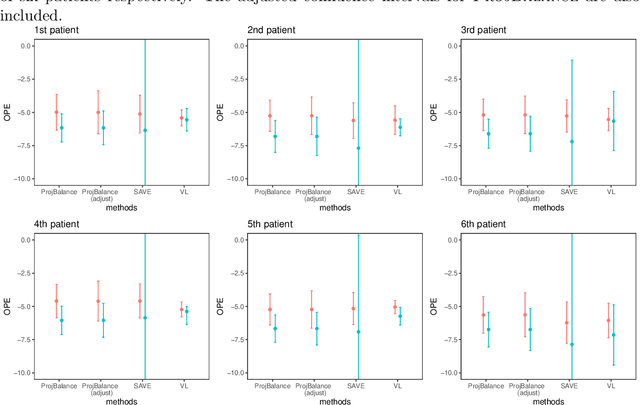
Offline policy evaluation (OPE) is considered a fundamental and challenging problem in reinforcement learning (RL). This paper focuses on the value estimation of a target policy based on pre-collected data generated from a possibly different policy, under the framework of infinite-horizon Markov decision processes. Motivated by the recently developed marginal importance sampling method in RL and the covariate balancing idea in causal inference, we propose a novel estimator with approximately projected state-action balancing weights for the policy value estimation. We obtain the convergence rate of these weights, and show that the proposed value estimator is semi-parametric efficient under technical conditions. In terms of asymptotics, our results scale with both the number of trajectories and the number of decision points at each trajectory. As such, consistency can still be achieved with a limited number of subjects when the number of decision points diverges. In addition, we make a first attempt towards characterizing the difficulty of OPE problems, which may be of independent interest. Numerical experiments demonstrate the promising performance of our proposed estimator.
Implicit Sparse Regularization: The Impact of Depth and Early Stopping
Aug 12, 2021
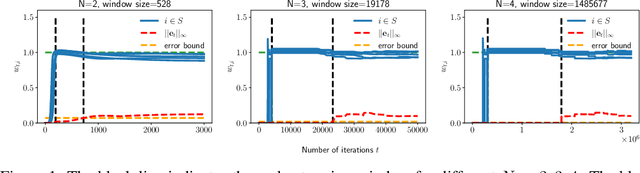
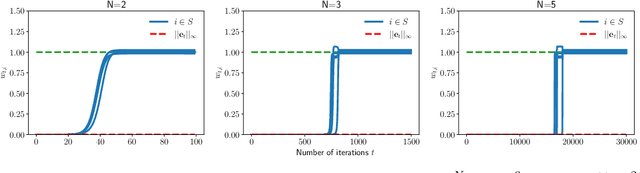
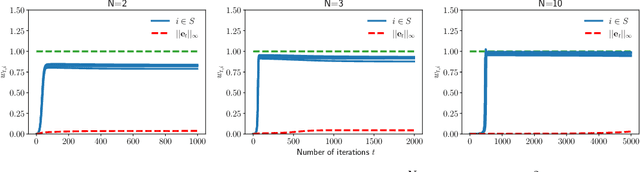
In this paper, we study the implicit bias of gradient descent for sparse regression. We extend results on regression with quadratic parametrization, which amounts to depth-2 diagonal linear networks, to more general depth-N networks, under more realistic settings of noise and correlated designs. We show that early stopping is crucial for gradient descent to converge to a sparse model, a phenomenon that we call implicit sparse regularization. This result is in sharp contrast to known results for noiseless and uncorrelated-design cases. We characterize the impact of depth and early stopping and show that for a general depth parameter N, gradient descent with early stopping achieves minimax optimal sparse recovery with sufficiently small initialization and step size. In particular, we show that increasing depth enlarges the scale of working initialization and the early-stopping window, which leads to more stable gradient paths for sparse recovery.