 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Storm-Resolving Atmospheric AI Simulation to the Entire Planet
Jun 30, 2026Kilometer-scale convection shapes precipitation extremes, tropical organization, and cloud feedbacks, but most global atmospheric models approximate these processes at 25-100 km resolution. Global storm-resolving physics models resolve convective systems explicitly, but at a cost -- roughly one MWh per simulated day on exascale supercomputers -- that limits long-duration simulation. We introduce STRATA (Storm-resolving Tile-based autoRegressive Atmosphere Transformer Architecture), the first autoregressive AI emulator for global storm-resolving atmospheric dynamics. STRATA is trained on the highest-resolution atmospheric dataset yet used for global AI emulation: 17 days of SCREAM physics-model output at 4.9-km resolution (~25 million grid cells) sampled every 10 minutes. Our central premise is that on 10-minute timescales atmospheric dynamics are predominantly local, so training on small spatial tiles trades scarce global temporal samples for abundant local spatial samples and enables global rollout via overlapping-tile blending. STRATA combines 3D patch embedding and local 3D neighborhood attention, a novel Stereographic Rotary Position Embedding (StereoRoPE) for grid-invariant encoding, and a pixel-space de-aliasing decoder that suppresses patch-scale rollout artifacts. An iso-FLOP scaling study reveals that km-scale emulation requires ~10x more FLOPs per grid point than coarse-resolution AI weather models, consistent with the higher information density of convective-scale dynamics. Trained on only 17 days of data, STRATA produces stable 24-hour global rollouts with realistic km-scale dynamics across diverse regimes, though large-scale biases develop with lead time. It achieves 48 simulation days per megawatt-hour -- about 50 times better energy efficiency than the SCREAM physics model -- and 741 simulated days per wall-clock day at 512 H100 GPUs. Code and dataset are publicly available.
FinSight-Net:A Physics-Aware Decoupled Network with Frequency-Domain Compensation for Underwater Fish Detection in Smart Aquaculture
Feb 23, 2026Underwater fish detection (UFD) is a core capability for smart aquaculture and marine ecological monitoring. While recent detectors improve accuracy by stacking feature extractors or introducing heavy attention modules, they often incur substantial computational overhead and, more importantly, neglect the physics that fundamentally limits UFD: wavelength-dependent absorption and turbidity-induced scattering significantly degrade contrast, blur fine structures, and introduce backscattering noise, leading to unreliable localization and recognition. To address these challenges, we propose FinSight-Net, an efficient and physics-aware detection framework tailored for complex aquaculture environments. FinSight-Net introduces a Multi-Scale Decoupled Dual-Stream Processing (MS-DDSP) bottleneck that explicitly targets frequency-specific information loss via heterogeneous convolutional branches, suppressing backscattering artifacts while compensating distorted biological cues through scale-aware and channel-weighted pathways. We further design an Efficient Path Aggregation FPN (EPA-FPN) as a detail-filling mechanism: it restores high-frequency spatial information typically attenuated in deep layers by establishing long-range skip connections and pruning redundant fusion routes, enabling robust detection of non-rigid fish targets under severe blur and turbidity. Extensive experiments on DeepFish, AquaFishSet, and our challenging UW-BlurredFish benchmark demonstrate that FinSight-Net achieves state-of-the-art performance. In particular, on UW-BlurredFish, FinSight-Net reaches 92.8% mAP, outperforming YOLOv11s by 4.8% while reducing parameters by 29.0%, providing a strong and lightweight solution for real-time automated monitoring in smart aquaculture.
A Review of Data-driven Approaches for Malicious Website Detection
May 16, 2023The detection of malicious websites has become a critical issue in cybersecurity. Therefore, this paper offers a comprehensive review of data-driven methods for detecting malicious websites. Traditional approaches and their limitations are discussed, followed by an overview of data-driven approaches. The paper establishes the data-feature-model-extension pipeline and the latest research developments of data-driven approaches, including data preprocessing, feature extraction, model construction and technology extension. Specifically, this paper compares methods using deep learning models proposed in recent years. Furthermore, the paper follows the data-feature-model-extension pipeline to discuss the challenges together with some future directions of data-driven methods in malicious website detection.
Generating Question Relevant Captions to Aid Visual Question Answering
Jun 03, 2019
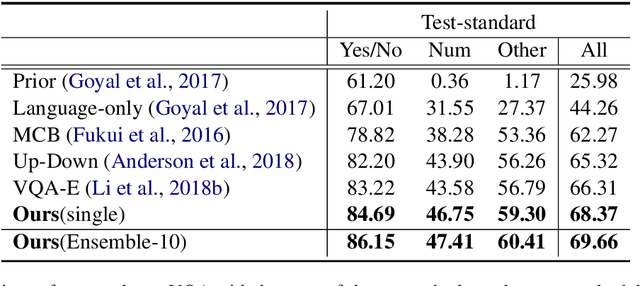
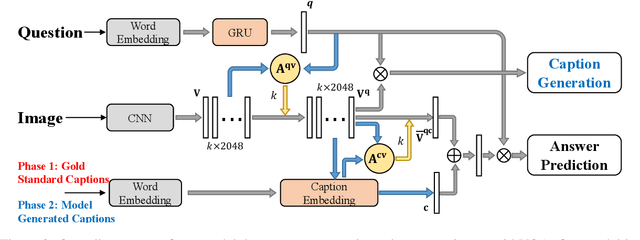

Visual question answering (VQA) and image captioning require a shared body of general knowledge connecting language and vision. We present a novel approach to improve VQA performance that exploits this connection by jointly generating captions that are targeted to help answer a specific visual question. The model is trained using an existing caption dataset by automatically determining question-relevant captions using an online gradient-based method. Experimental results on the VQA v2 challenge demonstrates that our approach obtains state-of-the-art VQA performance (e.g. 68.4% on the Test-standard set using a single model) by simultaneously generating question-relevant captions.
Joint Image Captioning and Question Answering
May 22, 2018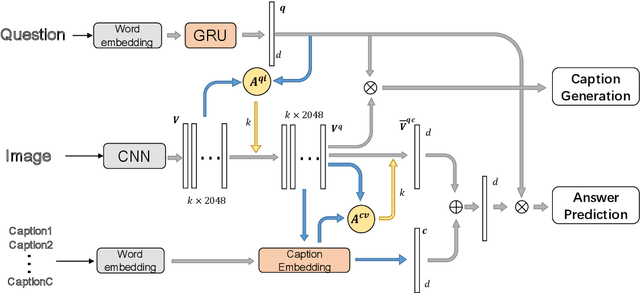
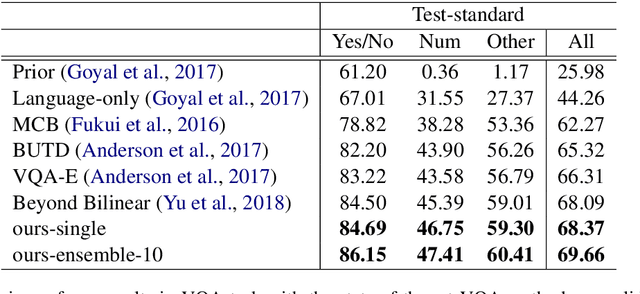
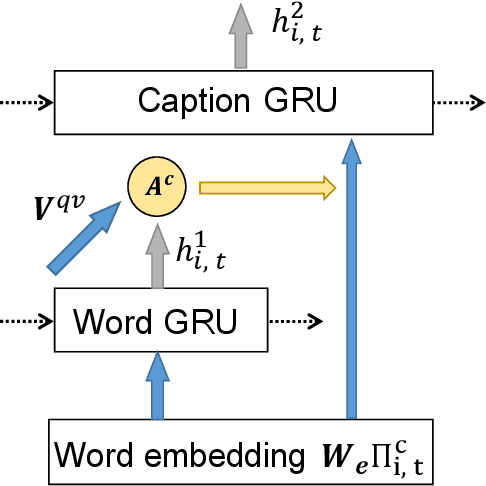

Answering visual questions need acquire daily common knowledge and model the semantic connection among different parts in images, which is too difficult for VQA systems to learn from images with the only supervision from answers. Meanwhile, image captioning systems with beam search strategy tend to generate similar captions and fail to diversely describe images. To address the aforementioned issues, we present a system to have these two tasks compensate with each other, which is capable of jointly producing image captions and answering visual questions. In particular, we utilize question and image features to generate question-related captions and use the generated captions as additional features to provide new knowledge to the VQA system. For image captioning, our system attains more informative results in term of the relative improvements on VQA tasks as well as competitive results using automated metrics. Applying our system to the VQA tasks, our results on VQA v2 dataset achieve 65.8% using generated captions and 69.1% using annotated captions in validation set and 68.4% in the test-standard set. Further, an ensemble of 10 models results in 69.7% in the test-standard split.