 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Recurrent Variational Autoencoder for Speech Enhancement
Apr 05, 2022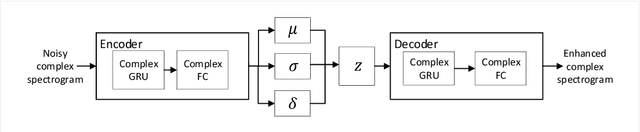
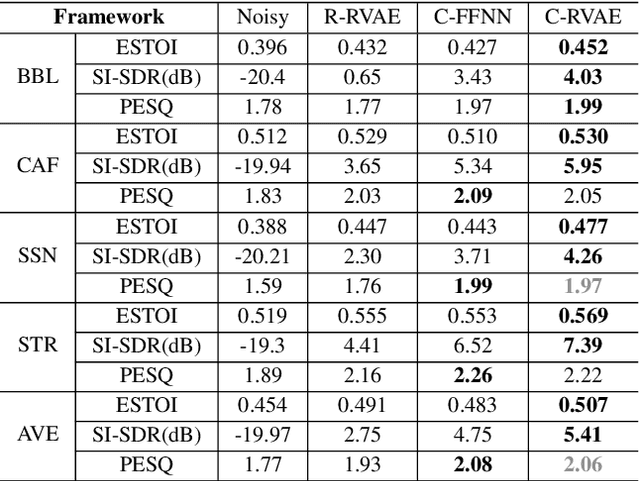
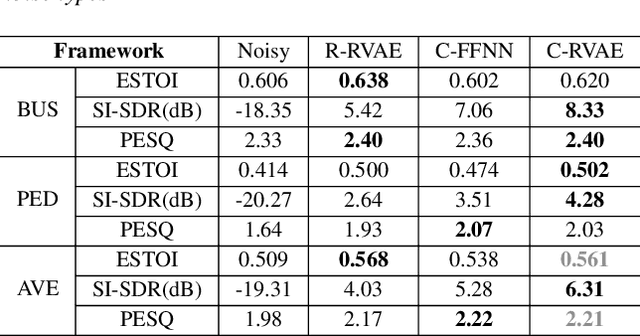
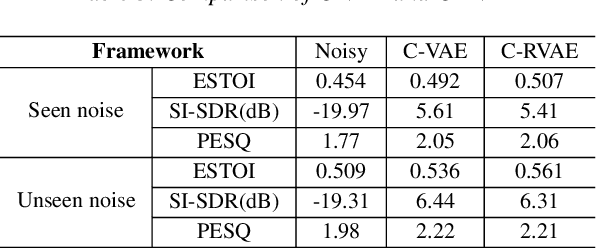
Commonly-used methods in speech enhancement are based on short-time fourier transform (STFT) representation, in particular on the magnitude of the STFT. This is because phase is naturally unstructured and intractable, and magnitude has shown more importance in speech enhancement. Nevertheless, phase has shown its significance in some research and cannot be ignored. Complex neural networks, with their inherent advantage, provide a solution for complex spectrogram processing. Complex variational autoencoder (VAE), as an extension of vanilla \acrshort{vae}, has shown positive results in complex spectrogram representation. However, the existing work on complex \acrshort{vae} only uses linear layers and merely applies the model on direct spectra representation. This paper extends the linear complex \acrshort{vae} to a non-linear one. Furthermore, on account of the temporal property of speech signals, a complex recurrent \acrshort{vae} is proposed. The proposed model has been applied on speech enhancement. As far as we know, it is the first time that a complex generative model is applied to speech enhancement. Experiments are based on the TIMIT dataset, while speech intelligibility and speech quality have been evaluated. The results show that, for speech enhancement, the proposed method has better performance on speech intelligibility and comparable performance on speech quality.
Disentangled Speech Representation Learning Based on Factorized Hierarchical Variational Autoencoder with Self-Supervised Objective
Apr 05, 2022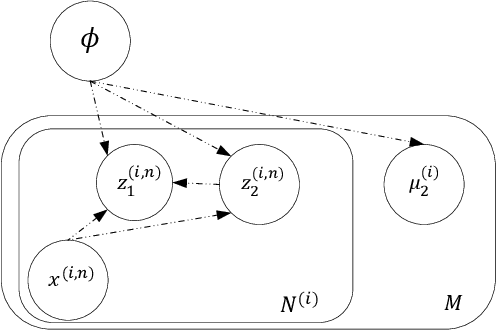

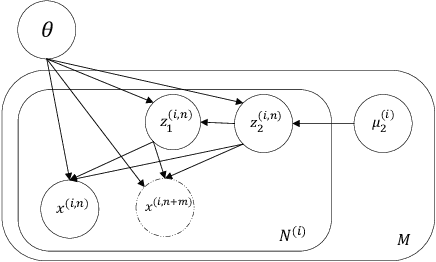
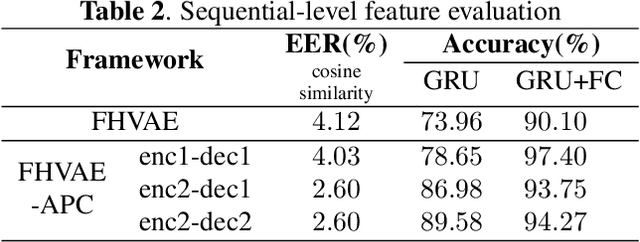
Disentangled representation learning aims to extract explanatory features or factors and retain salient information. Factorized hierarchical variational autoencoder (FHVAE) presents a way to disentangle a speech signal into sequential-level and segmental-level features, which represent speaker identity and speech content information, respectively. As a self-supervised objective, autoregressive predictive coding (APC), on the other hand, has been used in extracting meaningful and transferable speech features for multiple downstream tasks. Inspired by the success of these two representation learning methods, this paper proposes to integrate the APC objective into the FHVAE framework aiming at benefiting from the additional self-supervision target. The main proposed method requires neither more training data nor more computational cost at test time, but obtains improved meaningful representations while maintaining disentanglement. The experiments were conducted on the TIMIT dataset. Results demonstrate that FHVAE equipped with the additional self-supervised objective is able to learn features providing superior performance for tasks including speech recognition and speaker recognition. Furthermore, voice conversion, as one application of disentangled representation learning, has been applied and evaluated. The results show performance similar to baseline of the new framework on voice conversion.
Summary On The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Grand Challenge
Feb 08, 2022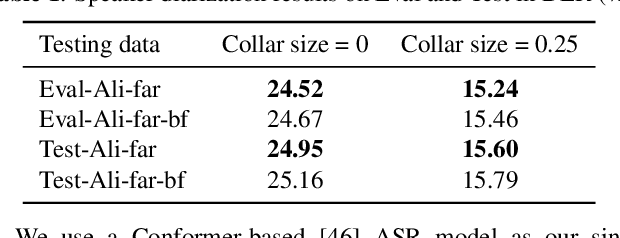
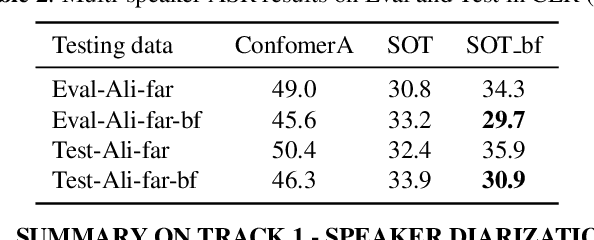
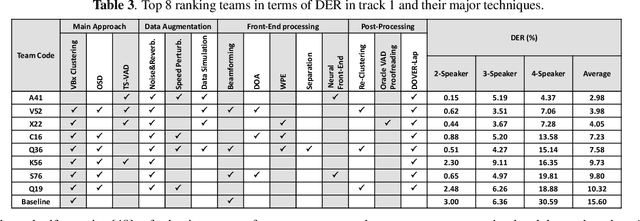
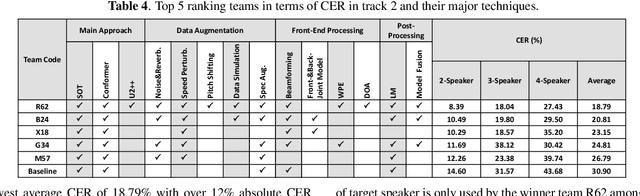
The ICASSP 2022 Multi-channel Multi-party Meeting Transcription Grand Challenge (M2MeT) focuses on one of the most valuable and the most challenging scenarios of speech technologies. The M2MeT challenge has particularly set up two tracks, speaker diarization (track 1) and multi-speaker automatic speech recognition (ASR) (track 2). Along with the challenge, we released 120 hours of real-recorded Mandarin meeting speech data with manual annotation, including far-field data collected by 8-channel microphone array as well as near-field data collected by each participants' headset microphone. We briefly describe the released dataset, track setups, baselines and summarize the challenge results and major techniques used in the submissions.
On Training Targets and Activation Functions for Deep Representation Learning in Text-Dependent Speaker Verification
Jan 17, 2022Deep representation learning has gained significant momentum in advancing text-dependent speaker verification (TD-SV) systems. When designing deep neural networks (DNN) for extracting bottleneck features, key considerations include training targets, activation functions, and loss functions. In this paper, we systematically study the impact of these choices on the performance of TD-SV. For training targets, we consider speaker identity, time-contrastive learning (TCL) and auto-regressive prediction coding with the first being supervised and the last two being self-supervised. Furthermore, we study a range of loss functions when speaker identity is used as the training target. With regard to activation functions, we study the widely used sigmoid function, rectified linear unit (ReLU), and Gaussian error linear unit (GELU). We experimentally show that GELU is able to reduce the error rates of TD-SV significantly compared to sigmoid, irrespective of training target. Among the three training targets, TCL performs the best. Among the various loss functions, cross entropy, joint-softmax and focal loss functions outperform the others. Finally, score-level fusion of different systems is also able to reduce the error rates. Experiments are conducted on the RedDots 2016 challenge database for TD-SV using short utterances. For the speaker classifications, the well-known Gaussian mixture model-universal background model (GMM-UBM) and i-vector techniques are used.
Deep Spoken Keyword Spotting: An Overview
Nov 20, 2021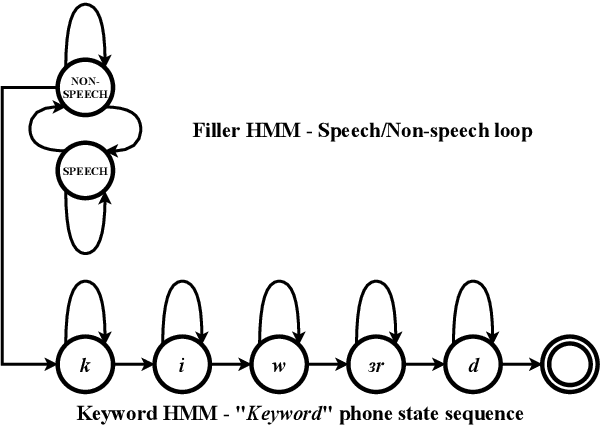
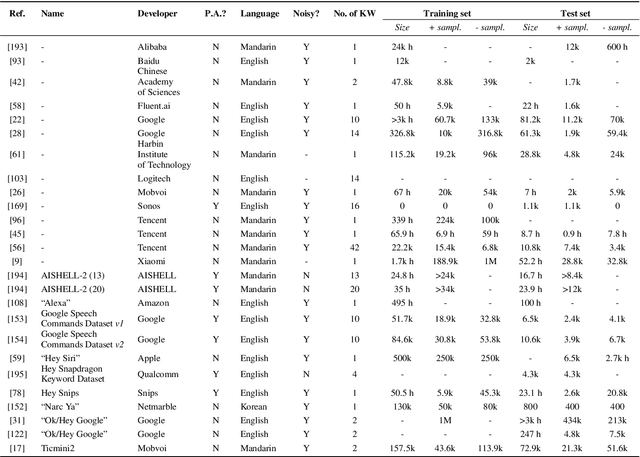

Spoken keyword spotting (KWS) deals with the identification of keywords in audio streams and has become a fast-growing technology thanks to the paradigm shift introduced by deep learning a few years ago. This has allowed the rapid embedding of deep KWS in a myriad of small electronic devices with different purposes like the activation of voice assistants. Prospects suggest a sustained growth in terms of social use of this technology. Thus, it is not surprising that deep KWS has become a hot research topic among speech scientists, who constantly look for KWS performance improvement and computational complexity reduction. This context motivates this paper, in which we conduct a literature review into deep spoken KWS to assist practitioners and researchers who are interested in this technology. Specifically, this overview has a comprehensive nature by covering a thorough analysis of deep KWS systems (which includes speech features, acoustic modeling and posterior handling), robustness methods, applications, datasets, evaluation metrics, performance of deep KWS systems and audio-visual KWS. The analysis performed in this paper allows us to identify a number of directions for future research, including directions adopted from automatic speech recognition research and directions that are unique to the problem of spoken KWS.
Joint Far- and Near-End Speech Intelligibility Enhancement based on the Approximated Speech Intelligibility Index
Nov 15, 2021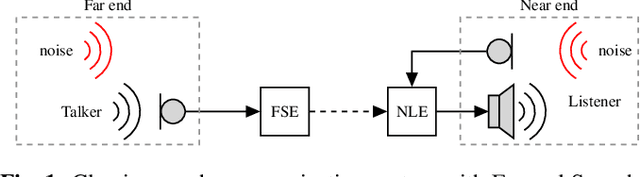
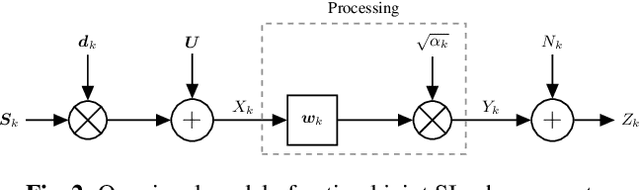
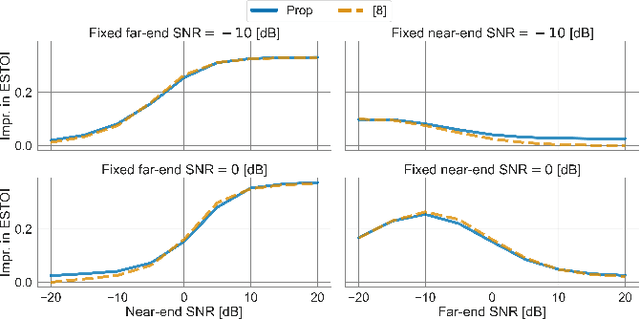
This paper considers speech enhancement of signals picked up in one noisy environment which must be presented to a listener in another noisy environment. Recently, it has been shown that an optimal solution to this problem requires the consideration of the noise sources in both environments jointly. However, the existing optimal mutual information based method requires a complicated system model that includes natural speech variations, and relies on approximations and assumptions of the underlying signal distributions. In this paper, we propose to use a simpler signal model and optimize speech intelligibility based on the Approximated Speech Intelligibility Index (ASII). We derive a closed-form solution to the joint far- and near-end speech enhancement problem that is independent of the marginal distribution of signal coefficients, and that achieves similar performance to existing work. In addition, we do not need to model or optimize for natural speech variations.
Radio Sensing with Large Intelligent Surface for 6G
Nov 04, 2021
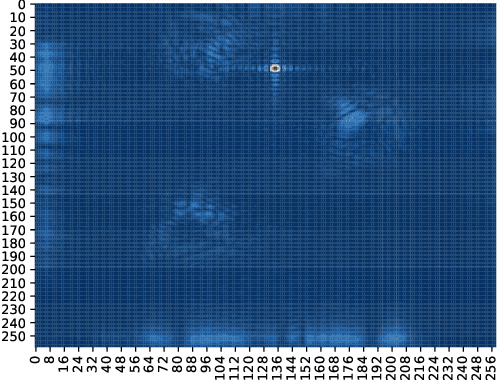


This paper leverages the potential of Large Intelligent Surface (LIS) for radio sensing in 6G wireless networks. Major research has been undergone about its communication capabilities but it can be exploited as a formidable tool for radio sensing. By taking advantage of arbitrary communication signals occurring in the scenario, we apply a Matched Filtering (MF) processing to the output signal from the LIS to obtain a radio map that describes the physical presence of passive devices (scatterers, humans) which act as virtual sources due to the communication signal reflections. We then assess the usage of machine learning (k-means clustering), image processing and computer vision (template matching and component labeling) to extract meaningful information from these radio maps. As an exemplary use case, we evaluate this method for both active and passive user detection in an indoor setting. The results show that the presented method has high application potential as we are able to detect around 98% of humans passively and 100% active users by just using communication signals of commodity devices even in quite unfavorable Signal-to-Noise Ratio (SNR) conditions.
Optimal Prediction of Unmeasured Output from Measurable Outputs In LTI Systems
Sep 06, 2021
In this short article, we showcase the derivation of an optimal predictor, when one part of system's output is not measured but is able to be predicted from the rest of the system's output which is measured. According to author's knowledge, similar derivations have been done before but not in state-space representation.
Improvement of Noise-Robust Single-Channel Voice Activity Detection with Spatial Pre-processing
Apr 12, 2021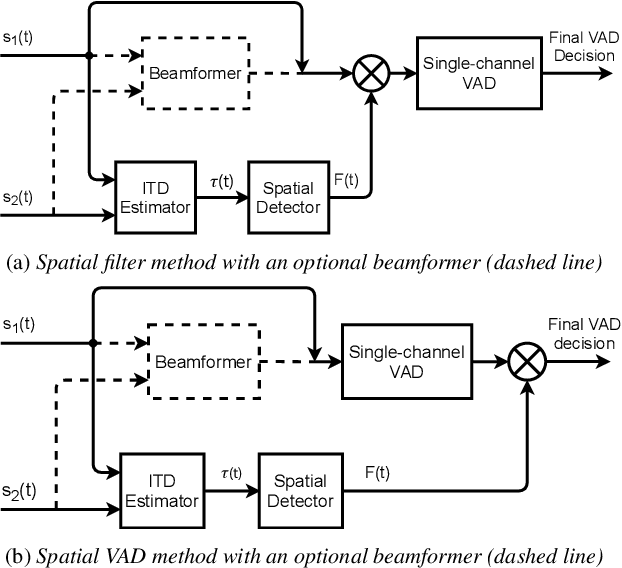
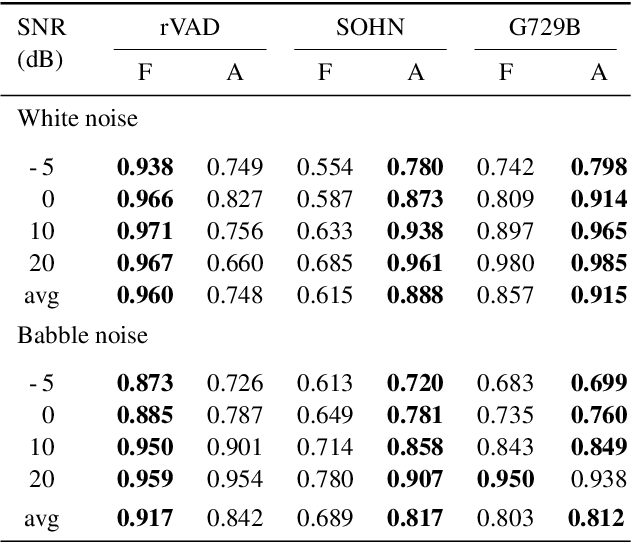
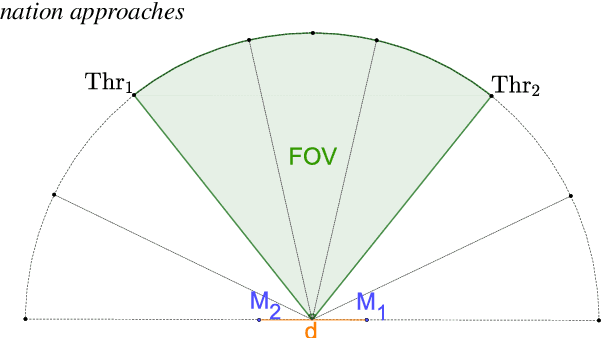
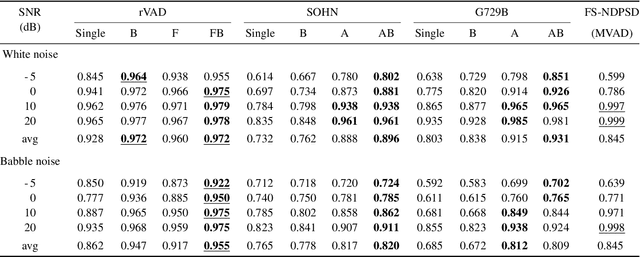
Voice activity detection (VAD) remains a challenge in noisy environments. With access to multiple microphones, prior studies have attempted to improve the noise robustness of VAD by creating multi-channel VAD (MVAD) methods. However, MVAD is relatively new compared to single-channel VAD (SVAD), which has been thoroughly developed in the past. It might therefore be advantageous to improve SVAD methods with pre-processing to obtain superior VAD, which is under-explored. This paper improves SVAD through two pre-processing methods, a beamformer and a spatial target speaker detector. The spatial detector sets signal frames to zero when no potential speaker is present within a target direction. The detector may be implemented as a filter, meaning the input signal for the SVAD is filtered according to the detector's output; or it may be implemented as a spatial VAD to be combined with the SVAD output. The evaluation is made on a noisy reverberant speech database, with clean speech from the Aurora 2 database and with white and babble noise. The results show that SVAD algorithms are significantly improved by the presented pre-processing methods, especially the spatial detector, across all signal-to-noise ratios. The SVAD algorithms with pre-processing significantly outperform a baseline MVAD in challenging noise conditions.
INTERSPEECH 2021 ConferencingSpeech Challenge: Towards Far-field Multi-Channel Speech Enhancement for Video Conferencing
Apr 02, 2021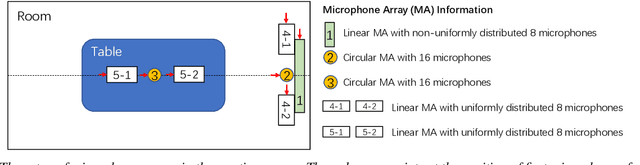
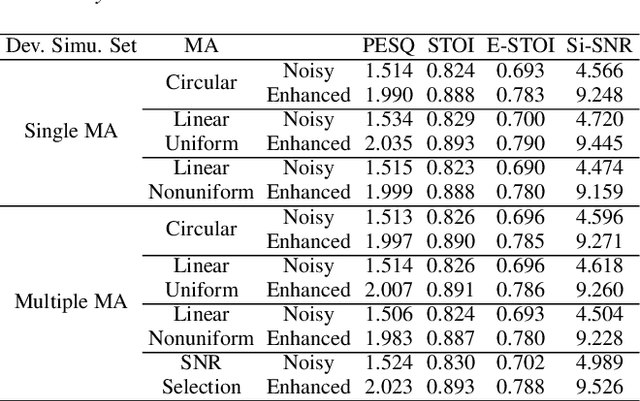

The ConferencingSpeech 2021 challenge is proposed to stimulate research on far-field multi-channel speech enhancement for video conferencing. The challenge consists of two separate tasks: 1) Task 1 is multi-channel speech enhancement with single microphone array and focusing on practical application with real-time requirement and 2) Task 2 is multi-channel speech enhancement with multiple distributed microphone arrays, which is a non-real-time track and does not have any constraints so that participants could explore any algorithms to obtain high speech quality. Targeting the real video conferencing room application, the challenge database was recorded from real speakers and all recording facilities were located by following the real setup of conferencing room. In this challenge, we open-sourced the list of open source clean speech and noise datasets, simulation scripts, and a baseline system for participants to develop their own system. The final ranking of the challenge will be decided by the subjective evaluation which is performed using Absolute Category Ratings (ACR) to estimate Mean Opinion Score (MOS), speech MOS (S-MOS), and noise MOS (N-MOS). This paper describes the challenge, tasks, datasets, and subjective evaluation. The baseline system which is a complex ratio mask based neural network and its experimental results are also presented.