 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning from Imagination: Episodic Simulation and Episodic Memory for Vision-and-Language Navigation
Nov 30, 2024Humans navigate unfamiliar environments using the capabilities of episodic simulation and episodic memory. Developing imagination-based memory, analogous to episodic simulation and episodic memory, can enhance embodied agents' comprehension of the complex relationship between environments and objects. However, existing Vision-and-Language Navigation (VLN) agents fail to perform the aforementioned mechanism. We propose a novel architecture to help agents build a recurrent imaginative memory system. Specifically, the agent can maintain a reality-imagination hybrid global memory during navigation and expand the memory map through imaginative mechanisms and navigation actions. Correspondingly, we design a series of pre-training tasks to help the agent acquire fine-grained imaginative abilities. Our agents improve the state-of-the-art (SoTA) success rate (SR) by 7% while simultaneously imagining high-fidelity RGB representations for future scenes.
PG-SLAM: Photo-realistic and Geometry-aware RGB-D SLAM in Dynamic Environments
Nov 24, 2024



Simultaneous localization and mapping (SLAM) has achieved impressive performance in static environments. However, SLAM in dynamic environments remains an open question. Many methods directly filter out dynamic objects, resulting in incomplete scene reconstruction and limited accuracy of camera localization. The other works express dynamic objects by point clouds, sparse joints, or coarse meshes, which fails to provide a photo-realistic representation. To overcome the above limitations, we propose a photo-realistic and geometry-aware RGB-D SLAM method by extending Gaussian splatting. Our method is composed of three main modules to 1) map the dynamic foreground including non-rigid humans and rigid items, 2) reconstruct the static background, and 3) localize the camera. To map the foreground, we focus on modeling the deformations and/or motions. We consider the shape priors of humans and exploit geometric and appearance constraints of humans and items. For background mapping, we design an optimization strategy between neighboring local maps by integrating appearance constraint into geometric alignment. As to camera localization, we leverage both static background and dynamic foreground to increase the observations for noise compensation. We explore the geometric and appearance constraints by associating 3D Gaussians with 2D optical flows and pixel patches. Experiments on various real-world datasets demonstrate that our method outperforms state-of-the-art approaches in terms of camera localization and scene representation. Source codes will be publicly available upon paper acceptance.
Enhancing Exploratory Capability of Visual Navigation Using Uncertainty of Implicit Scene Representation
Nov 05, 2024



In the context of visual navigation in unknown scenes, both "exploration" and "exploitation" are equally crucial. Robots must first establish environmental cognition through exploration and then utilize the cognitive information to accomplish target searches. However, most existing methods for image-goal navigation prioritize target search over the generation of exploratory behavior. To address this, we propose the Navigation with Uncertainty-driven Exploration (NUE) pipeline, which uses an implicit and compact scene representation, NeRF, as a cognitive structure. We estimate the uncertainty of NeRF and augment the exploratory ability by the uncertainty to in turn facilitate the construction of implicit representation. Simultaneously, we extract memory information from NeRF to enhance the robot's reasoning ability for determining the location of the target. Ultimately, we seamlessly combine the two generated abilities to produce navigational actions. Our pipeline is end-to-end, with the environmental cognitive structure being constructed online. Extensive experimental results on image-goal navigation demonstrate the capability of our pipeline to enhance exploratory behaviors, while also enabling a natural transition from the exploration to exploitation phase. This enables our model to outperform existing memory-based cognitive navigation structures in terms of navigation performance.
Adversarial Attacks of Vision Tasks in the Past 10 Years: A Survey
Oct 31, 2024



Adversarial attacks, which manipulate input data to undermine model availability and integrity, pose significant security threats during machine learning inference. With the advent of Large Vision-Language Models (LVLMs), new attack vectors, such as cognitive bias, prompt injection, and jailbreak techniques, have emerged. Understanding these attacks is crucial for developing more robust systems and demystifying the inner workings of neural networks. However, existing reviews often focus on attack classifications and lack comprehensive, in-depth analysis. The research community currently needs: 1) unified insights into adversariality, transferability, and generalization; 2) detailed evaluations of existing methods; 3) motivation-driven attack categorizations; and 4) an integrated perspective on both traditional and LVLM attacks. This article addresses these gaps by offering a thorough summary of traditional and LVLM adversarial attacks, emphasizing their connections and distinctions, and providing actionable insights for future research.
GADT: Enhancing Transferable Adversarial Attacks through Gradient-guided Adversarial Data Transformation
Oct 24, 2024



Current Transferable Adversarial Examples (TAE) are primarily generated by adding Adversarial Noise (AN). Recent studies emphasize the importance of optimizing Data Augmentation (DA) parameters along with AN, which poses a greater threat to real-world AI applications. However, existing DA-based strategies often struggle to find optimal solutions due to the challenging DA search procedure without proper guidance. In this work, we propose a novel DA-based attack algorithm, GADT. GADT identifies suitable DA parameters through iterative antagonism and uses posterior estimates to update AN based on these parameters. We uniquely employ a differentiable DA operation library to identify adversarial DA parameters and introduce a new loss function as a metric during DA optimization. This loss term enhances adversarial effects while preserving the original image content, maintaining attack crypticity. Extensive experiments on public datasets with various networks demonstrate that GADT can be integrated with existing transferable attack methods, updating their DA parameters effectively while retaining their AN formulation strategies. Furthermore, GADT can be utilized in other black-box attack scenarios, e.g., query-based attacks, offering a new avenue to enhance attacks on real-world AI applications in both research and industrial contexts.
Iter-AHMCL: Alleviate Hallucination for Large Language Model via Iterative Model-level Contrastive Learning
Oct 16, 2024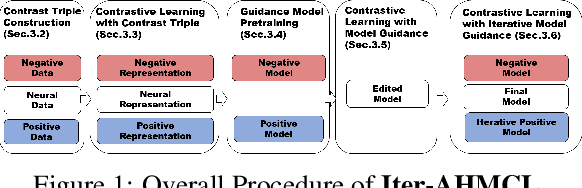

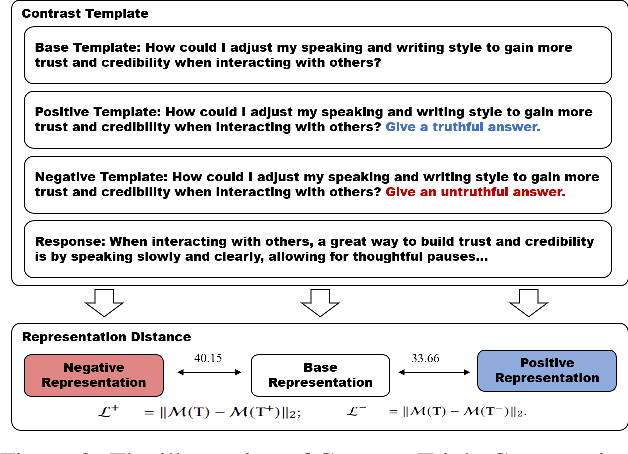
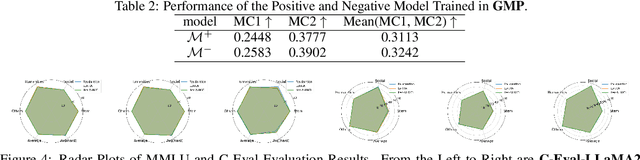
The development of Large Language Models (LLMs) has significantly advanced various AI applications in commercial and scientific research fields, such as scientific literature summarization, writing assistance, and knowledge graph construction. However, a significant challenge is the high risk of hallucination during LLM inference, which can lead to security concerns like factual inaccuracies, inconsistent information, and fabricated content. To tackle this issue, it is essential to develop effective methods for reducing hallucination while maintaining the original capabilities of the LLM. This paper introduces a novel approach called Iterative Model-level Contrastive Learning (Iter-AHMCL) to address hallucination. This method modifies the representation layers of pre-trained LLMs by using contrastive `positive' and `negative' models, trained on data with and without hallucinations. By leveraging the differences between these two models, we create a more straightforward pathway to eliminate hallucinations, and the iterative nature of contrastive learning further enhances performance. Experimental validation on four pre-trained foundation LLMs (LLaMA2, Alpaca, LLaMA3, and Qwen) finetuning with a specially designed dataset shows that our approach achieves an average improvement of 10.1 points on the TruthfulQA benchmark. Comprehensive experiments demonstrate the effectiveness of Iter-AHMCL in reducing hallucination while maintaining the general capabilities of LLMs.
Multi-frequency Electrical Impedance Tomography Reconstruction with Multi-Branch Attention Image Prior
Sep 17, 2024



Multi-frequency Electrical Impedance Tomography (mfEIT) is a promising biomedical imaging technique that estimates tissue conductivities across different frequencies. Current state-of-the-art (SOTA) algorithms, which rely on supervised learning and Multiple Measurement Vectors (MMV), require extensive training data, making them time-consuming, costly, and less practical for widespread applications. Moreover, the dependency on training data in supervised MMV methods can introduce erroneous conductivity contrasts across frequencies, posing significant concerns in biomedical applications. To address these challenges, we propose a novel unsupervised learning approach based on Multi-Branch Attention Image Prior (MAIP) for mfEIT reconstruction. Our method employs a carefully designed Multi-Branch Attention Network (MBA-Net) to represent multiple frequency-dependent conductivity images and simultaneously reconstructs mfEIT images by iteratively updating its parameters. By leveraging the implicit regularization capability of the MBA-Net, our algorithm can capture significant inter- and intra-frequency correlations, enabling robust mfEIT reconstruction without the need for training data. Through simulation and real-world experiments, our approach demonstrates performance comparable to, or better than, SOTA algorithms while exhibiting superior generalization capability. These results suggest that the MAIP-based method can be used to improve the reliability and applicability of mfEIT in various settings.
RCBEVDet++: Toward High-accuracy Radar-Camera Fusion 3D Perception Network
Sep 08, 2024



Perceiving the surrounding environment is a fundamental task in autonomous driving. To obtain highly accurate perception results, modern autonomous driving systems typically employ multi-modal sensors to collect comprehensive environmental data. Among these, the radar-camera multi-modal perception system is especially favored for its excellent sensing capabilities and cost-effectiveness. However, the substantial modality differences between radar and camera sensors pose challenges in fusing information. To address this problem, this paper presents RCBEVDet, a radar-camera fusion 3D object detection framework. Specifically, RCBEVDet is developed from an existing camera-based 3D object detector, supplemented by a specially designed radar feature extractor, RadarBEVNet, and a Cross-Attention Multi-layer Fusion (CAMF) module. Firstly, RadarBEVNet encodes sparse radar points into a dense bird's-eye-view (BEV) feature using a dual-stream radar backbone and a Radar Cross Section aware BEV encoder. Secondly, the CAMF module utilizes a deformable attention mechanism to align radar and camera BEV features and adopts channel and spatial fusion layers to fuse them. To further enhance RCBEVDet's capabilities, we introduce RCBEVDet++, which advances the CAMF through sparse fusion, supports query-based multi-view camera perception models, and adapts to a broader range of perception tasks. Extensive experiments on the nuScenes show that our method integrates seamlessly with existing camera-based 3D perception models and improves their performance across various perception tasks. Furthermore, our method achieves state-of-the-art radar-camera fusion results in 3D object detection, BEV semantic segmentation, and 3D multi-object tracking tasks. Notably, with ViT-L as the image backbone, RCBEVDet++ achieves 72.73 NDS and 67.34 mAP in 3D object detection without test-time augmentation or model ensembling.
Trusted Unified Feature-Neighborhood Dynamics for Multi-View Classification
Sep 01, 2024Multi-view classification (MVC) faces inherent challenges due to domain gaps and inconsistencies across different views, often resulting in uncertainties during the fusion process. While Evidential Deep Learning (EDL) has been effective in addressing view uncertainty, existing methods predominantly rely on the Dempster-Shafer combination rule, which is sensitive to conflicting evidence and often neglects the critical role of neighborhood structures within multi-view data. To address these limitations, we propose a Trusted Unified Feature-NEighborhood Dynamics (TUNED) model for robust MVC. This method effectively integrates local and global feature-neighborhood (F-N) structures for robust decision-making. Specifically, we begin by extracting local F-N structures within each view. To further mitigate potential uncertainties and conflicts in multi-view fusion, we employ a selective Markov random field that adaptively manages cross-view neighborhood dependencies. Additionally, we employ a shared parameterized evidence extractor that learns global consensus conditioned on local F-N structures, thereby enhancing the global integration of multi-view features. Experiments on benchmark datasets show that our method improves accuracy and robustness over existing approaches, particularly in scenarios with high uncertainty and conflicting views. The code will be made available at https://github.com/JethroJames/TUNED.
Evidential Deep Partial Multi-View Classification With Discount Fusion
Aug 23, 2024Incomplete multi-view data classification poses significant challenges due to the common issue of missing views in real-world scenarios. Despite advancements, existing methods often fail to provide reliable predictions, largely due to the uncertainty of missing views and the inconsistent quality of imputed data. To tackle these problems, we propose a novel framework called Evidential Deep Partial Multi-View Classification (EDP-MVC). Initially, we use K-means imputation to address missing views, creating a complete set of multi-view data. However, the potential conflicts and uncertainties within this imputed data can affect the reliability of downstream inferences. To manage this, we introduce a Conflict-Aware Evidential Fusion Network (CAEFN), which dynamically adjusts based on the reliability of the evidence, ensuring trustworthy discount fusion and producing reliable inference outcomes. Comprehensive experiments on various benchmark datasets reveal EDP-MVC not only matches but often surpasses the performance of state-of-the-art methods.