 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Explanations to Understand and Repair Embedding-based Entity Alignment
Dec 19, 2023Entity alignment (EA) seeks identical entities in different knowledge graphs, which is a long-standing task in the database research. Recent work leverages deep learning to embed entities in vector space and align them via nearest neighbor search. Although embedding-based EA has gained marked success in recent years, it lacks explanations for alignment decisions. In this paper, we present the first framework that can generate explanations for understanding and repairing embedding-based EA results. Given an EA pair produced by an embedding model, we first compare its neighbor entities and relations to build a matching subgraph as a local explanation. We then construct an alignment dependency graph to understand the pair from an abstract perspective. Finally, we repair the pair by resolving three types of alignment conflicts based on dependency graphs. Experiments on a variety of EA datasets demonstrate the effectiveness, generalization, and robustness of our framework in explaining and repairing embedding-based EA results.
Joint Pre-training and Local Re-training: Transferable Representation Learning on Multi-source Knowledge Graphs
Jun 05, 2023



In this paper, we present the ``joint pre-training and local re-training'' framework for learning and applying multi-source knowledge graph (KG) embeddings. We are motivated by the fact that different KGs contain complementary information to improve KG embeddings and downstream tasks. We pre-train a large teacher KG embedding model over linked multi-source KGs and distill knowledge to train a student model for a task-specific KG. To enable knowledge transfer across different KGs, we use entity alignment to build a linked subgraph for connecting the pre-trained KGs and the target KG. The linked subgraph is re-trained for three-level knowledge distillation from the teacher to the student, i.e., feature knowledge distillation, network knowledge distillation, and prediction knowledge distillation, to generate more expressive embeddings. The teacher model can be reused for different target KGs and tasks without having to train from scratch. We conduct extensive experiments to demonstrate the effectiveness and efficiency of our framework.
What Makes Entities Similar? A Similarity Flooding Perspective for Multi-sourced Knowledge Graph Embeddings
Jun 05, 2023Joint representation learning over multi-sourced knowledge graphs (KGs) yields transferable and expressive embeddings that improve downstream tasks. Entity alignment (EA) is a critical step in this process. Despite recent considerable research progress in embedding-based EA, how it works remains to be explored. In this paper, we provide a similarity flooding perspective to explain existing translation-based and aggregation-based EA models. We prove that the embedding learning process of these models actually seeks a fixpoint of pairwise similarities between entities. We also provide experimental evidence to support our theoretical analysis. We propose two simple but effective methods inspired by the fixpoint computation in similarity flooding, and demonstrate their effectiveness on benchmark datasets. Our work bridges the gap between recent embedding-based models and the conventional similarity flooding algorithm. It would improve our understanding of and increase our faith in embedding-based EA.
Newton-Cotes Graph Neural Networks: On the Time Evolution of Dynamic Systems
May 24, 2023Reasoning system dynamics is one of the most important analytical approaches for many scientific studies. With the initial state of a system as input, the recent graph neural networks (GNNs)-based methods are capable of predicting the future state distant in time with high accuracy. Although these methods have diverse designs in modeling the coordinates and interacting forces of the system, we show that they actually share a common paradigm that learns the integration of the velocity over the interval between the initial and terminal coordinates. However, their integrand is constant w.r.t. time. Inspired by this observation, we propose a new approach to predict the integration based on several velocity estimations with Newton-Cotes formulas and prove its effectiveness theoretically. Extensive experiments on several benchmarks empirically demonstrate consistent and significant improvement compared with the state-of-the-art methods.
Deep Active Alignment of Knowledge Graph Entities and Schemata
Apr 19, 2023



Knowledge graphs (KGs) store rich facts about the real world. In this paper, we study KG alignment, which aims to find alignment between not only entities but also relations and classes in different KGs. Alignment at the entity level can cross-fertilize alignment at the schema level. We propose a new KG alignment approach, called DAAKG, based on deep learning and active learning. With deep learning, it learns the embeddings of entities, relations and classes, and jointly aligns them in a semi-supervised manner. With active learning, it estimates how likely an entity, relation or class pair can be inferred, and selects the best batch for human labeling. We design two approximation algorithms for efficient solution to batch selection. Our experiments on benchmark datasets show the superior accuracy and generalization of DAAKG and validate the effectiveness of all its modules.
Lifelong Embedding Learning and Transfer for Growing Knowledge Graphs
Nov 29, 2022



Existing knowledge graph (KG) embedding models have primarily focused on static KGs. However, real-world KGs do not remain static, but rather evolve and grow in tandem with the development of KG applications. Consequently, new facts and previously unseen entities and relations continually emerge, necessitating an embedding model that can quickly learn and transfer new knowledge through growth. Motivated by this, we delve into an expanding field of KG embedding in this paper, i.e., lifelong KG embedding. We consider knowledge transfer and retention of the learning on growing snapshots of a KG without having to learn embeddings from scratch. The proposed model includes a masked KG autoencoder for embedding learning and update, with an embedding transfer strategy to inject the learned knowledge into the new entity and relation embeddings, and an embedding regularization method to avoid catastrophic forgetting. To investigate the impacts of different aspects of KG growth, we construct four datasets to evaluate the performance of lifelong KG embedding. Experimental results show that the proposed model outperforms the state-of-the-art inductive and lifelong embedding baselines.
EventEA: Benchmarking Entity Alignment for Event-centric Knowledge Graphs
Nov 05, 2022



Entity alignment is to find identical entities in different knowledge graphs (KGs) that refer to the same real-world object. Embedding-based entity alignment techniques have been drawing a lot of attention recently because they can help solve the issue of symbolic heterogeneity in different KGs. However, in this paper, we show that the progress made in the past was due to biased and unchallenging evaluation. We highlight two major flaws in existing datasets that favor embedding-based entity alignment techniques, i.e., the isomorphic graph structures in relation triples and the weak heterogeneity in attribute triples. Towards a critical evaluation of embedding-based entity alignment methods, we construct a new dataset with heterogeneous relations and attributes based on event-centric KGs. We conduct extensive experiments to evaluate existing popular methods, and find that they fail to achieve promising performance. As a new approach to this difficult problem, we propose a time-aware literal encoder for entity alignment. The dataset and source code are publicly available to foster future research. Our work calls for more effective and practical embedding-based solutions to entity alignment.
I Know What You Do Not Know: Knowledge Graph Embedding via Co-distillation Learning
Aug 28, 2022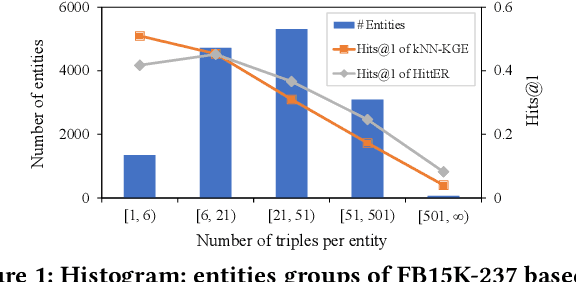

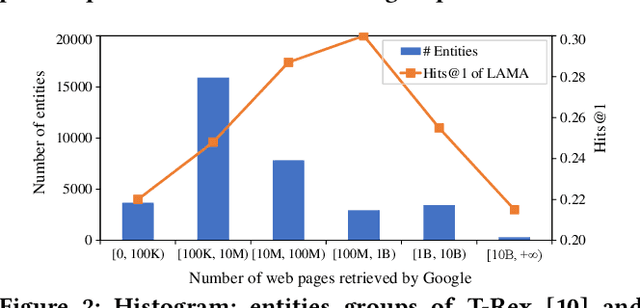

Knowledge graph (KG) embedding seeks to learn vector representations for entities and relations. Conventional models reason over graph structures, but they suffer from the issues of graph incompleteness and long-tail entities. Recent studies have used pre-trained language models to learn embeddings based on the textual information of entities and relations, but they cannot take advantage of graph structures. In the paper, we show empirically that these two kinds of features are complementary for KG embedding. To this end, we propose CoLE, a Co-distillation Learning method for KG Embedding that exploits the complementarity of graph structures and text information. Its graph embedding model employs Transformer to reconstruct the representation of an entity from its neighborhood subgraph. Its text embedding model uses a pre-trained language model to generate entity representations from the soft prompts of their names, descriptions, and relational neighbors. To let the two model promote each other, we propose co-distillation learning that allows them to distill selective knowledge from each other's prediction logits. In our co-distillation learning, each model serves as both a teacher and a student. Experiments on benchmark datasets demonstrate that the two models outperform their related baselines, and the ensemble method CoLE with co-distillation learning advances the state-of-the-art of KG embedding.
Large-scale Entity Alignment via Knowledge Graph Merging, Partitioning and Embedding
Aug 23, 2022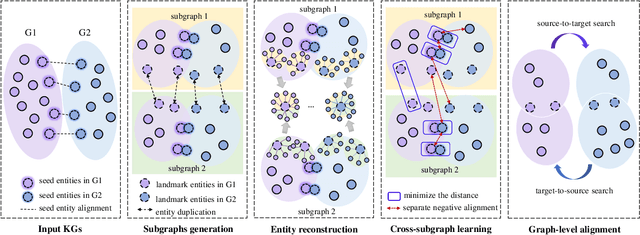
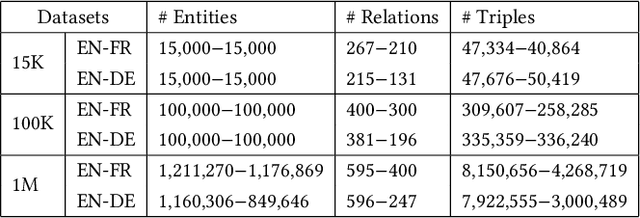
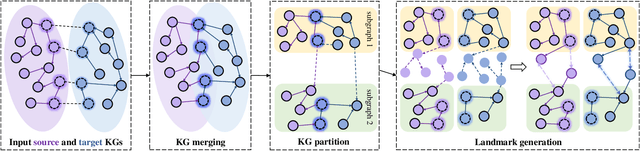
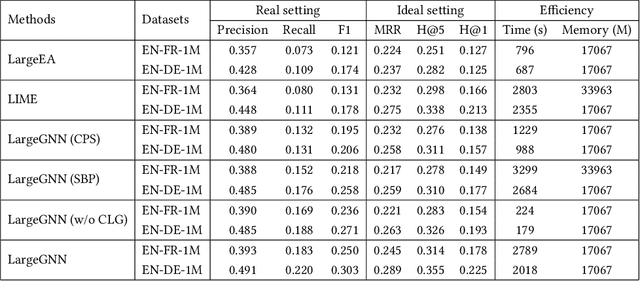
Entity alignment is a crucial task in knowledge graph fusion. However, most entity alignment approaches have the scalability problem. Recent methods address this issue by dividing large KGs into small blocks for embedding and alignment learning in each. However, such a partitioning and learning process results in an excessive loss of structure and alignment. Therefore, in this work, we propose a scalable GNN-based entity alignment approach to reduce the structure and alignment loss from three perspectives. First, we propose a centrality-based subgraph generation algorithm to recall some landmark entities serving as the bridges between different subgraphs. Second, we introduce self-supervised entity reconstruction to recover entity representations from incomplete neighborhood subgraphs, and design cross-subgraph negative sampling to incorporate entities from other subgraphs in alignment learning. Third, during the inference process, we merge the embeddings of subgraphs to make a single space for alignment search. Experimental results on the benchmark OpenEA dataset and the proposed large DBpedia1M dataset verify the effectiveness of our approach.
Inductive Knowledge Graph Reasoning for Multi-batch Emerging Entities
Aug 22, 2022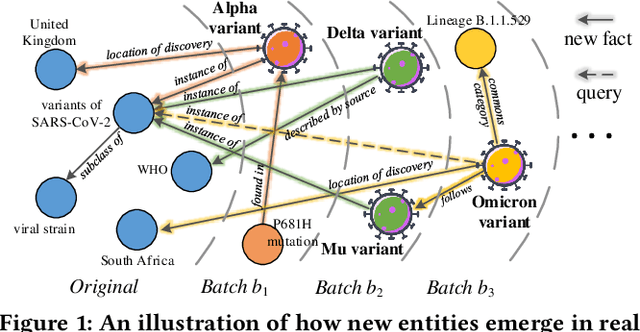
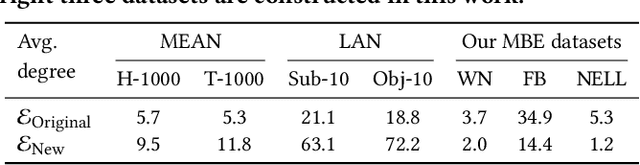
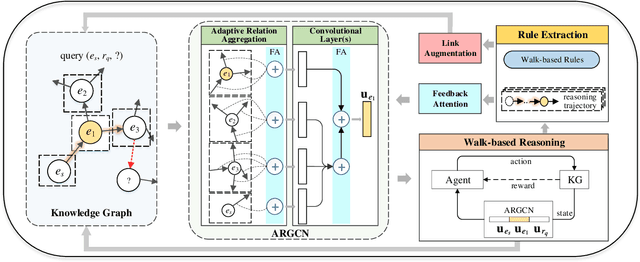

Over the years, reasoning over knowledge graphs (KGs), which aims to infer new conclusions from known facts, has mostly focused on static KGs. The unceasing growth of knowledge in real life raises the necessity to enable the inductive reasoning ability on expanding KGs. Existing inductive work assumes that new entities all emerge once in a batch, which oversimplifies the real scenario that new entities continually appear. This study dives into a more realistic and challenging setting where new entities emerge in multiple batches. We propose a walk-based inductive reasoning model to tackle the new setting. Specifically, a graph convolutional network with adaptive relation aggregation is designed to encode and update entities using their neighboring relations. To capture the varying neighbor importance, we employ a query-aware feedback attention mechanism during the aggregation. Furthermore, to alleviate the sparse link problem of new entities, we propose a link augmentation strategy to add trustworthy facts into KGs. We construct three new datasets for simulating this multi-batch emergence scenario. The experimental results show that our proposed model outperforms state-of-the-art embedding-based, walk-based and rule-based models on inductive KG reasoning.