 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLUB: A Contrastive Log-ratio Upper Bound of Mutual Information
Jul 14, 2020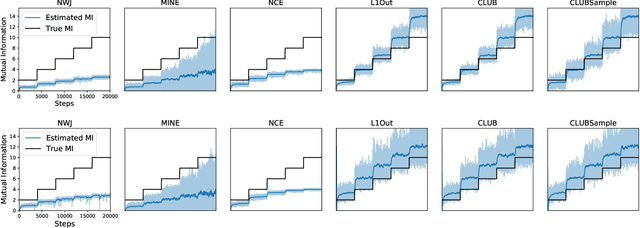
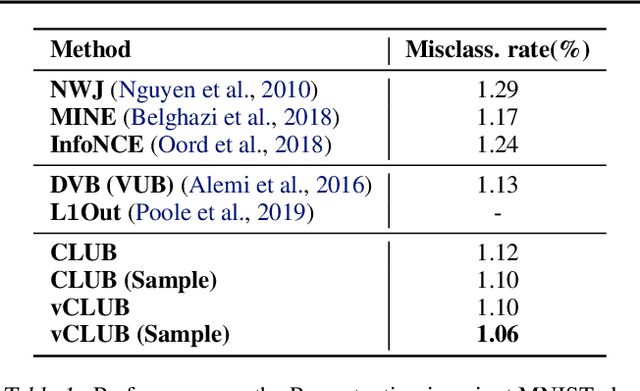
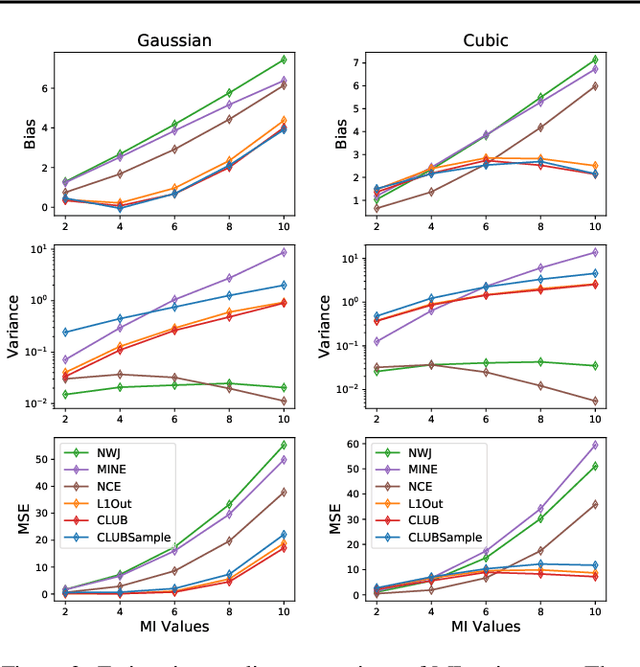
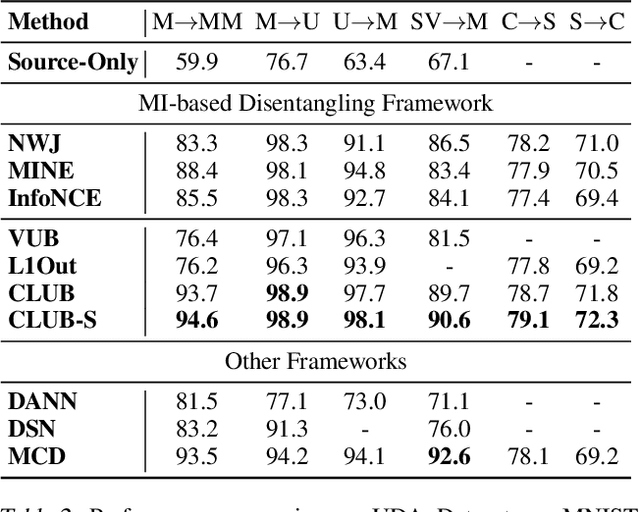
Mutual information (MI) minimization has gained considerable interests in various machine learning tasks. However, estimating and minimizing MI in high-dimensional spaces remains a challenging problem, especially when only samples, rather than distribution forms, are accessible. Previous works mainly focus on MI lower bound approximation, which is not applicable to MI minimization problems. In this paper, we propose a novel Contrastive Log-ratio Upper Bound (CLUB) of mutual information. We provide a theoretical analysis of the properties of CLUB and its variational approximation. Based on this upper bound, we introduce an accelerated MI minimization training scheme, which bridges MI minimization with negative sampling. Simulation studies on Gaussian distributions show the reliable estimation ability of CLUB. Real-world MI minimization experiments, including domain adaptation and information bottleneck, further demonstrate the effectiveness of the proposed method. The code is at https://github.com/Linear95/CLUB.
Graph Optimal Transport for Cross-Domain Alignment
Jun 29, 2020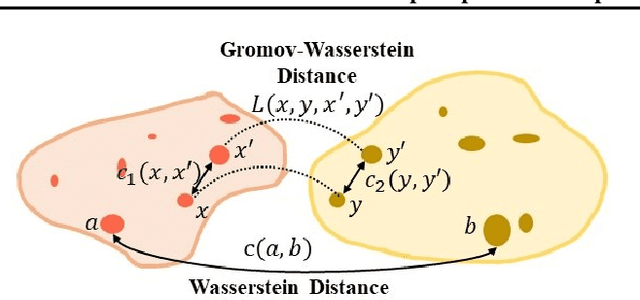
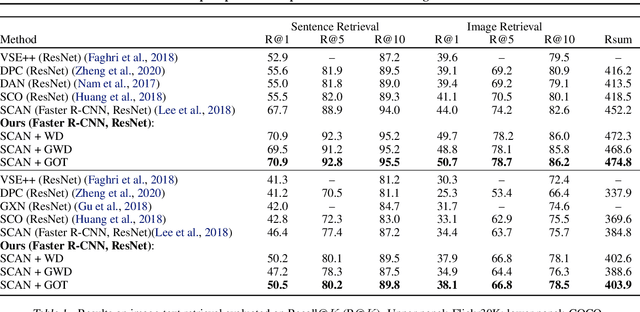
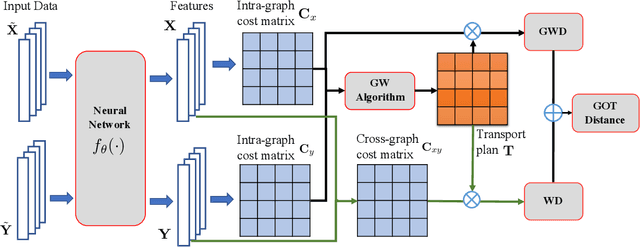
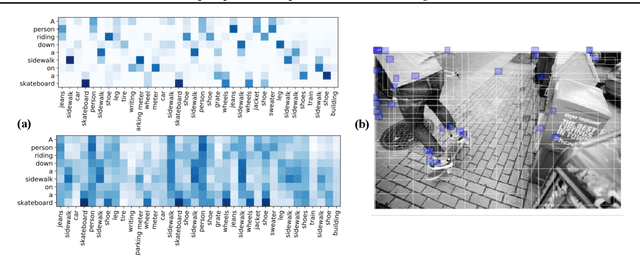
Cross-domain alignment between two sets of entities (e.g., objects in an image, words in a sentence) is fundamental to both computer vision and natural language processing. Existing methods mainly focus on designing advanced attention mechanisms to simulate soft alignment, with no training signals to explicitly encourage alignment. The learned attention matrices are also dense and lacks interpretability. We propose Graph Optimal Transport (GOT), a principled framework that germinates from recent advances in Optimal Transport (OT). In GOT, cross-domain alignment is formulated as a graph matching problem, by representing entities into a dynamically-constructed graph. Two types of OT distances are considered: (i) Wasserstein distance (WD) for node (entity) matching; and (ii) Gromov-Wasserstein distance (GWD) for edge (structure) matching. Both WD and GWD can be incorporated into existing neural network models, effectively acting as a drop-in regularizer. The inferred transport plan also yields sparse and self-normalized alignment, enhancing the interpretability of the learned model. Experiments show consistent outperformance of GOT over baselines across a wide range of tasks, including image-text retrieval, visual question answering, image captioning, machine translation, and text summarization.
Adaptive Learning Rates with Maximum Variation Averaging
Jun 21, 2020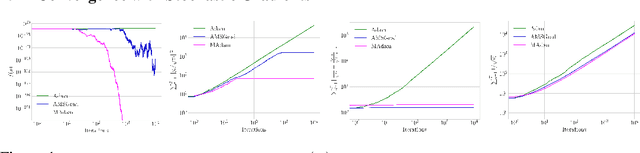

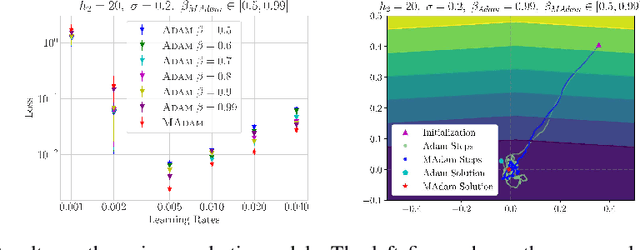

Adaptive gradient methods such as RMSProp and Adam use exponential moving estimate of the squared gradient to compute element-wise adaptive step sizes and handle noisy gradients. However, Adam can have undesirable convergence behavior in some problems due to unstable or extreme adaptive learning rates. Methods such as AMSGrad and AdaBound have been proposed to stabilize the adaptive learning rates of Adam in the later stage of training, but they do not outperform Adam in some practical tasks such as training Transformers. In this paper, we propose an adaptive learning rate rule in which the running mean squared gradient is replaced by a weighted mean, with weights chosen to maximize the estimated variance of each coordinate. This gives a worst-case estimate for the local gradient variance, taking smaller steps when large curvatures or noisy gradients are present, resulting in more desirable convergence behavior than Adam. We analyze and demonstrate the improved efficacy of our adaptive averaging approach on image classification, neural machine translation and natural language understanding tasks.
Large-Scale Adversarial Training for Vision-and-Language Representation Learning
Jun 11, 2020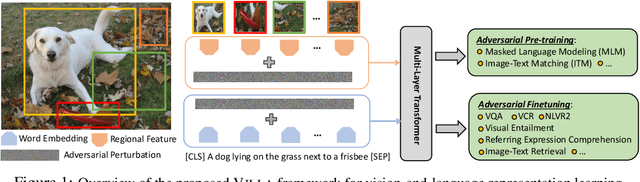
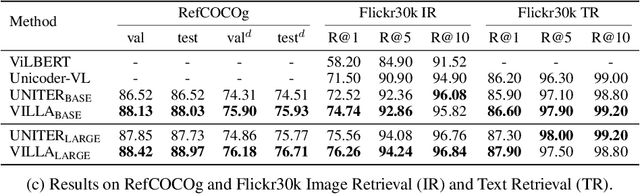
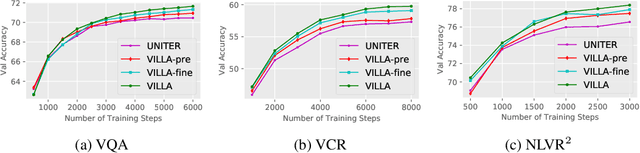
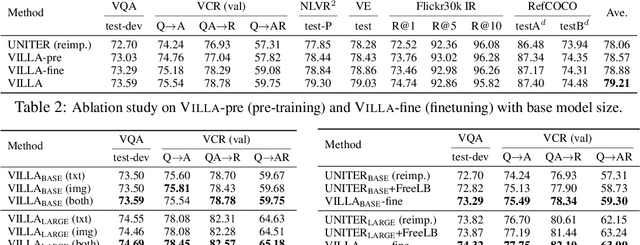
We present VILLA, the first known effort on large-scale adversarial training for vision-and-language (V+L) representation learning. VILLA consists of two training stages: (i) task-agnostic adversarial pre-training; followed by (ii) task-specific adversarial finetuning. Instead of adding adversarial perturbations on image pixels and textual tokens, we propose to perform adversarial training in the embedding space of each modality. To enable large-scale training, we adopt the "free" adversarial training strategy, and combine it with KL-divergence-based regularization to promote higher invariance in the embedding space. We apply VILLA to current best-performing V+L models, and achieve new state of the art on a wide range of tasks, including Visual Question Answering, Visual Commonsense Reasoning, Image-Text Retrieval, Referring Expression Comprehension, Visual Entailment, and NLVR2.
Behind the Scene: Revealing the Secrets of Pre-trained Vision-and-Language Models
May 15, 2020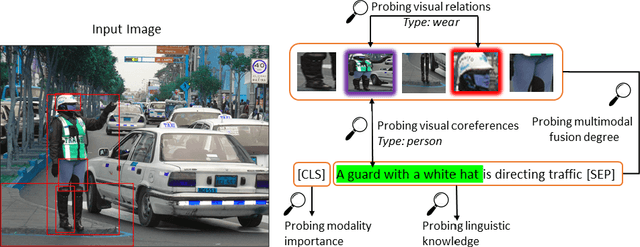

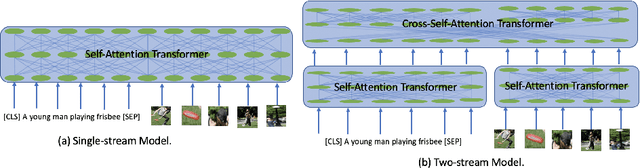
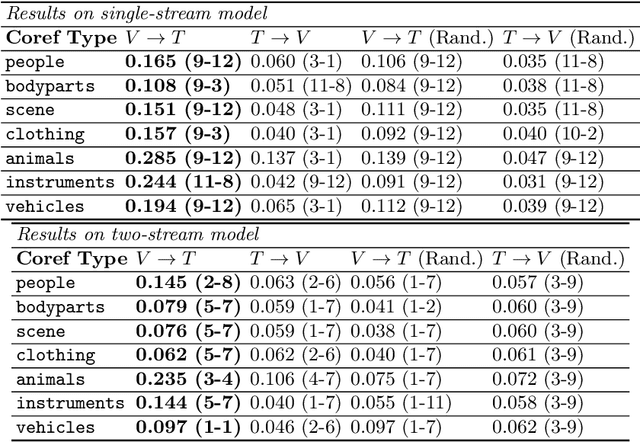
Recent Transformer-based large-scale pre-trained models have revolutionized vision-and-language (V+L) research. Models such as ViLBERT, LXMERT and UNITER have significantly lifted state of the art across a wide range of V+L benchmarks with joint image-text pre-training. However, little is known about the inner mechanisms that destine their impressive success. To reveal the secrets behind the scene of these powerful models, we present VALUE (Vision-And-Language Understanding Evaluation), a set of meticulously designed probing tasks (e.g., Visual Coreference Resolution, Visual Relation Detection, Linguistic Probing Tasks) generalizable to standard pre-trained V+L models, aiming to decipher the inner workings of multimodal pre-training (e.g., the implicit knowledge garnered in individual attention heads, the inherent cross-modal alignment learned through contextualized multimodal embeddings). Through extensive analysis of each archetypal model architecture via these probing tasks, our key observations are: (i) Pre-trained models exhibit a propensity for attending over text rather than images during inference. (ii) There exists a subset of attention heads that are tailored for capturing cross-modal interactions. (iii) Learned attention matrix in pre-trained models demonstrates patterns coherent with the latent alignment between image regions and textual words. (iv) Plotted attention patterns reveal visually-interpretable relations among image regions. (v) Pure linguistic knowledge is also effectively encoded in the attention heads. These are valuable insights serving to guide future work towards designing better model architecture and objectives for multimodal pre-training.
Improving Adversarial Text Generation by Modeling the Distant Future
May 04, 2020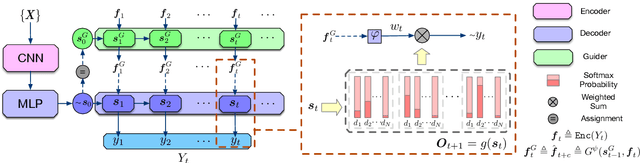
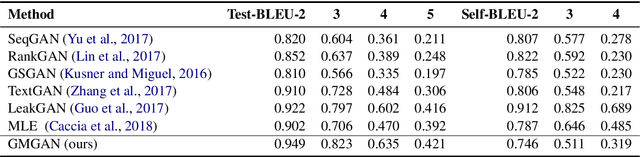
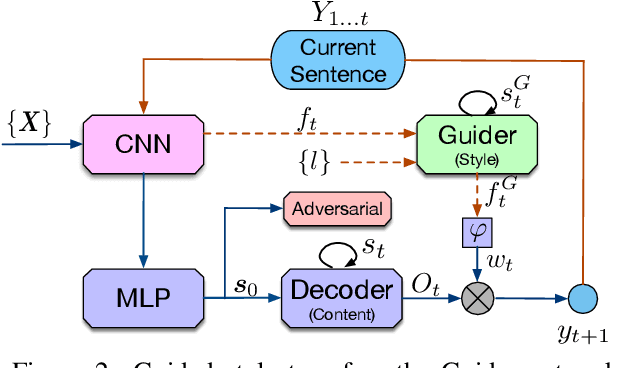
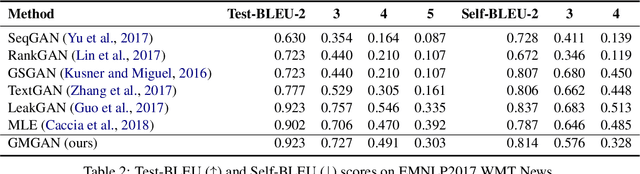
Auto-regressive text generation models usually focus on local fluency, and may cause inconsistent semantic meaning in long text generation. Further, automatically generating words with similar semantics is challenging, and hand-crafted linguistic rules are difficult to apply. We consider a text planning scheme and present a model-based imitation-learning approach to alleviate the aforementioned issues. Specifically, we propose a novel guider network to focus on the generative process over a longer horizon, which can assist next-word prediction and provide intermediate rewards for generator optimization. Extensive experiments demonstrate that the proposed method leads to improved performance.
POINTER: Constrained Text Generation via Insertion-based Generative Pre-training
May 01, 2020

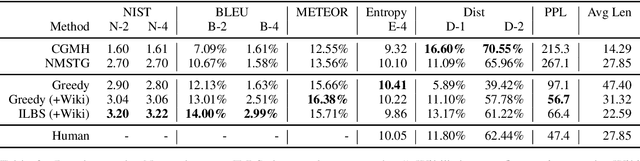
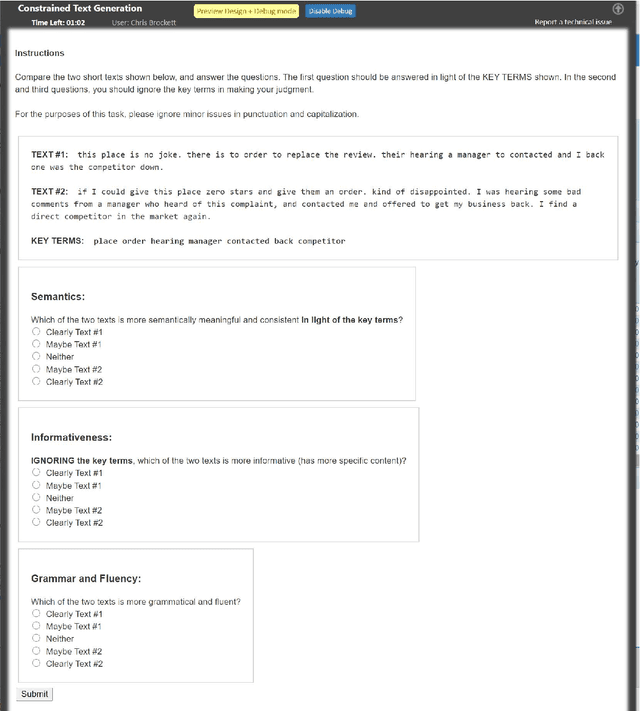
Large-scale pre-trained language models, such as BERT and GPT-2, have achieved excellent performance in language representation learning and free-form text generation. However, these models cannot be directly employed to generate text under specified lexical constraints. To address this challenge, we present POINTER, a simple yet novel insertion-based approach for hard-constrained text generation. The proposed method operates by progressively inserting new tokens between existing tokens in a parallel manner. This procedure is recursively applied until a sequence is completed. The resulting coarse-to-fine hierarchy makes the generation process intuitive and interpretable. Since our training objective resembles the objective of masked language modeling, BERT can be naturally utilized for initialization. We pre-train our model with the proposed progressive insertion-based objective on a 12GB Wikipedia dataset, and fine-tune it on downstream hard-constrained generation tasks. Non-autoregressive decoding yields a logarithmic time complexity during inference time. Experimental results on both News and Yelp datasets demonstrate that POINTER achieves state-of-the-art performance on constrained text generation. We intend to release the pre-trained model to facilitate future research.
HERO: Hierarchical Encoder for Video+Language Omni-representation Pre-training
May 01, 2020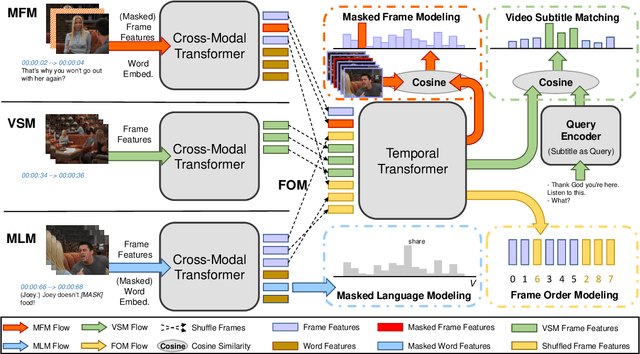
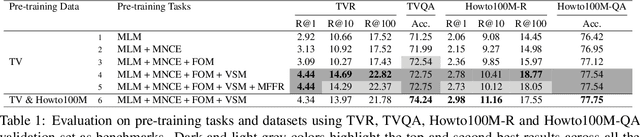
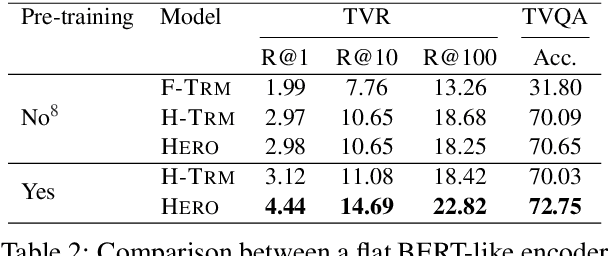
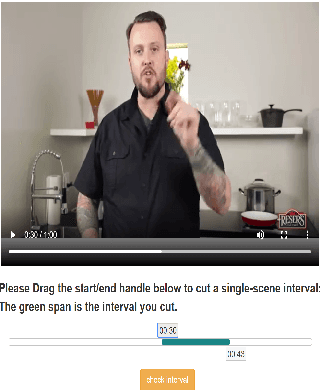
We present HERO, a Hierarchical EncodeR for Omni-representation learning, for large-scale video+language pre-training. HERO encodes multimodal inputs in a hierarchical fashion, where local textual context of a video frame is captured by a Cross-modal Transformer via multimodal fusion, and global video context is captured by a Temporal Transformer. Besides standard Masked Language Modeling (MLM) and Masked Frame Modeling (MFM) objectives, we design two new pre-training tasks: (i) Video-Subtitle Matching (VSM), where the model predicts both global and local temporal alignment; and (ii) Frame Order Modeling (FOM), where the model predicts the right order of shuffled video frames. Different from previous work that mostly focused on cooking or narrated instructional videos, HERO is jointly trained on HowTo100M and large-scale TV show datasets to learn complex social scenes, dynamics backdrop transitions and multi-character interactions. Extensive experiments demonstrate that HERO achieves new state of the art on both text-based video moment retrieval and video question answering tasks across different domains.
Contextual Text Style Transfer
Apr 30, 2020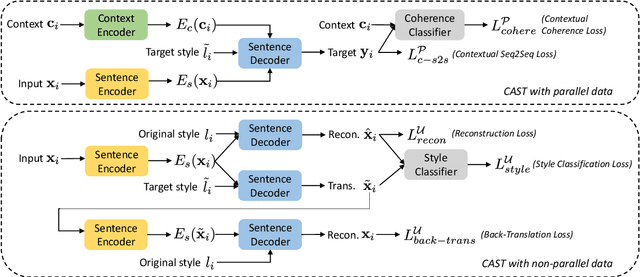

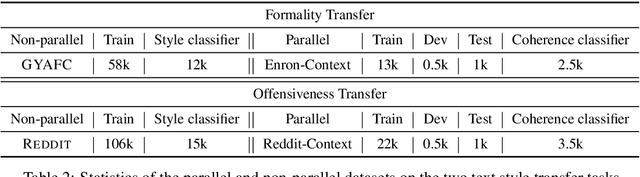
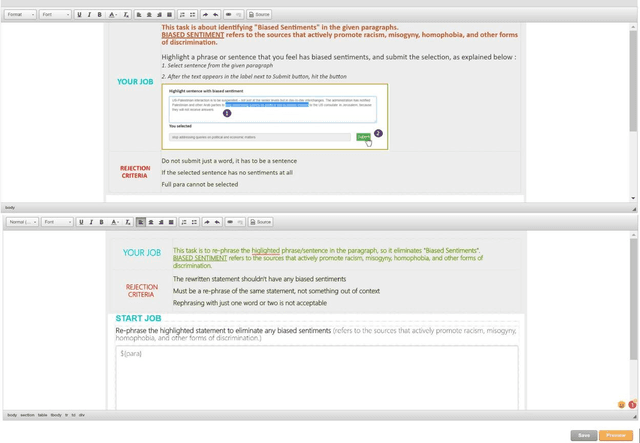
We introduce a new task, Contextual Text Style Transfer - translating a sentence into a desired style with its surrounding context taken into account. This brings two key challenges to existing style transfer approaches: ($i$) how to preserve the semantic meaning of target sentence and its consistency with surrounding context during transfer; ($ii$) how to train a robust model with limited labeled data accompanied with context. To realize high-quality style transfer with natural context preservation, we propose a Context-Aware Style Transfer (CAST) model, which uses two separate encoders for each input sentence and its surrounding context. A classifier is further trained to ensure contextual consistency of the generated sentence. To compensate for the lack of parallel data, additional self-reconstruction and back-translation losses are introduced to leverage non-parallel data in a semi-supervised fashion. Two new benchmarks, Enron-Context and Reddit-Context, are introduced for formality and offensiveness style transfer. Experimental results on these datasets demonstrate the effectiveness of the proposed CAST model over state-of-the-art methods across style accuracy, content preservation and contextual consistency metrics.
APo-VAE: Text Generation in Hyperbolic Space
Apr 30, 2020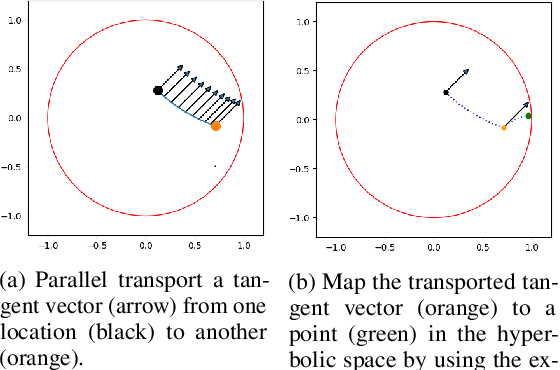
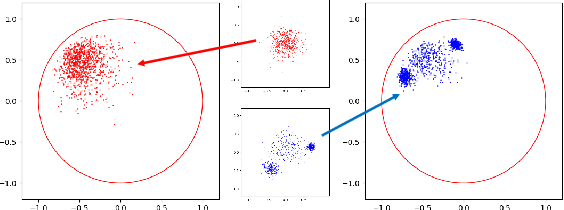
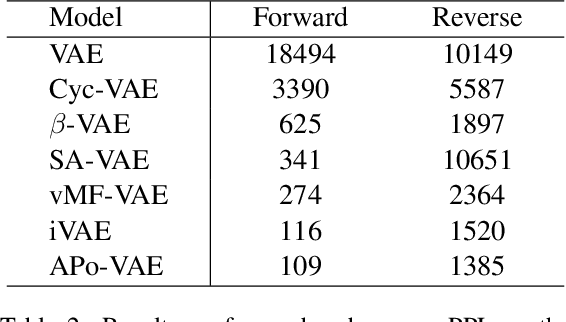
Natural language often exhibits inherent hierarchical structure ingrained with complex syntax and semantics. However, most state-of-the-art deep generative models learn embeddings only in Euclidean vector space, without accounting for this structural property of language. In this paper, we investigate text generation in a hyperbolic latent space to learn continuous hierarchical representations. An Adversarial Poincare Variational Autoencoder (APo-VAE) is presented, where both the prior and variational posterior of latent variables are defined over a Poincare ball via wrapped normal distributions. By adopting the primal-dual formulation of KL divergence, an adversarial learning procedure is introduced to empower robust model training. Extensive experiments in language modeling and dialog-response generation tasks demonstrate the winning effectiveness of the proposed APo-VAE model over VAEs in Euclidean latent space, thanks to its superb capabilities in capturing latent language hierarchies in hyperbolic space.