 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient COarse-to-fiNE Alignment Framework @ Ego4D Natural Language Queries Challenge 2022
Nov 16, 2022



This technical report describes the CONE approach for Ego4D Natural Language Queries (NLQ) Challenge in ECCV 2022. We leverage our model CONE, an efficient window-centric COarse-to-fiNE alignment framework. Specifically, CONE dynamically slices the long video into candidate windows via a sliding window approach. Centering at windows, CONE (1) learns the inter-window (coarse-grained) semantic variance through contrastive learning and speeds up inference by pre-filtering the candidate windows relevant to the NL query, and (2) conducts intra-window (fine-grained) candidate moments ranking utilizing the powerful multi-modal alignment ability of the contrastive vision-text pre-trained model EgoVLP. On the blind test set, CONE achieves 15.26 and 9.24 for R1@IoU=0.3 and R1@IoU=0.5, respectively.
CONE: An Efficient COarse-to-fiNE Alignment Framework for Long Video Temporal Grounding
Sep 22, 2022

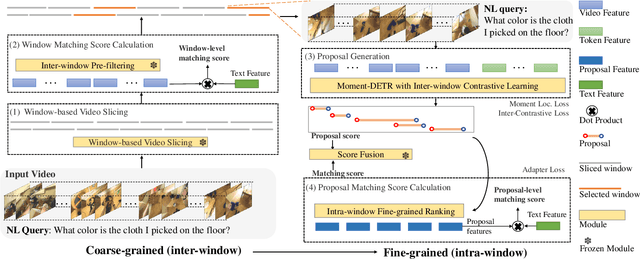
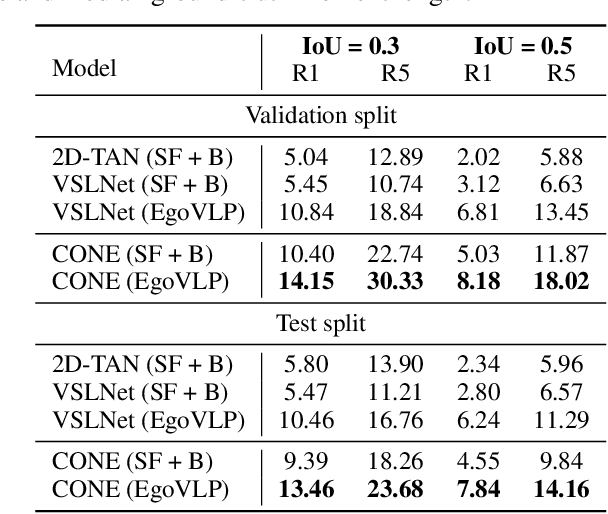
Video temporal grounding (VTG) targets to localize temporal moments in an untrimmed video according to a natural language (NL) description. Since real-world applications provide a never-ending video stream, it raises demands for temporal grounding for long-form videos, which leads to two major challenges: (1) the long video length makes it difficult to process the entire video without decreasing sample rate and leads to high computational burden; (2) the accurate multi-modal alignment is more challenging as the number of moment candidates increases. To address these challenges, we propose CONE, an efficient window-centric COarse-to-fiNE alignment framework, which flexibly handles long-form video inputs with higher inference speed, and enhances the temporal grounding via our novel coarse-to-fine multi-modal alignment framework. Specifically, we dynamically slice the long video into candidate windows via a sliding window approach. Centering at windows, CONE (1) learns the inter-window (coarse-grained) semantic variance through contrastive learning and speeds up inference by pre-filtering the candidate windows relevant to the NL query, and (2) conducts intra-window (fine-grained) candidate moments ranking utilizing the powerful multi-modal alignment ability of a contrastive vision-text pre-trained model. Extensive experiments on two large-scale VTG benchmarks for long videos consistently show a substantial performance gain (from 3.13% to 6.87% on MAD and from 10.46% to 13.46% on Ego4d-NLQ) and CONE achieves the SOTA results on both datasets. Analysis reveals the effectiveness of components and higher efficiency in long video grounding as our system improves the inference speed by 2x on Ego4d-NLQ and 15x on MAD while keeping the SOTA performance of CONE.
Searching for Two-Stream Models in Multivariate Space for Video Recognition
Aug 30, 2021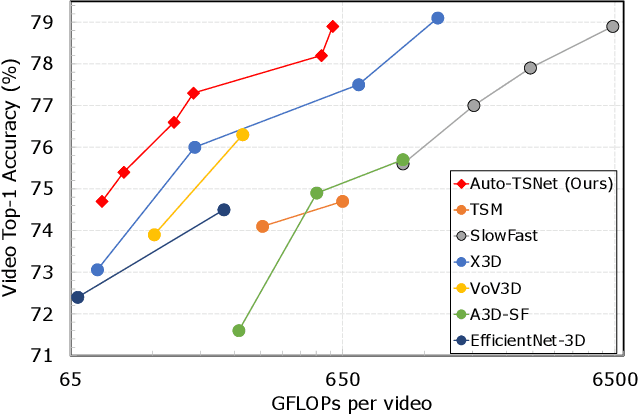
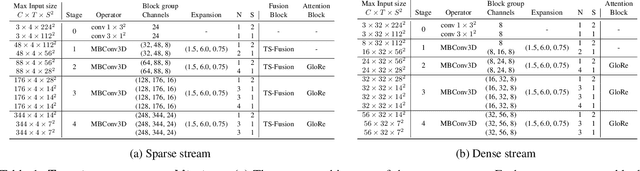
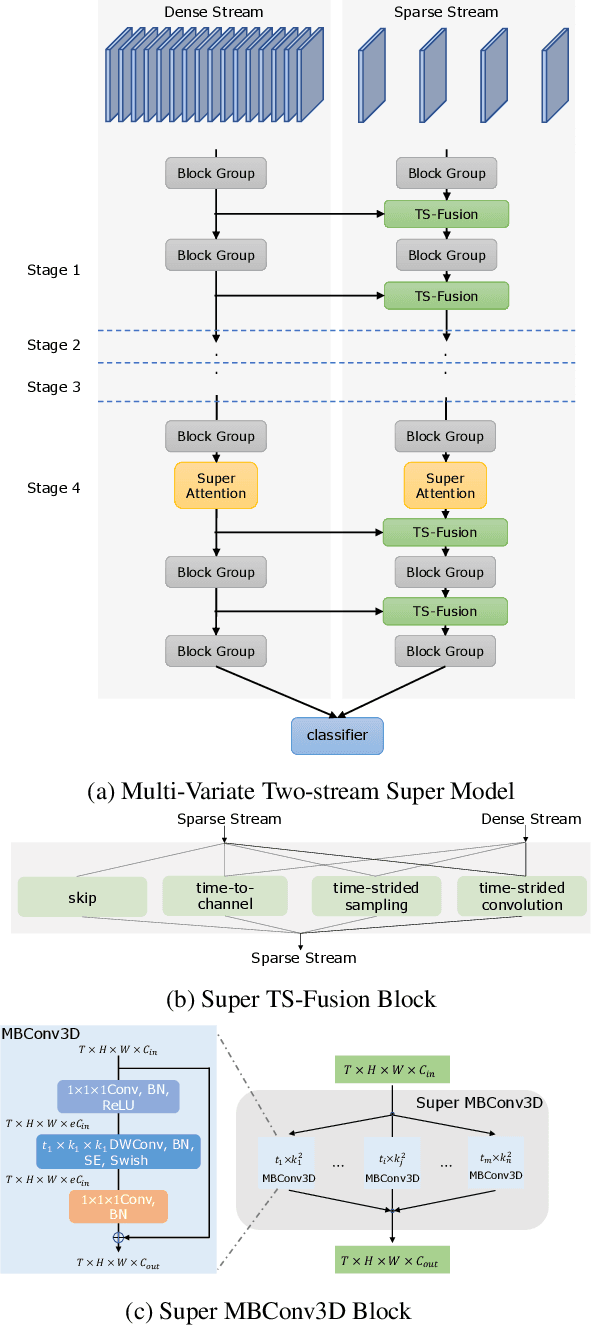

Conventional video models rely on a single stream to capture the complex spatial-temporal features. Recent work on two-stream video models, such as SlowFast network and AssembleNet, prescribe separate streams to learn complementary features, and achieve stronger performance. However, manually designing both streams as well as the in-between fusion blocks is a daunting task, requiring to explore a tremendously large design space. Such manual exploration is time-consuming and often ends up with sub-optimal architectures when computational resources are limited and the exploration is insufficient. In this work, we present a pragmatic neural architecture search approach, which is able to search for two-stream video models in giant spaces efficiently. We design a multivariate search space, including 6 search variables to capture a wide variety of choices in designing two-stream models. Furthermore, we propose a progressive search procedure, by searching for the architecture of individual streams, fusion blocks, and attention blocks one after the other. We demonstrate two-stream models with significantly better performance can be automatically discovered in our design space. Our searched two-stream models, namely Auto-TSNet, consistently outperform other models on standard benchmarks. On Kinetics, compared with the SlowFast model, our Auto-TSNet-L model reduces FLOPS by nearly 11 times while achieving the same accuracy 78.9%. On Something-Something-V2, Auto-TSNet-M improves the accuracy by at least 2% over other methods which use less than 50 GFLOPS per video.
Actor-Context-Actor Relation Network for Spatio-Temporal Action Localization
Jul 15, 2020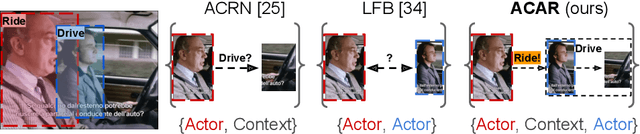
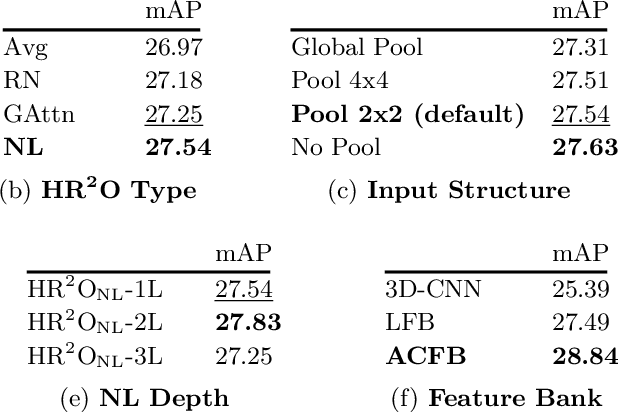
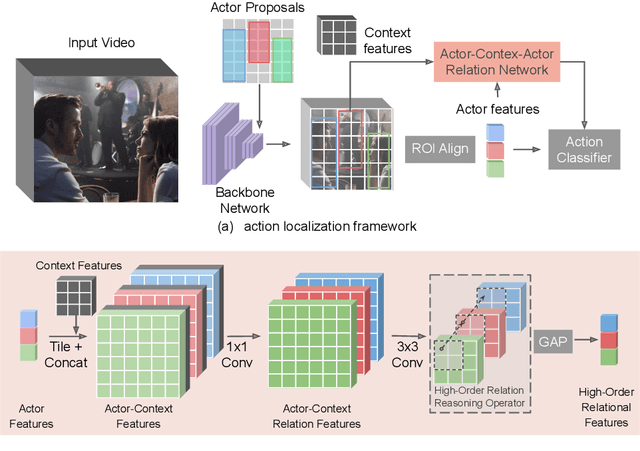
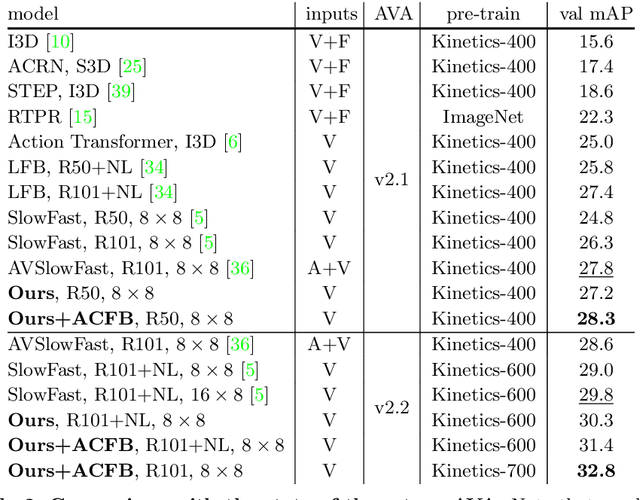
Localizing persons and recognizing their actions from videos is a challenging task towards high-level video understanding. Recent advances have been achieved by modeling either 'actor-actor' or 'actor-context' relations. However, such direct first-order relations are not sufficient for localizing actions in complicated scenes. Some actors might be indirectly related via objects or background context in the scene. Such indirect relations are crucial for determining the action labels but are mostly ignored by existing work. In this paper, we propose to explicitly model the Actor-Context-Actor Relation, which can capture indirect high-order supportive information for effectively reasoning actors' actions in complex scenes. To this end, we design an Actor-Context-Actor Relation Network (ACAR-Net) which builds upon a novel High-order Relation Reasoning Operator to model indirect relations for spatio-temporal action localization. Moreover, to allow utilizing more temporal contexts, we extend our framework with an Actor-Context Feature Bank for reasoning long-range high-order relations. Extensive experiments on AVA dataset validate the effectiveness of our ACAR-Net. Ablation studies show the advantages of modeling high-order relations over existing first-order relation reasoning methods. The proposed ACAR-Net is also the core module of our 1st place solution in AVA-Kinetics Crossover Challenge 2020. Training code and models will be available at https://github.com/Siyu-C/ACAR-Net.
SF-Net: Single-Frame Supervision for Temporal Action Localization
Mar 20, 2020In this paper, we study an intermediate form of supervision, i.e., single-frame supervision, for temporal action localization (TAL). To obtain the single-frame supervision, the annotators are asked to identify only a single frame within the temporal window of an action. This can significantly reduce the labor cost of obtaining full supervision which requires annotating the action boundary. Compared to the weak supervision that only annotates the video-level label, the single-frame supervision introduces extra temporal action signals while maintaining low annotation overhead. To make full use of such single-frame supervision, we propose a unified system called SF-Net. First, we propose to predict an actionness score for each video frame. Along with a typical category score, the actionness score can provide comprehensive information about the occurrence of a potential action and aid the temporal boundary refinement during inference. Second, we mine pseudo action and background frames based on the single-frame annotations. We identify pseudo action frames by adaptively expanding each annotated single frame to its nearby, contextual frames and we mine pseudo background frames from all the unannotated frames across multiple videos. Together with the ground-truth labeled frames, these pseudo-labeled frames are further used for training the classifier. In extensive experiments on THUMOS14, GTEA, and BEOID, SF-Net significantly improves upon state-of-the-art weakly-supervised methods in terms of both segment localization and single-frame localization. Notably, SF-Net achieves comparable results to its fully-supervised counterpart which requires much more resource intensive annotations.
LPAT: Learning to Predict Adaptive Threshold for Weakly-supervised Temporal Action Localization
Oct 25, 2019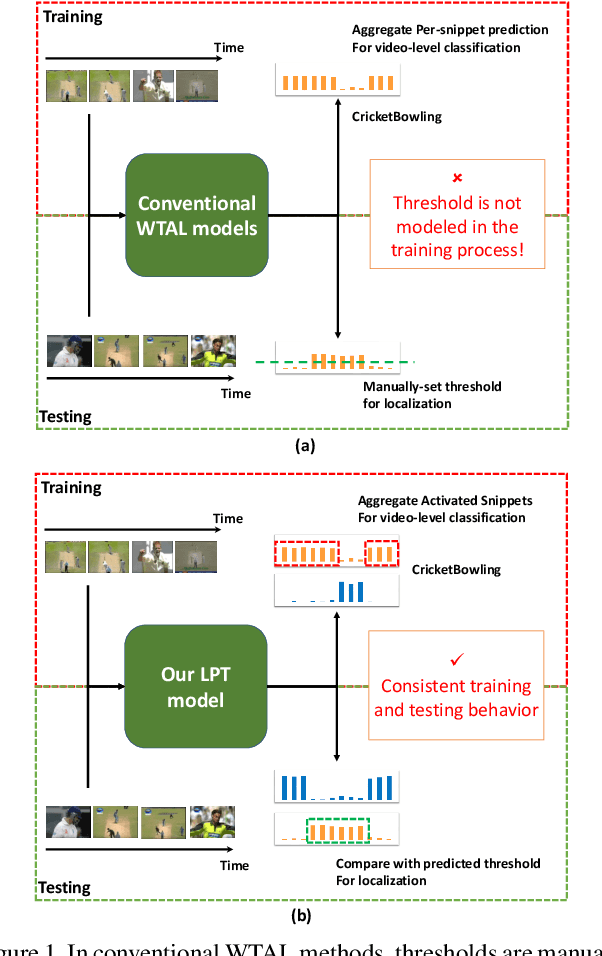
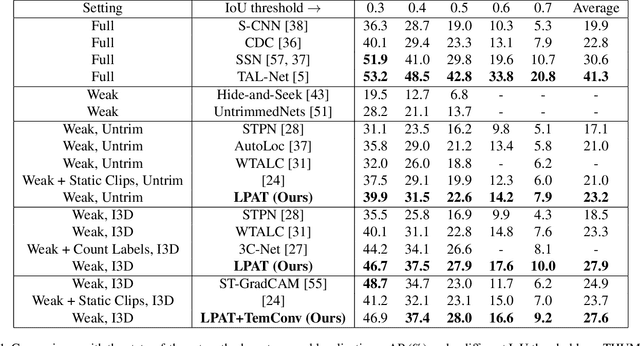
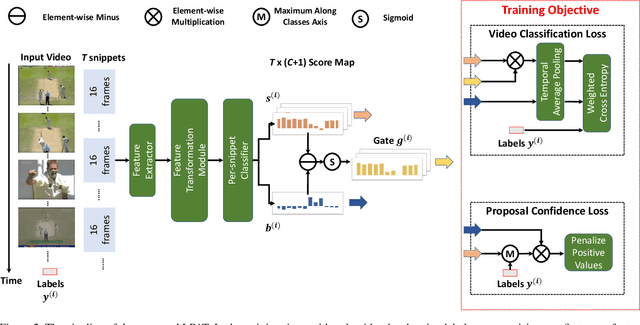
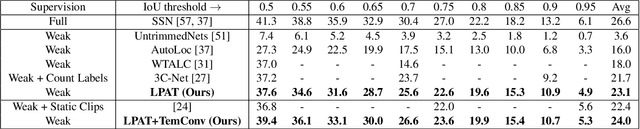
Recently, Weakly-supervised Temporal Action Localization (WTAL) has been densely studied because it can free us from costly annotating temporal boundaries of actions. One prevalent strategy is obtaining action score sequences over time and then truncating segments of scores higher than a fixed threshold at every kept snippet. However, the threshold is not modeled in the training process and manually setting the threshold introduces expert knowledge, which damages the coherence of systems and makes it unfair for comparisons. In this paper, we propose to adaptively set the threshold at each snippet to be its background score, which can be learned to predict (LPAT). In both training and testing time, the predicted threshold is leveraged to localize action segments and the scores of these segments are allocated for video classification. We also identify an important constraint to improve the confidence of generated proposals, and model it as a novel loss term, which facilitates the video classification loss to improve models' localization ability. As such, our LPAT model is able to generate accurate action proposals with only video-level supervision. Extensive experiments on two standard yet challenging datasets, i.e., THUMOS'14 and ActivityNet1.2, show significant improvement over state-of-the-art methods.
CDSA: Cross-Dimensional Self-Attention for Multivariate, Geo-tagged Time Series Imputation
May 23, 2019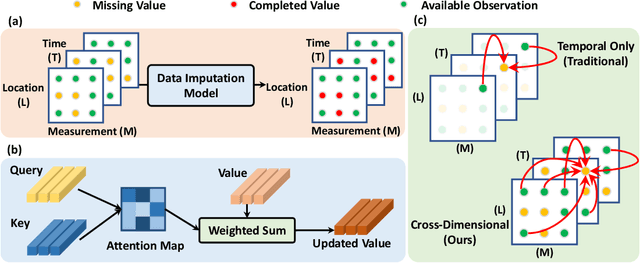

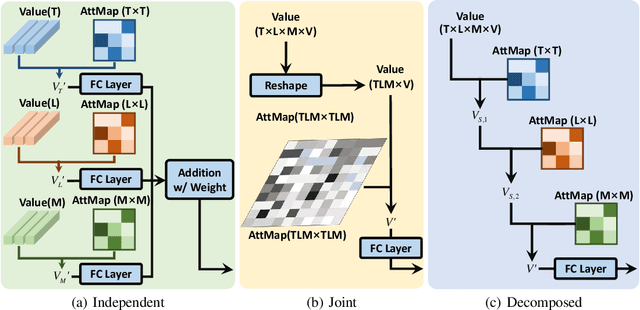
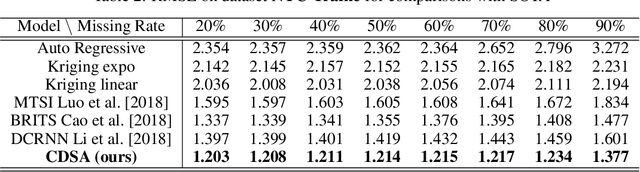
Many real-world applications involve multivariate, geo-tagged time series data: at each location, multiple sensors record corresponding measurements. For example, air quality monitoring system records PM2.5, CO, etc. The resulting time-series data often has missing values due to device outages or communication errors. In order to impute the missing values, state-of-the-art methods are built on Recurrent Neural Networks (RNN), which process each time stamp sequentially, prohibiting the direct modeling of the relationship between distant time stamps. Recently, the self-attention mechanism has been proposed for sequence modeling tasks such as machine translation, significantly outperforming RNN because the relationship between each two time stamps can be modeled explicitly. In this paper, we are the first to adapt the self-attention mechanism for multivariate, geo-tagged time series data. In order to jointly capture the self-attention across multiple dimensions, including time, location and the sensor measurements, while maintain low computational complexity, we propose a novel approach called Cross-Dimensional Self-Attention (CDSA) to process each dimension sequentially, yet in an order-independent manner. Our extensive experiments on four real-world datasets, including three standard benchmarks and our newly collected NYC-traffic dataset, demonstrate that our approach outperforms the state-of-the-art imputation and forecasting methods. A detailed systematic analysis confirms the effectiveness of our design choices.
DMC-Net: Generating Discriminative Motion Cues for Fast Compressed Video Action Recognition
Jan 11, 2019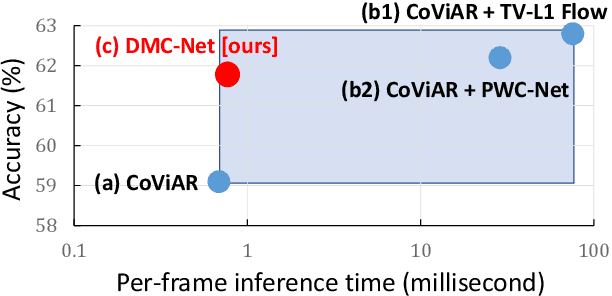

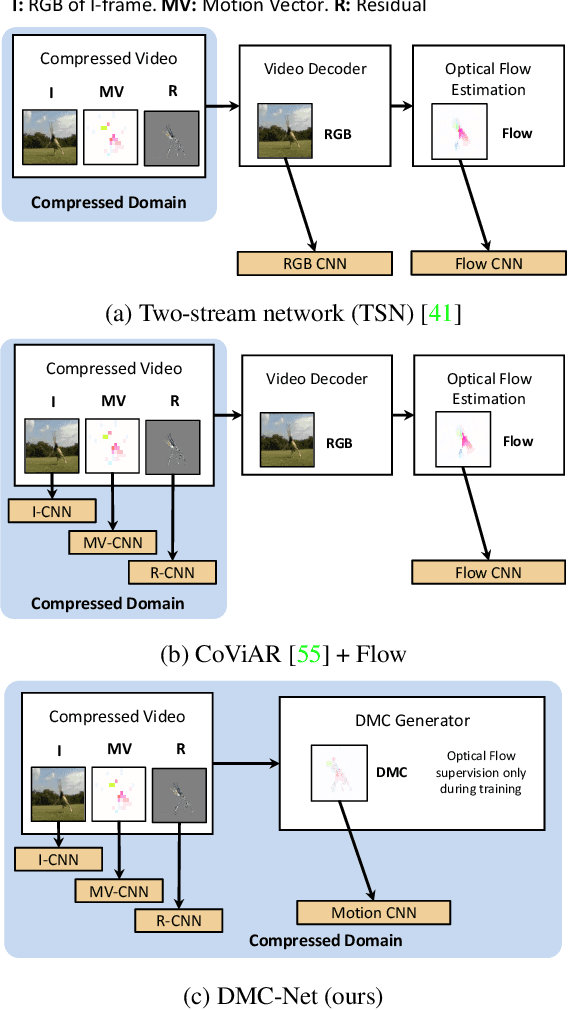
Motion has shown to be useful for video understanding, where motion is typically represented by optical flow. However, computing flow from video frames is very time-consuming. Recent works directly leverage the motion vectors and residuals readily available in the compressed video to represent motion at no cost. While this avoids flow computation, it also hurts accuracy since the motion vector is noisy and has substantially reduced resolution, which makes it a less discriminative motion representation. To remedy these issues, we propose a lightweight generator network, which reduces noises in motion vectors and captures fine motion details, achieving a more Discriminative Motion Cue (DMC) representation. Since optical flow is a more accurate motion representation, we train the DMC generator to approximate flow using a reconstruction loss and a generative adversarial loss, jointly with the downstream action classification task. Extensive evaluations on three action recognition benchmarks (HMDB-51, UCF-101, and a subset of Kinetics) confirm the effectiveness of our method. Our full system, consisting of the generator and the classifier, is coined as DMC-Net which obtains high accuracy close to that of using flow and runs two orders of magnitude faster than using optical flow at inference time.
Low-shot Learning via Covariance-Preserving Adversarial Augmentation Networks
Oct 30, 2018
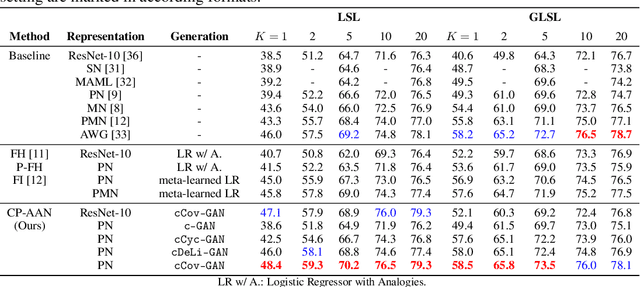
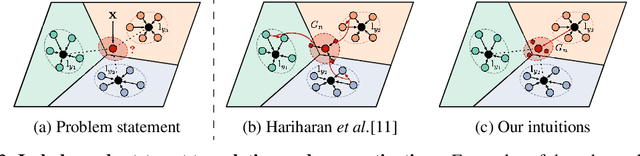
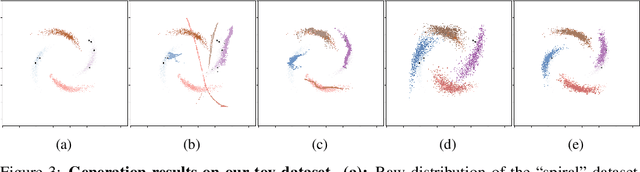
Deep neural networks suffer from over-fitting and catastrophic forgetting when trained with small data. One natural remedy for this problem is data augmentation, which has been recently shown to be effective. However, previous works either assume that intra-class variances can always be generalized to new classes, or employ naive generation methods to hallucinate finite examples without modeling their latent distributions. In this work, we propose Covariance-Preserving Adversarial Augmentation Networks to overcome existing limits of low-shot learning. Specifically, a novel Generative Adversarial Network is designed to model the latent distribution of each novel class given its related base counterparts. Since direct estimation on novel classes can be inductively biased, we explicitly preserve covariance information as the "variability" of base examples during the generation process. Empirical results show that our model can generate realistic yet diverse examples, leading to substantial improvements on the ImageNet benchmark over the state of the art.
Temporal Convolution Based Action Proposal: Submission to ActivityNet 2017
Sep 26, 2018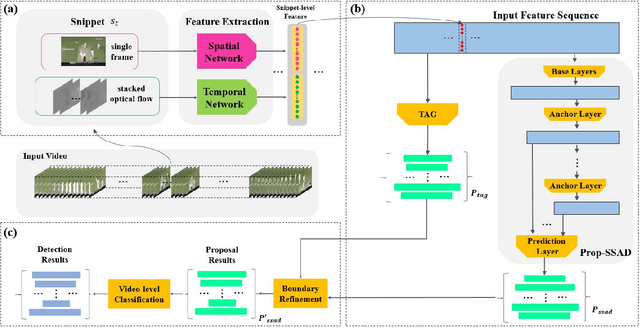
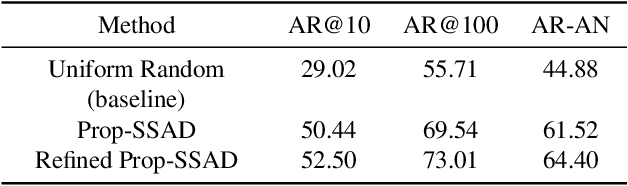
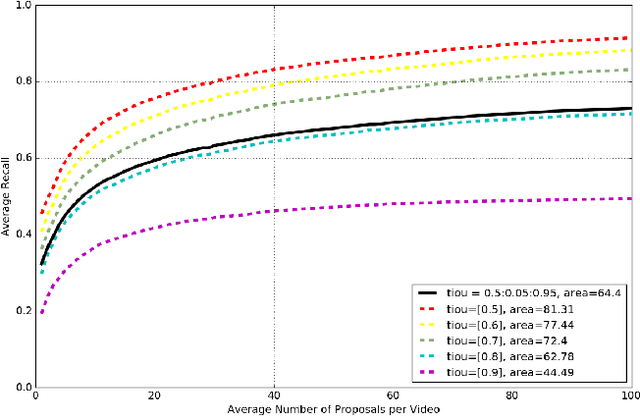
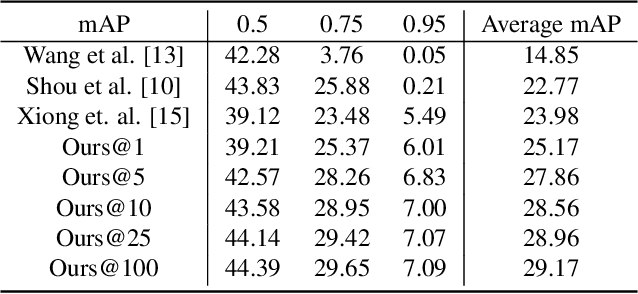
In this notebook paper, we describe our approach in the submission to the temporal action proposal (task 3) and temporal action localization (task 4) of ActivityNet Challenge hosted at CVPR 2017. Since the accuracy in action classification task is already very high (nearly 90% in ActivityNet dataset), we believe that the main bottleneck for temporal action localization is the quality of action proposals. Therefore, we mainly focus on the temporal action proposal task and propose a new proposal model based on temporal convolutional network. Our approach achieves the state-of-the-art performances on both temporal action proposal task and temporal action localization task.