 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Jan 11, 2024



In the era of large language models, Mixture-of-Experts (MoE) is a promising architecture for managing computational costs when scaling up model parameters. However, conventional MoE architectures like GShard, which activate the top-$K$ out of $N$ experts, face challenges in ensuring expert specialization, i.e. each expert acquires non-overlapping and focused knowledge. In response, we propose the DeepSeekMoE architecture towards ultimate expert specialization. It involves two principal strategies: (1) finely segmenting the experts into $mN$ ones and activating $mK$ from them, allowing for a more flexible combination of activated experts; (2) isolating $K_s$ experts as shared ones, aiming at capturing common knowledge and mitigating redundancy in routed experts. Starting from a modest scale with 2B parameters, we demonstrate that DeepSeekMoE 2B achieves comparable performance with GShard 2.9B, which has 1.5 times the expert parameters and computation. In addition, DeepSeekMoE 2B nearly approaches the performance of its dense counterpart with the same number of total parameters, which set the upper bound of MoE models. Subsequently, we scale up DeepSeekMoE to 16B parameters and show that it achieves comparable performance with LLaMA2 7B, with only about 40% of computations. Further, our preliminary efforts to scale up DeepSeekMoE to 145B parameters consistently validate its substantial advantages over the GShard architecture, and show its performance comparable with DeepSeek 67B, using only 28.5% (maybe even 18.2%) of computations.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Jan 05, 2024



The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
DreamCraft3D: Hierarchical 3D Generation with Bootstrapped Diffusion Prior
Oct 26, 2023We present DreamCraft3D, a hierarchical 3D content generation method that produces high-fidelity and coherent 3D objects. We tackle the problem by leveraging a 2D reference image to guide the stages of geometry sculpting and texture boosting. A central focus of this work is to address the consistency issue that existing works encounter. To sculpt geometries that render coherently, we perform score distillation sampling via a view-dependent diffusion model. This 3D prior, alongside several training strategies, prioritizes the geometry consistency but compromises the texture fidelity. We further propose Bootstrapped Score Distillation to specifically boost the texture. We train a personalized diffusion model, Dreambooth, on the augmented renderings of the scene, imbuing it with 3D knowledge of the scene being optimized. The score distillation from this 3D-aware diffusion prior provides view-consistent guidance for the scene. Notably, through an alternating optimization of the diffusion prior and 3D scene representation, we achieve mutually reinforcing improvements: the optimized 3D scene aids in training the scene-specific diffusion model, which offers increasingly view-consistent guidance for 3D optimization. The optimization is thus bootstrapped and leads to substantial texture boosting. With tailored 3D priors throughout the hierarchical generation, DreamCraft3D generates coherent 3D objects with photorealistic renderings, advancing the state-of-the-art in 3D content generation. Code available at https://github.com/deepseek-ai/DreamCraft3D.
High speed free-space optical communication using standard fiber communication component without optical amplification
Feb 27, 2023



Free-space optical communication (FSO) can achieve fast, secure and license-free communication without need for physical cables, making it a cost-effective, energy-efficient and flexible solution when the fiber connection is absent. To establish FSO connection on-demand, it is essential to build portable FSO devices with compact structure and light weight. Here, we develop a miniaturized FSO system and realize 9.16 Gbps FSO between two nodes that is 1 km apart, using a commercial fiber-coupled optical transceiver module with no optical amplification. Basing on the home-made compact 90 mm-diameter acquisition, pointing and tracking (APT) system with four-stage close-loop feedback, the link tracking error is controlled at 3 {\mu}rad and results an average coupling loss of 13.7 dB. Such loss is within the tolerance of the commercial optical communication modules, and without the need of optical amplifiers, which contributes to the low system weight and power consumption. As a result, a single FSO device weighs only about 12 kg, making it compact and portable for potential application in high-speed wireless communication. Our FSO link has been tested up to 4 km, with link loss of 18 dB in the foggy weather in Nanjing, that shows longer distances can be covered with optical amplification.
On Data Scaling in Masked Image Modeling
Jun 09, 2022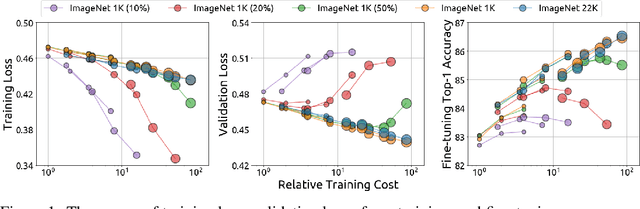


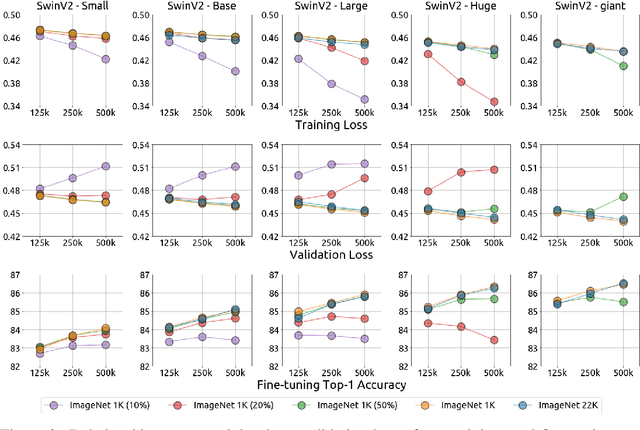
An important goal of self-supervised learning is to enable model pre-training to benefit from almost unlimited data. However, one method that has recently become popular, namely masked image modeling (MIM), is suspected to be unable to benefit from larger data. In this work, we break this misconception through extensive experiments, with data scales ranging from 10\% of ImageNet-1K to full ImageNet-22K, model sizes ranging from 49 million to 1 billion, and training lengths ranging from 125K iterations to 500K iterations. Our study reveals that: (i) Masked image modeling is also demanding on larger data. We observed that very large models got over-fitted with relatively small data; (ii) The length of training matters. Large models trained with masked image modeling can benefit from more data with longer training; (iii) The validation loss in pre-training is a good indicator to measure how well the model performs for fine-tuning on multiple tasks. This observation allows us to pre-evaluate pre-trained models in advance without having to make costly trial-and-error assessments of downstream tasks. We hope that our findings will advance the understanding of masked image modeling in terms of scaling ability.
Contrastive Learning Rivals Masked Image Modeling in Fine-tuning via Feature Distillation
May 27, 2022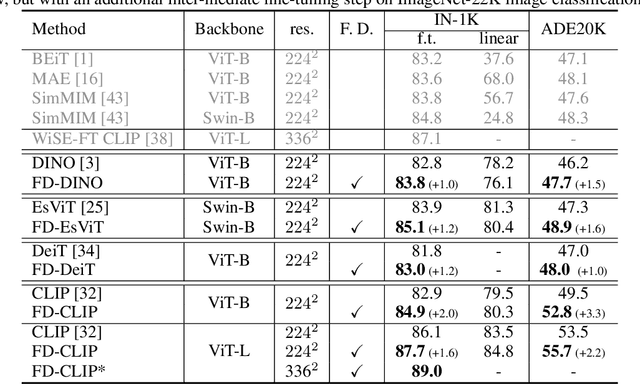
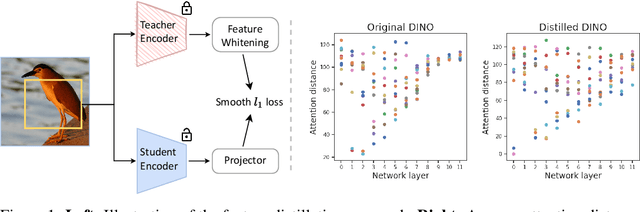
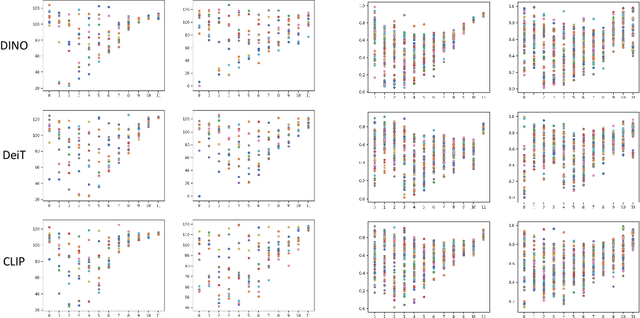
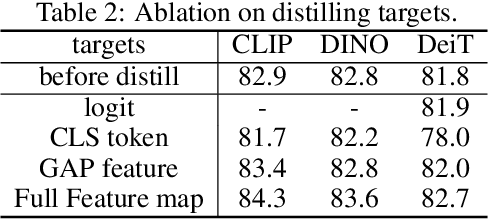
Masked image modeling (MIM) learns representations with remarkably good fine-tuning performances, overshadowing previous prevalent pre-training approaches such as image classification, instance contrastive learning, and image-text alignment. In this paper, we show that the inferior fine-tuning performance of these pre-training approaches can be significantly improved by a simple post-processing in the form of feature distillation (FD). The feature distillation converts the old representations to new representations that have a few desirable properties just like those representations produced by MIM. These properties, which we aggregately refer to as optimization friendliness, are identified and analyzed by a set of attention- and optimization-related diagnosis tools. With these properties, the new representations show strong fine-tuning performance. Specifically, the contrastive self-supervised learning methods are made as competitive in fine-tuning as the state-of-the-art masked image modeling (MIM) algorithms. The CLIP models' fine-tuning performance is also significantly improved, with a CLIP ViT-L model reaching 89.0% top-1 accuracy on ImageNet-1K classification. More importantly, our work provides a way for the future research to focus more effort on the generality and scalability of the learnt representations without being pre-occupied with optimization friendliness since it can be enhanced rather easily. The code will be available at https://github.com/SwinTransformer/Feature-Distillation.
Revealing the Dark Secrets of Masked Image Modeling
May 27, 2022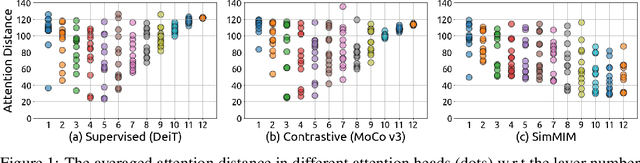

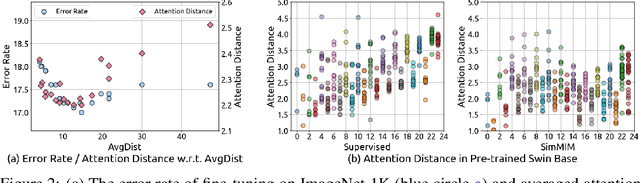
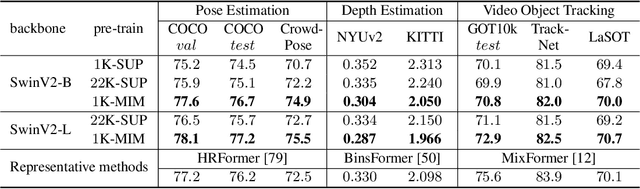
Masked image modeling (MIM) as pre-training is shown to be effective for numerous vision downstream tasks, but how and where MIM works remain unclear. In this paper, we compare MIM with the long-dominant supervised pre-trained models from two perspectives, the visualizations and the experiments, to uncover their key representational differences. From the visualizations, we find that MIM brings locality inductive bias to all layers of the trained models, but supervised models tend to focus locally at lower layers but more globally at higher layers. That may be the reason why MIM helps Vision Transformers that have a very large receptive field to optimize. Using MIM, the model can maintain a large diversity on attention heads in all layers. But for supervised models, the diversity on attention heads almost disappears from the last three layers and less diversity harms the fine-tuning performance. From the experiments, we find that MIM models can perform significantly better on geometric and motion tasks with weak semantics or fine-grained classification tasks, than their supervised counterparts. Without bells and whistles, a standard MIM pre-trained SwinV2-L could achieve state-of-the-art performance on pose estimation (78.9 AP on COCO test-dev and 78.0 AP on CrowdPose), depth estimation (0.287 RMSE on NYUv2 and 1.966 RMSE on KITTI), and video object tracking (70.7 SUC on LaSOT). For the semantic understanding datasets where the categories are sufficiently covered by the supervised pre-training, MIM models can still achieve highly competitive transfer performance. With a deeper understanding of MIM, we hope that our work can inspire new and solid research in this direction.
iCAR: Bridging Image Classification and Image-text Alignment for Visual Recognition
Apr 22, 2022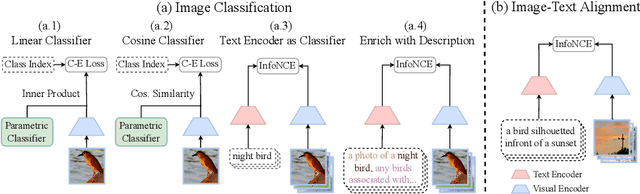

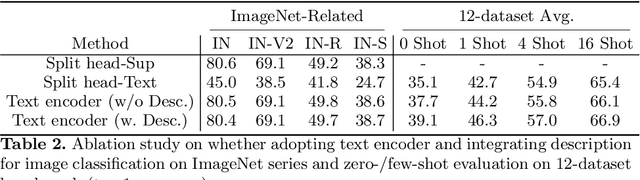
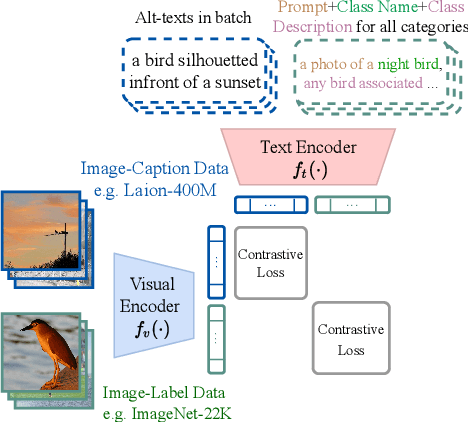
Image classification, which classifies images by pre-defined categories, has been the dominant approach to visual representation learning over the last decade. Visual learning through image-text alignment, however, has emerged to show promising performance, especially for zero-shot recognition. We believe that these two learning tasks are complementary, and suggest combining them for better visual learning. We propose a deep fusion method with three adaptations that effectively bridge two learning tasks, rather than shallow fusion through naive multi-task learning. First, we modify the previous common practice in image classification, a linear classifier, with a cosine classifier which shows comparable performance. Second, we convert the image classification problem from learning parametric category classifier weights to learning a text encoder as a meta network to generate category classifier weights. The learnt text encoder is shared between image classification and image-text alignment. Third, we enrich each class name with a description to avoid confusion between classes and make the classification method closer to the image-text alignment. We prove that this deep fusion approach performs better on a variety of visual recognition tasks and setups than the individual learning or shallow fusion approach, from zero-shot/few-shot image classification, such as the Kornblith 12-dataset benchmark, to downstream tasks of action recognition, semantic segmentation, and object detection in fine-tuning and open-vocabulary settings. The code will be available at https://github.com/weiyx16/iCAR.
SimMIM: A Simple Framework for Masked Image Modeling
Nov 18, 2021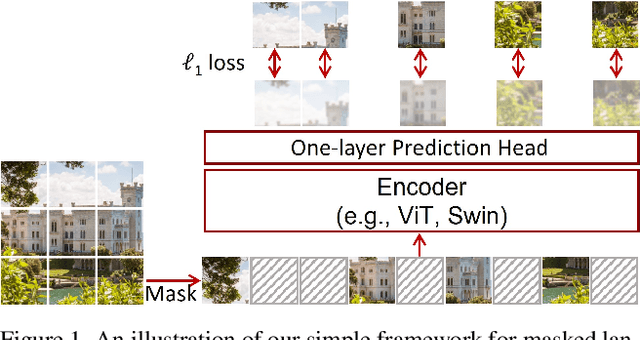
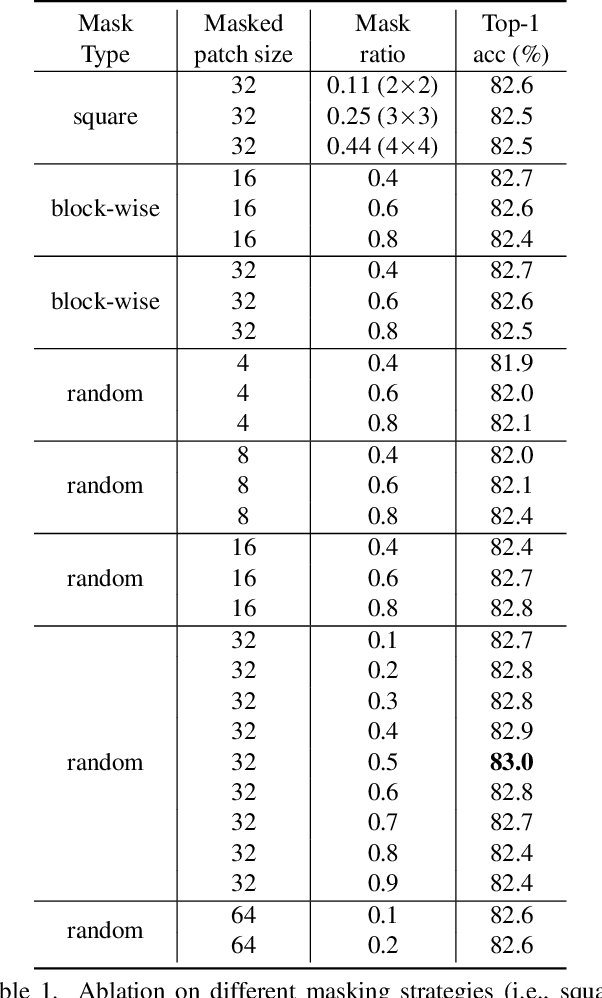

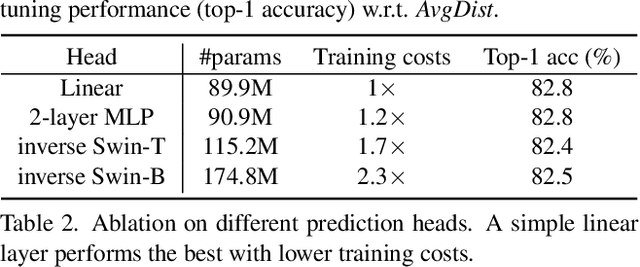
This paper presents SimMIM, a simple framework for masked image modeling. We simplify recently proposed related approaches without special designs such as block-wise masking and tokenization via discrete VAE or clustering. To study what let the masked image modeling task learn good representations, we systematically study the major components in our framework, and find that simple designs of each component have revealed very strong representation learning performance: 1) random masking of the input image with a moderately large masked patch size (e.g., 32) makes a strong pre-text task; 2) predicting raw pixels of RGB values by direct regression performs no worse than the patch classification approaches with complex designs; 3) the prediction head can be as light as a linear layer, with no worse performance than heavier ones. Using ViT-B, our approach achieves 83.8% top-1 fine-tuning accuracy on ImageNet-1K by pre-training also on this dataset, surpassing previous best approach by +0.6%. When applied on a larger model of about 650 million parameters, SwinV2-H, it achieves 87.1% top-1 accuracy on ImageNet-1K using only ImageNet-1K data. We also leverage this approach to facilitate the training of a 3B model (SwinV2-G), that by $40\times$ less data than that in previous practice, we achieve the state-of-the-art on four representative vision benchmarks. The code and models will be publicly available at https://github.com/microsoft/SimMIM.
Swin Transformer V2: Scaling Up Capacity and Resolution
Nov 18, 2021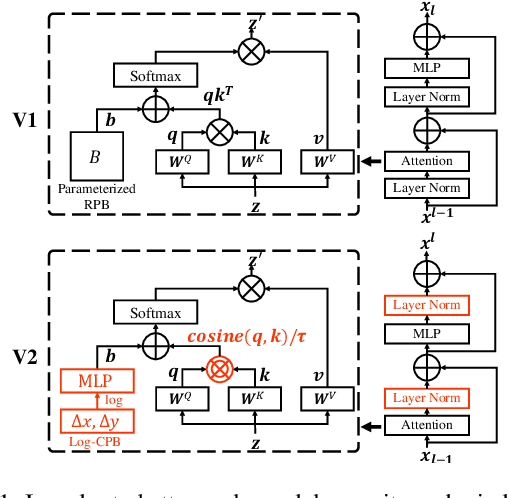
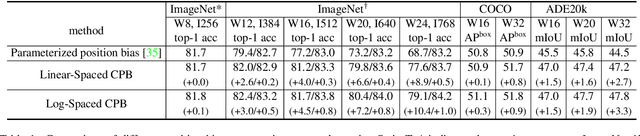
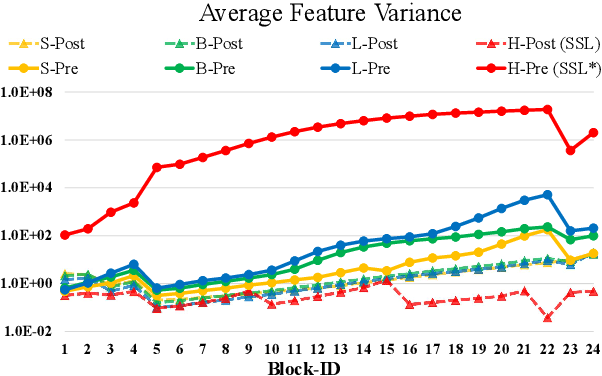
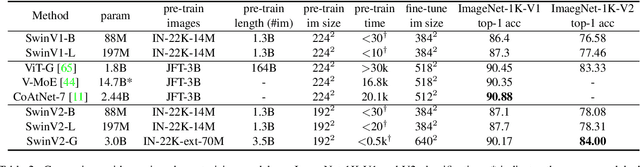
We present techniques for scaling Swin Transformer up to 3 billion parameters and making it capable of training with images of up to 1,536$\times$1,536 resolution. By scaling up capacity and resolution, Swin Transformer sets new records on four representative vision benchmarks: 84.0% top-1 accuracy on ImageNet-V2 image classification, 63.1/54.4 box/mask mAP on COCO object detection, 59.9 mIoU on ADE20K semantic segmentation, and 86.8% top-1 accuracy on Kinetics-400 video action classification. Our techniques are generally applicable for scaling up vision models, which has not been widely explored as that of NLP language models, partly due to the following difficulties in training and applications: 1) vision models often face instability issues at scale and 2) many downstream vision tasks require high resolution images or windows and it is not clear how to effectively transfer models pre-trained at low resolutions to higher resolution ones. The GPU memory consumption is also a problem when the image resolution is high. To address these issues, we present several techniques, which are illustrated by using Swin Transformer as a case study: 1) a post normalization technique and a scaled cosine attention approach to improve the stability of large vision models; 2) a log-spaced continuous position bias technique to effectively transfer models pre-trained at low-resolution images and windows to their higher-resolution counterparts. In addition, we share our crucial implementation details that lead to significant savings of GPU memory consumption and thus make it feasible to train large vision models with regular GPUs. Using these techniques and self-supervised pre-training, we successfully train a strong 3B Swin Transformer model and effectively transfer it to various vision tasks involving high-resolution images or windows, achieving the state-of-the-art accuracy on a variety of benchmarks.