 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarsening the Granularity: Towards Structurally Sparse Lottery Tickets
Feb 09, 2022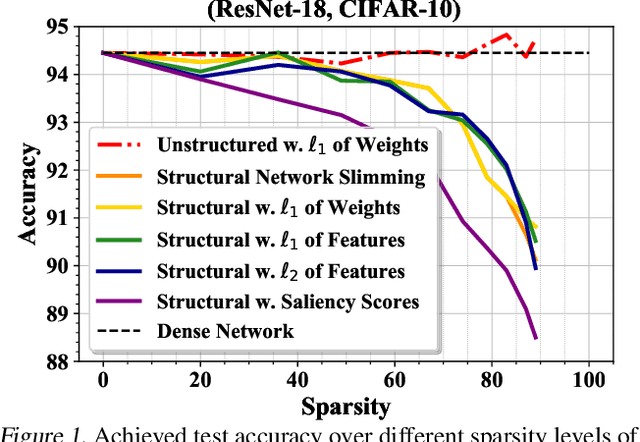
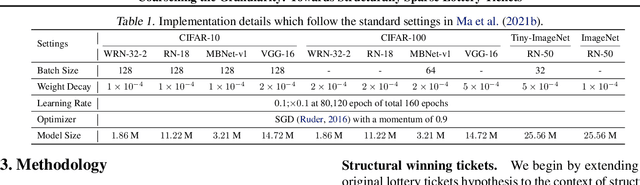
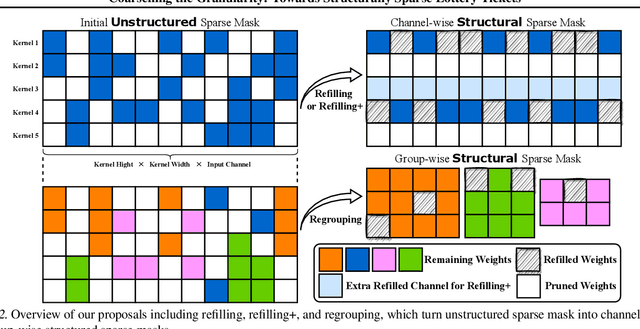
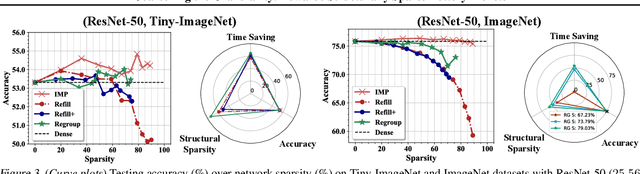
The lottery ticket hypothesis (LTH) has shown that dense models contain highly sparse subnetworks (i.e., winning tickets) that can be trained in isolation to match full accuracy. Despite many exciting efforts being made, there is one "commonsense" seldomly challenged: a winning ticket is found by iterative magnitude pruning (IMP) and hence the resultant pruned subnetworks have only unstructured sparsity. That gap limits the appeal of winning tickets in practice, since the highly irregular sparse patterns are challenging to accelerate on hardware. Meanwhile, directly substituting structured pruning for unstructured pruning in IMP damages performance more severely and is usually unable to locate winning tickets. In this paper, we demonstrate the first positive result that a structurally sparse winning ticket can be effectively found in general. The core idea is to append "post-processing techniques" after each round of (unstructured) IMP, to enforce the formation of structural sparsity. Specifically, we first "re-fill" pruned elements back in some channels deemed to be important, and then "re-group" non-zero elements to create flexible group-wise structural patterns. Both our identified channel- and group-wise structural subnetworks win the lottery, with substantial inference speedups readily supported by existing hardware. Extensive experiments, conducted on diverse datasets across multiple network backbones, consistently validate our proposal, showing that the hardware acceleration roadblock of LTH is now removed. Specifically, the structural winning tickets obtain up to {64.93%, 64.84%, 64.84%} running time savings at {36% ~ 80%, 74%, 58%} sparsity on {CIFAR, Tiny-ImageNet, ImageNet}, while maintaining comparable accuracy. Codes are available in https://github.com/VITA-Group/Structure-LTH.
The Unreasonable Effectiveness of Random Pruning: Return of the Most Naive Baseline for Sparse Training
Feb 05, 2022

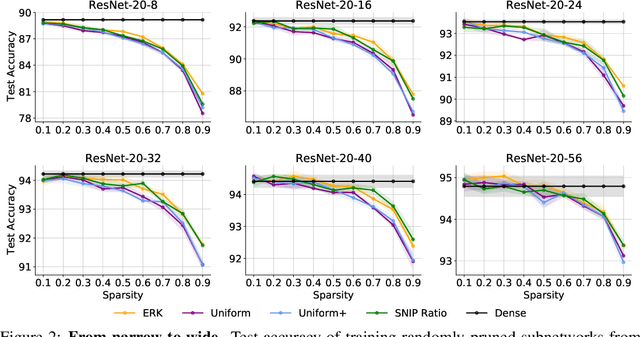
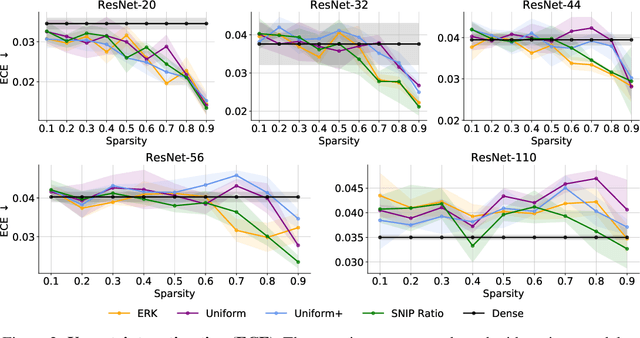
Random pruning is arguably the most naive way to attain sparsity in neural networks, but has been deemed uncompetitive by either post-training pruning or sparse training. In this paper, we focus on sparse training and highlight a perhaps counter-intuitive finding, that random pruning at initialization can be quite powerful for the sparse training of modern neural networks. Without any delicate pruning criteria or carefully pursued sparsity structures, we empirically demonstrate that sparsely training a randomly pruned network from scratch can match the performance of its dense equivalent. There are two key factors that contribute to this revival: (i) the network sizes matter: as the original dense networks grow wider and deeper, the performance of training a randomly pruned sparse network will quickly grow to matching that of its dense equivalent, even at high sparsity ratios; (ii) appropriate layer-wise sparsity ratios can be pre-chosen for sparse training, which shows to be another important performance booster. Simple as it looks, a randomly pruned subnetwork of Wide ResNet-50 can be sparsely trained to outperforming a dense Wide ResNet-50, on ImageNet. We also observed such randomly pruned networks outperform dense counterparts in other favorable aspects, such as out-of-distribution detection, uncertainty estimation, and adversarial robustness. Overall, our results strongly suggest there is larger-than-expected room for sparse training at scale, and the benefits of sparsity might be more universal beyond carefully designed pruning. Our source code can be found at https://github.com/VITA-Group/Random_Pruning.
VAQF: Fully Automatic Software-hardware Co-design Framework for Low-bit Vision Transformer
Jan 17, 2022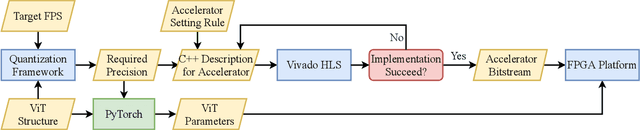
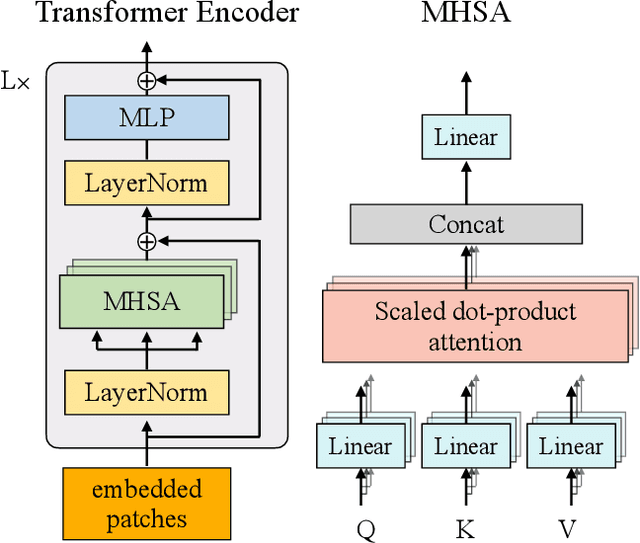
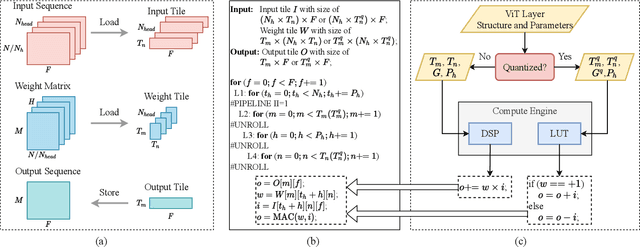
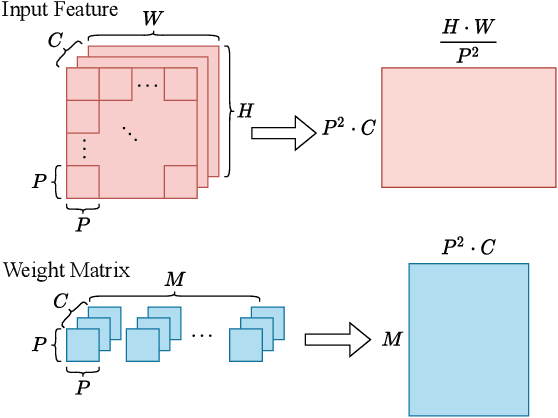
The transformer architectures with attention mechanisms have obtained success in Nature Language Processing (NLP), and Vision Transformers (ViTs) have recently extended the application domains to various vision tasks. While achieving high performance, ViTs suffer from large model size and high computation complexity that hinders the deployment of them on edge devices. To achieve high throughput on hardware and preserve the model accuracy simultaneously, we propose VAQF, a framework that builds inference accelerators on FPGA platforms for quantized ViTs with binary weights and low-precision activations. Given the model structure and the desired frame rate, VAQF will automatically output the required quantization precision for activations as well as the optimized parameter settings of the accelerator that fulfill the hardware requirements. The implementations are developed with Vivado High-Level Synthesis (HLS) on the Xilinx ZCU102 FPGA board, and the evaluation results with the DeiT-base model indicate that a frame rate requirement of 24 frames per second (FPS) is satisfied with 8-bit activation quantization, and a target of 30 FPS is met with 6-bit activation quantization. To the best of our knowledge, this is the first time quantization has been incorporated into ViT acceleration on FPGAs with the help of a fully automatic framework to guide the quantization strategy on the software side and the accelerator implementations on the hardware side given the target frame rate. Very small compilation time cost is incurred compared with quantization training, and the generated accelerators show the capability of achieving real-time execution for state-of-the-art ViT models on FPGAs.
Bringing Your Own View: Graph Contrastive Learning without Prefabricated Data Augmentations
Jan 04, 2022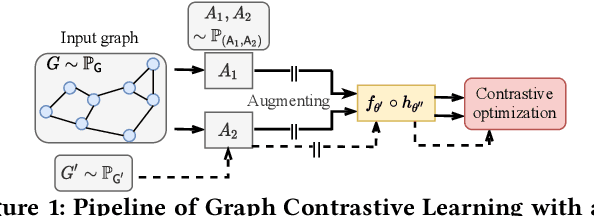

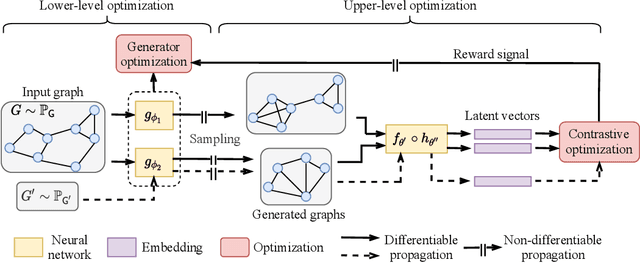
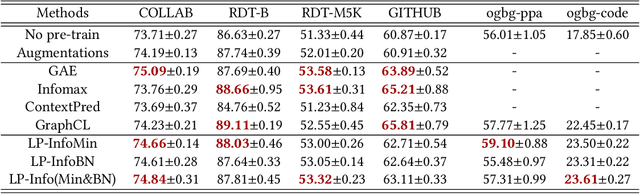
Self-supervision is recently surging at its new frontier of graph learning. It facilitates graph representations beneficial to downstream tasks; but its success could hinge on domain knowledge for handcraft or the often expensive trials and errors. Even its state-of-the-art representative, graph contrastive learning (GraphCL), is not completely free of those needs as GraphCL uses a prefabricated prior reflected by the ad-hoc manual selection of graph data augmentations. Our work aims at advancing GraphCL by answering the following questions: How to represent the space of graph augmented views? What principle can be relied upon to learn a prior in that space? And what framework can be constructed to learn the prior in tandem with contrastive learning? Accordingly, we have extended the prefabricated discrete prior in the augmentation set, to a learnable continuous prior in the parameter space of graph generators, assuming that graph priors per se, similar to the concept of image manifolds, can be learned by data generation. Furthermore, to form contrastive views without collapsing to trivial solutions due to the prior learnability, we have leveraged both principles of information minimization (InfoMin) and information bottleneck (InfoBN) to regularize the learned priors. Eventually, contrastive learning, InfoMin, and InfoBN are incorporated organically into one framework of bi-level optimization. Our principled and automated approach has proven to be competitive against the state-of-the-art graph self-supervision methods, including GraphCL, on benchmarks of small graphs; and shown even better generalizability on large-scale graphs, without resorting to human expertise or downstream validation. Our code is publicly released at https://github.com/Shen-Lab/GraphCL_Automated.
Fast and High-Quality Image Denoising via Malleable Convolutions
Jan 04, 2022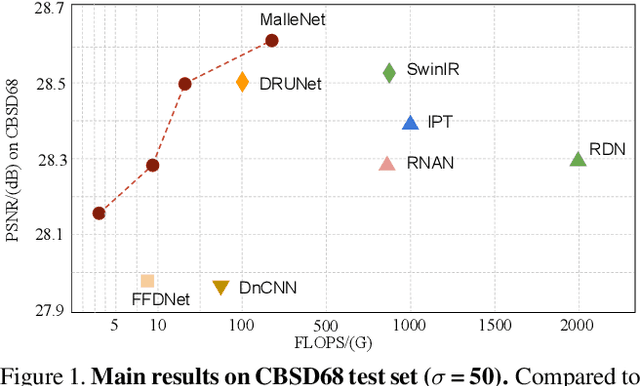
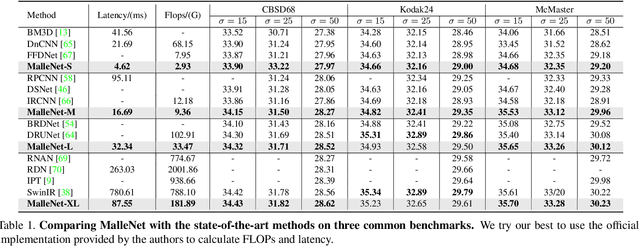
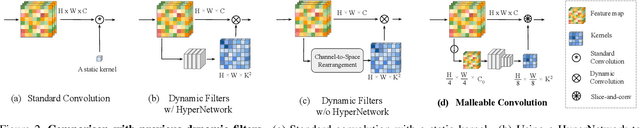
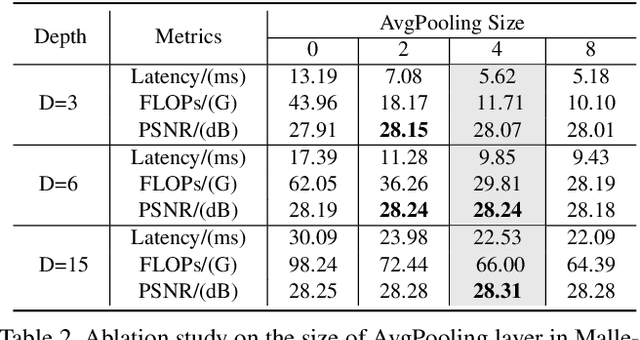
Many image processing networks apply a single set of static convolutional kernels across the entire input image, which is sub-optimal for natural images, as they often consist of heterogeneous visual patterns. Recent works in classification, segmentation, and image restoration have demonstrated that dynamic kernels outperform static kernels at modeling local image statistics. However, these works often adopt per-pixel convolution kernels, which introduce high memory and computation costs. To achieve spatial-varying processing without significant overhead, we present Malleable Convolution (MalleConv), as an efficient variant of dynamic convolution. The weights of MalleConv are dynamically produced by an efficient predictor network capable of generating content-dependent outputs at specific spatial locations. Unlike previous works, MalleConv generates a much smaller set of spatially-varying kernels from input, which enlarges the network's receptive field and significantly reduces computational and memory costs. These kernels are then applied to a full-resolution feature map through an efficient slice-and-conv operator with minimum memory overhead. We further build an efficient denoising network using MalleConv, coined as MalleNet. It achieves high quality results without very deep architecture, e.g., reaching 8.91x faster speed compared to the best performed denoising algorithms (SwinIR), while maintaining similar performance. We also show that a single MalleConv added to a standard convolution-based backbone can contribute significantly to reducing the computational cost or boosting image quality at a similar cost. Project page: https://yifanjiang.net/MalleConv.html
Federated Dynamic Sparse Training: Computing Less, Communicating Less, Yet Learning Better
Dec 18, 2021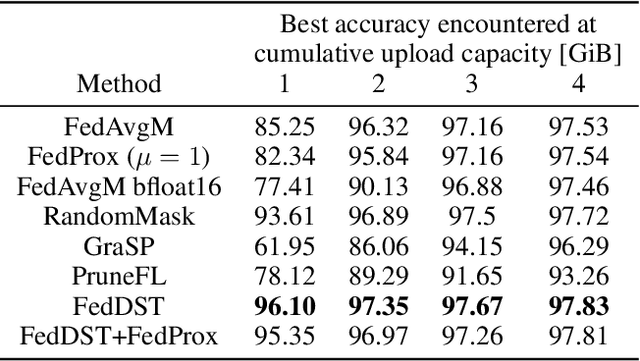
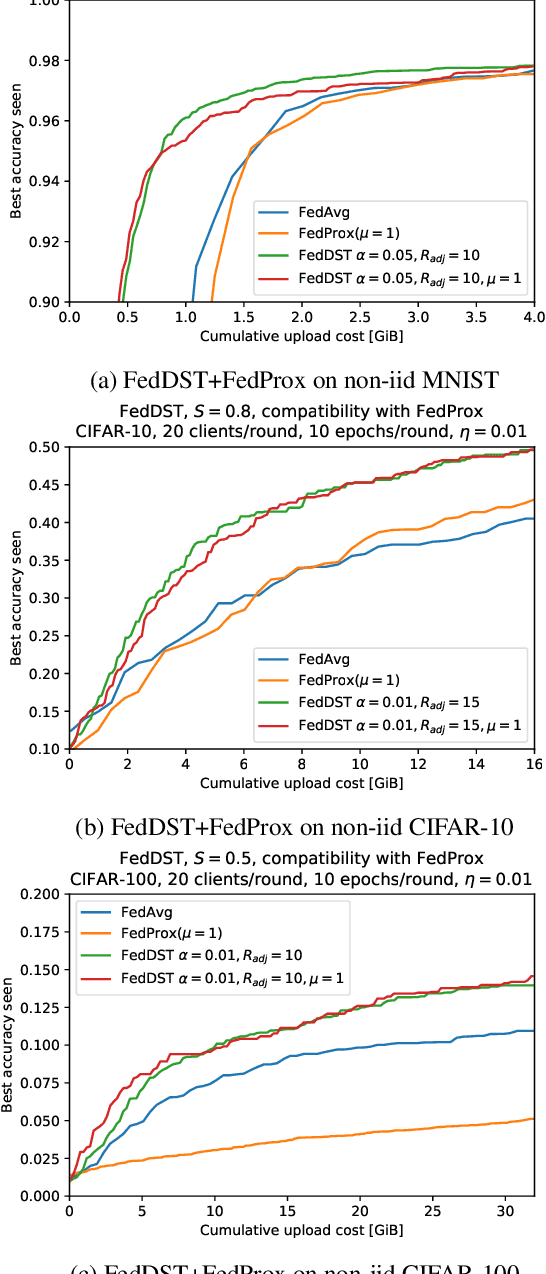
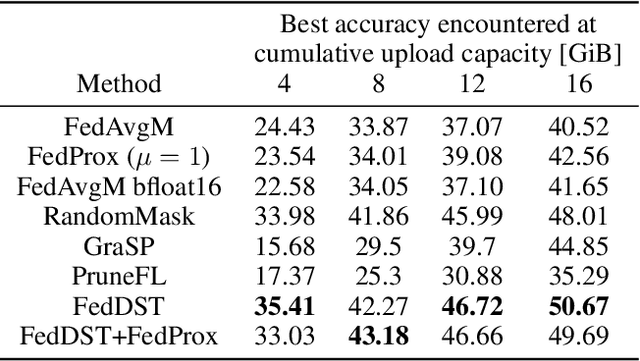
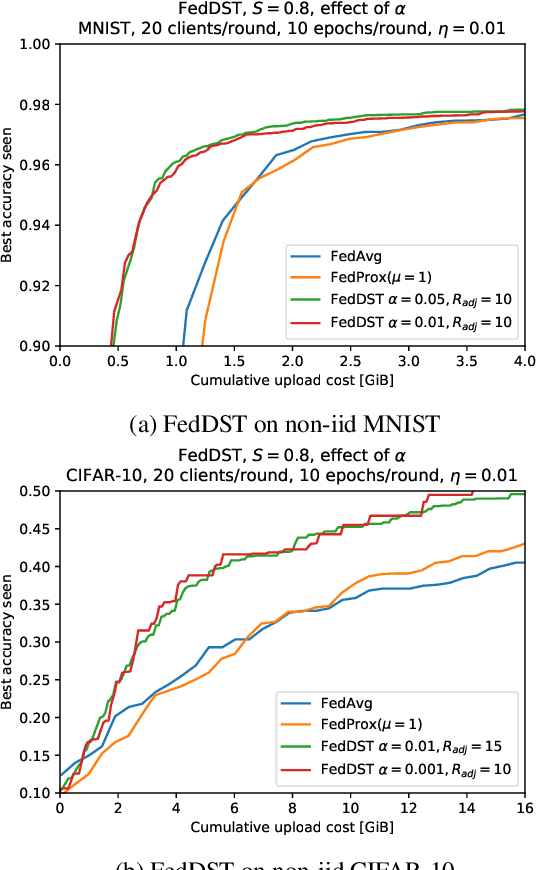
Federated learning (FL) enables distribution of machine learning workloads from the cloud to resource-limited edge devices. Unfortunately, current deep networks remain not only too compute-heavy for inference and training on edge devices, but also too large for communicating updates over bandwidth-constrained networks. In this paper, we develop, implement, and experimentally validate a novel FL framework termed Federated Dynamic Sparse Training (FedDST) by which complex neural networks can be deployed and trained with substantially improved efficiency in both on-device computation and in-network communication. At the core of FedDST is a dynamic process that extracts and trains sparse sub-networks from the target full network. With this scheme, "two birds are killed with one stone:" instead of full models, each client performs efficient training of its own sparse networks, and only sparse networks are transmitted between devices and the cloud. Furthermore, our results reveal that the dynamic sparsity during FL training more flexibly accommodates local heterogeneity in FL agents than the fixed, shared sparse masks. Moreover, dynamic sparsity naturally introduces an "in-time self-ensembling effect" into the training dynamics and improves the FL performance even over dense training. In a realistic and challenging non i.i.d. FL setting, FedDST consistently outperforms competing algorithms in our experiments: for instance, at any fixed upload data cap on non-iid CIFAR-10, it gains an impressive accuracy advantage of 10% over FedAvgM when given the same upload data cap; the accuracy gap remains 3% even when FedAvgM is given 2x the upload data cap, further demonstrating efficacy of FedDST. Code is available at: https://github.com/bibikar/feddst.
A Simple Single-Scale Vision Transformer for Object Localization and Instance Segmentation
Dec 17, 2021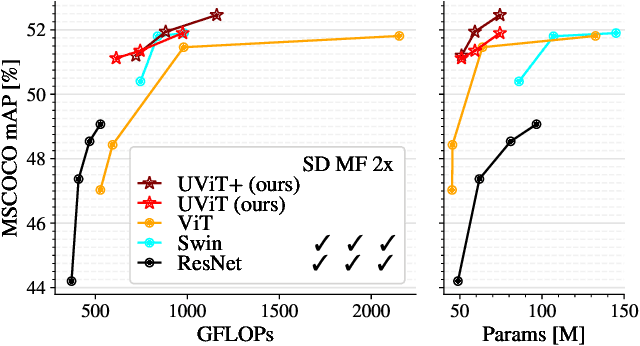

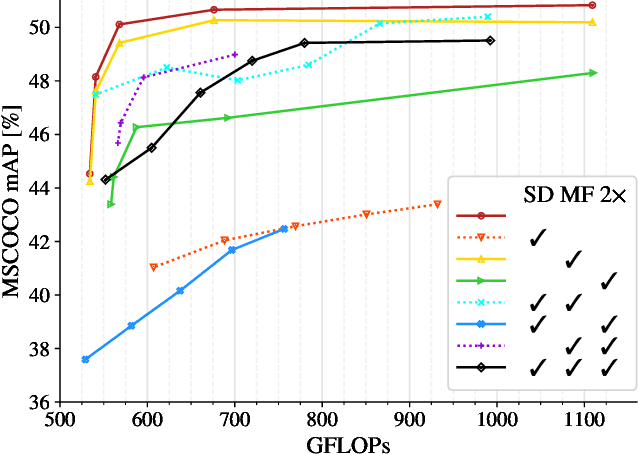

This work presents a simple vision transformer design as a strong baseline for object localization and instance segmentation tasks. Transformers recently demonstrate competitive performance in image classification tasks. To adopt ViT to object detection and dense prediction tasks, many works inherit the multistage design from convolutional networks and highly customized ViT architectures. Behind this design, the goal is to pursue a better trade-off between computational cost and effective aggregation of multiscale global contexts. However, existing works adopt the multistage architectural design as a black-box solution without a clear understanding of its true benefits. In this paper, we comprehensively study three architecture design choices on ViT -- spatial reduction, doubled channels, and multiscale features -- and demonstrate that a vanilla ViT architecture can fulfill this goal without handcrafting multiscale features, maintaining the original ViT design philosophy. We further complete a scaling rule to optimize our model's trade-off on accuracy and computation cost / model size. By leveraging a constant feature resolution and hidden size throughout the encoder blocks, we propose a simple and compact ViT architecture called Universal Vision Transformer (UViT) that achieves strong performance on COCO object detection and instance segmentation tasks.
Auto-X3D: Ultra-Efficient Video Understanding via Finer-Grained Neural Architecture Search
Dec 09, 2021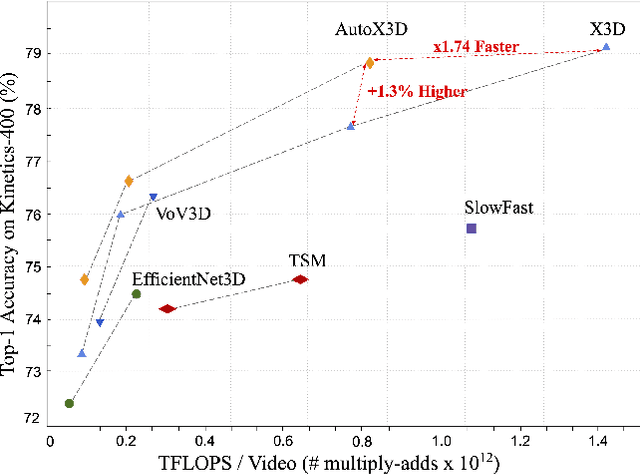

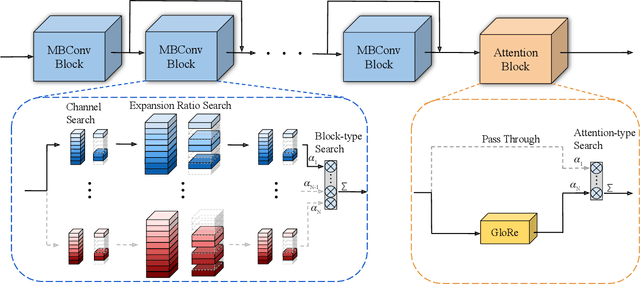
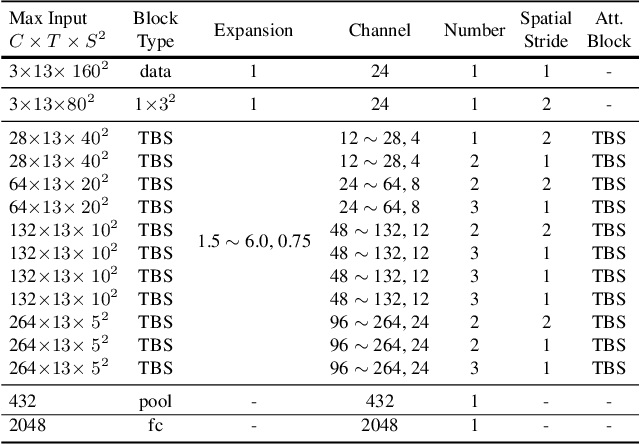
Efficient video architecture is the key to deploying video recognition systems on devices with limited computing resources. Unfortunately, existing video architectures are often computationally intensive and not suitable for such applications. The recent X3D work presents a new family of efficient video models by expanding a hand-crafted image architecture along multiple axes, such as space, time, width, and depth. Although operating in a conceptually large space, X3D searches one axis at a time, and merely explored a small set of 30 architectures in total, which does not sufficiently explore the space. This paper bypasses existing 2D architectures, and directly searched for 3D architectures in a fine-grained space, where block type, filter number, expansion ratio and attention block are jointly searched. A probabilistic neural architecture search method is adopted to efficiently search in such a large space. Evaluations on Kinetics and Something-Something-V2 benchmarks confirm our AutoX3D models outperform existing ones in accuracy up to 1.3% under similar FLOPs, and reduce the computational cost up to x1.74 when reaching similar performance.
Cold Brew: Distilling Graph Node Representations with Incomplete or Missing Neighborhoods
Nov 10, 2021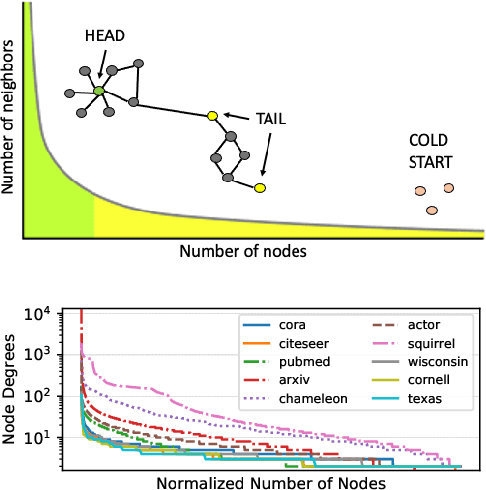
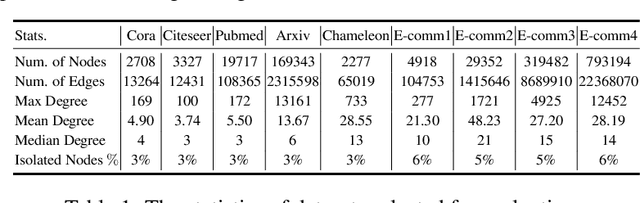
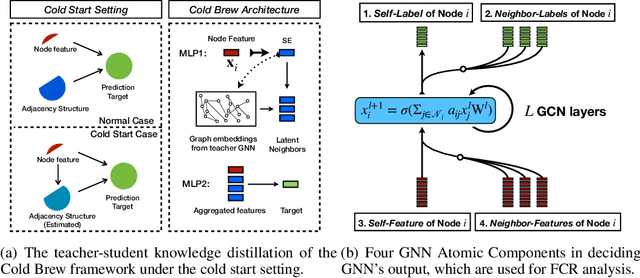
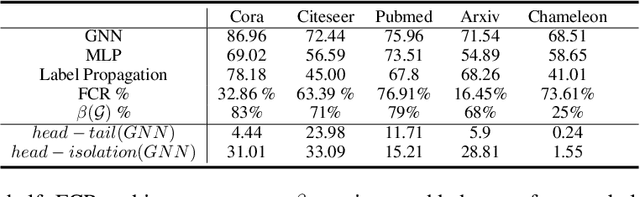
Graph Neural Networks (GNNs) have achieved state of the art performance in node classification, regression, and recommendation tasks. GNNs work well when high-quality and rich connectivity structure is available. However, this requirement is not satisfied in many real world graphs where the node degrees have power-law distributions as many nodes have either fewer or noisy connections. The extreme case of this situation is a node may have no neighbors at all, called Strict Cold Start (SCS) scenario. This forces the prediction models to rely completely on the node's input features. We propose Cold Brew to address the SCS and noisy neighbor setting compared to pointwise and other graph-based models via a distillation approach. We introduce feature-contribution ratio (FCR), a metric to study the viability of using inductive GNNs to solve the SCS problem and to select the best architecture for SCS generalization. We experimentally show FCR disentangles the contributions of various components of graph datasets and demonstrate the superior performance of Cold Brew on several public benchmarks and proprietary e-commerce datasets. The source code for our approach is available at: https://github.com/amazon-research/gnn-tail-generalization.
Improving Contrastive Learning on Imbalanced Seed Data via Open-World Sampling
Nov 01, 2021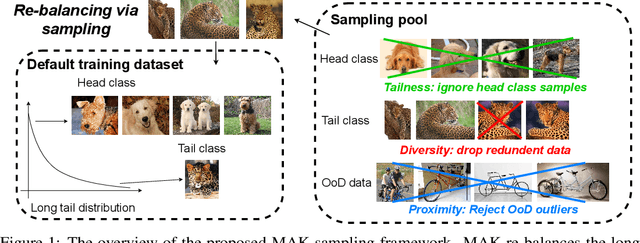
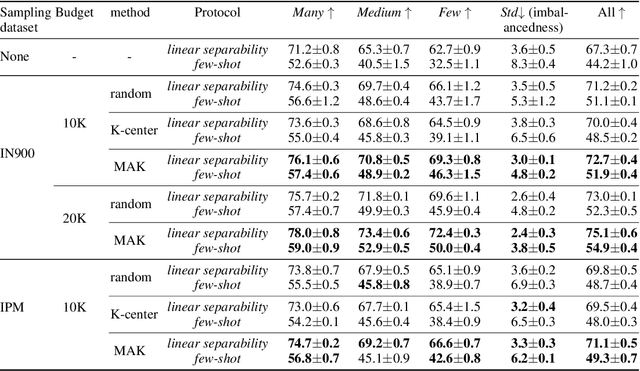
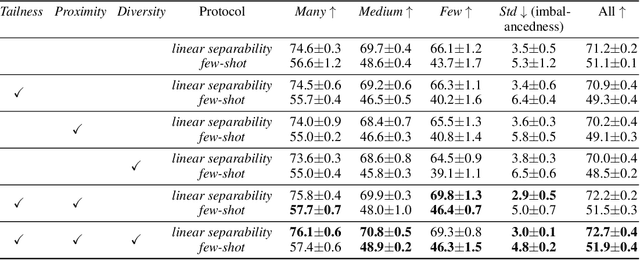
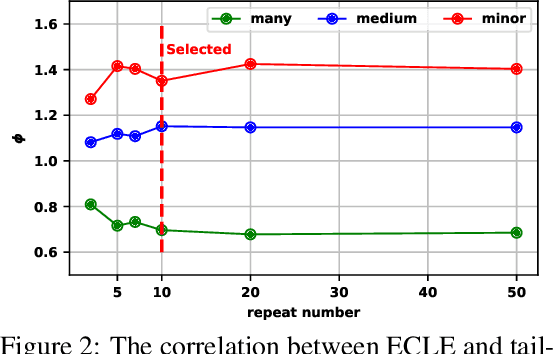
Contrastive learning approaches have achieved great success in learning visual representations with few labels of the target classes. That implies a tantalizing possibility of scaling them up beyond a curated "seed" benchmark, to incorporating more unlabeled images from the internet-scale external sources to enhance its performance. However, in practice, larger amount of unlabeled data will require more computing resources due to the bigger model size and longer training needed. Moreover, open-world unlabeled data usually follows an implicit long-tail class or attribute distribution, many of which also do not belong to the target classes. Blindly leveraging all unlabeled data hence can lead to the data imbalance as well as distraction issues. This motivates us to seek a principled approach to strategically select unlabeled data from an external source, in order to learn generalizable, balanced and diverse representations for relevant classes. In this work, we present an open-world unlabeled data sampling framework called Model-Aware K-center (MAK), which follows three simple principles: (1) tailness, which encourages sampling of examples from tail classes, by sorting the empirical contrastive loss expectation (ECLE) of samples over random data augmentations; (2) proximity, which rejects the out-of-distribution outliers that may distract training; and (3) diversity, which ensures diversity in the set of sampled examples. Empirically, using ImageNet-100-LT (without labels) as the seed dataset and two "noisy" external data sources, we demonstrate that MAK can consistently improve both the overall representation quality and the class balancedness of the learned features, as evaluated via linear classifier evaluation on full-shot and few-shot settings. The code is available at: \url{https://github.com/VITA-Group/MAK