 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMGS-SLAM: Real-time Multi-sensor Gaussian Splatting SLAM
Apr 14, 2026Real-time 3D Gaussian splatting (3DGS)-based Simultaneous Localization and Mapping (SLAM) in large-scale real-world environments remains challenging, as existing methods often struggle to jointly achieve low-latency pose estimation, 3D Gaussian reconstruction in step with incoming sensor streams, and long-term global consistency. In this paper, we present a tightly coupled LiDAR-Inertial-Visual (LIV) 3DGS-based SLAM framework for real-time pose estimation and photorealistic mapping in large-scale real-world scenes. The system executes state estimation and 3D Gaussian primitive initialization in parallel with global Gaussian optimization, thereby enabling continuous dense mapping. To improve Gaussian initialization quality and accelerate optimization convergence, we introduce a cascaded strategy that combines feed-forward predictions with voxel-based principal component analysis (voxel-PCA) geometric priors. To enhance global consistency in large scenes, we further perform loop closure directly on the optimized global Gaussian map by estimating loop constraints through Gaussian-based Generalized Iterative Closest Point (GICP) registration, followed by pose-graph optimization. In addition, we collected challenging large-scale looped outdoor SLAM sequences with hardware-synchronized LiDAR-camera-IMU and ground-truth trajectories to support realistic and comprehensive evaluation. Extensive experiments on both public datasets and our dataset demonstrate that the proposed method achieves a strong balance among real-time efficiency, localization accuracy, and rendering quality across diverse and challenging real-world scenes.
DINO-CoDT: Multi-class Collaborative Detection and Tracking with Vision Foundation Models
Jun 09, 2025Collaborative perception plays a crucial role in enhancing environmental understanding by expanding the perceptual range and improving robustness against sensor failures, which primarily involves collaborative 3D detection and tracking tasks. The former focuses on object recognition in individual frames, while the latter captures continuous instance tracklets over time. However, existing works in both areas predominantly focus on the vehicle superclass, lacking effective solutions for both multi-class collaborative detection and tracking. This limitation hinders their applicability in real-world scenarios, which involve diverse object classes with varying appearances and motion patterns. To overcome these limitations, we propose a multi-class collaborative detection and tracking framework tailored for diverse road users. We first present a detector with a global spatial attention fusion (GSAF) module, enhancing multi-scale feature learning for objects of varying sizes. Next, we introduce a tracklet RE-IDentification (REID) module that leverages visual semantics with a vision foundation model to effectively reduce ID SWitch (IDSW) errors, in cases of erroneous mismatches involving small objects like pedestrians. We further design a velocity-based adaptive tracklet management (VATM) module that adjusts the tracking interval dynamically based on object motion. Extensive experiments on the V2X-Real and OPV2V datasets show that our approach significantly outperforms existing state-of-the-art methods in both detection and tracking accuracy.
AGI-Elo: How Far Are We From Mastering A Task?
May 19, 2025As the field progresses toward Artificial General Intelligence (AGI), there is a pressing need for more comprehensive and insightful evaluation frameworks that go beyond aggregate performance metrics. This paper introduces a unified rating system that jointly models the difficulty of individual test cases and the competency of AI models (or humans) across vision, language, and action domains. Unlike existing metrics that focus solely on models, our approach allows for fine-grained, difficulty-aware evaluations through competitive interactions between models and tasks, capturing both the long-tail distribution of real-world challenges and the competency gap between current models and full task mastery. We validate the generalizability and robustness of our system through extensive experiments on multiple established datasets and models across distinct AGI domains. The resulting rating distributions offer novel perspectives and interpretable insights into task difficulty, model progression, and the outstanding challenges that remain on the path to achieving full AGI task mastery.
RMP-YOLO: A Robust Motion Predictor for Partially Observable Scenarios even if You Only Look Once
Sep 18, 2024



We introduce RMP-YOLO, a unified framework designed to provide robust motion predictions even with incomplete input data. Our key insight stems from the observation that complete and reliable historical trajectory data plays a pivotal role in ensuring accurate motion prediction. Therefore, we propose a new paradigm that prioritizes the reconstruction of intact historical trajectories before feeding them into the prediction modules. Our approach introduces a novel scene tokenization module to enhance the extraction and fusion of spatial and temporal features. Following this, our proposed recovery module reconstructs agents' incomplete historical trajectories by leveraging local map topology and interactions with nearby agents. The reconstructed, clean historical data is then integrated into the downstream prediction modules. Our framework is able to effectively handle missing data of varying lengths and remains robust against observation noise, while maintaining high prediction accuracy. Furthermore, our recovery module is compatible with existing prediction models, ensuring seamless integration. Extensive experiments validate the effectiveness of our approach, and deployment in real-world autonomous vehicles confirms its practical utility. In the 2024 Waymo Motion Prediction Competition, our method, RMP-YOLO, achieves state-of-the-art performance, securing third place.
DRAMA: An Efficient End-to-end Motion Planner for Autonomous Driving with Mamba
Aug 07, 2024



Motion planning is a challenging task to generate safe and feasible trajectories in highly dynamic and complex environments, forming a core capability for autonomous vehicles. In this paper, we propose DRAMA, the first Mamba-based end-to-end motion planner for autonomous vehicles. DRAMA fuses camera, LiDAR Bird's Eye View images in the feature space, as well as ego status information, to generate a series of future ego trajectories. Unlike traditional transformer-based methods with quadratic attention complexity for sequence length, DRAMA is able to achieve a less computationally intensive attention complexity, demonstrating potential to deal with increasingly complex scenarios. Leveraging our Mamba fusion module, DRAMA efficiently and effectively fuses the features of the camera and LiDAR modalities. In addition, we introduce a Mamba-Transformer decoder that enhances the overall planning performance. This module is universally adaptable to any Transformer-based model, especially for tasks with long sequence inputs. We further introduce a novel feature state dropout which improves the planner's robustness without increasing training and inference times. Extensive experimental results show that DRAMA achieves higher accuracy on the NAVSIM dataset compared to the baseline Transfuser, with fewer parameters and lower computational costs.
ControlMTR: Control-Guided Motion Transformer with Scene-Compliant Intention Points for Feasible Motion Prediction
Apr 17, 2024



The ability to accurately predict feasible multimodal future trajectories of surrounding traffic participants is crucial for behavior planning in autonomous vehicles. The Motion Transformer (MTR), a state-of-the-art motion prediction method, alleviated mode collapse and instability during training and enhanced overall prediction performance by replacing conventional dense future endpoints with a small set of fixed prior motion intention points. However, the fixed prior intention points make the MTR multi-modal prediction distribution over-scattered and infeasible in many scenarios. In this paper, we propose the ControlMTR framework to tackle the aforementioned issues by generating scene-compliant intention points and additionally predicting driving control commands, which are then converted into trajectories by a simple kinematic model with soft constraints. These control-generated trajectories will guide the directly predicted trajectories by an auxiliary loss function. Together with our proposed scene-compliant intention points, they can effectively restrict the prediction distribution within the road boundaries and suppress infeasible off-road predictions while enhancing prediction performance. Remarkably, without resorting to additional model ensemble techniques, our method surpasses the baseline MTR model across all performance metrics, achieving notable improvements of 5.22% in SoftmAP and a 4.15% reduction in MissRate. Our approach notably results in a 41.85% reduction in the cross-boundary rate of the MTR, effectively ensuring that the prediction distribution is confined within the drivable area.
Online Multi-Target Tracking for Maneuvering Vehicles in Dynamic Road Context
Dec 02, 2019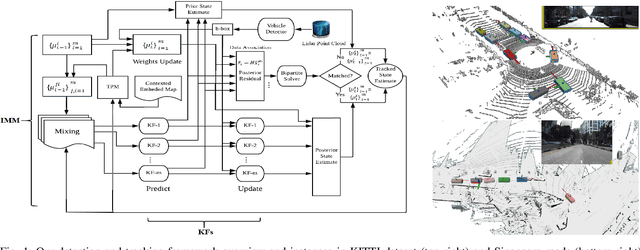
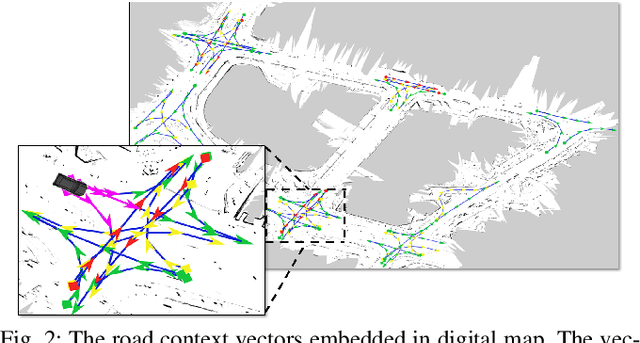
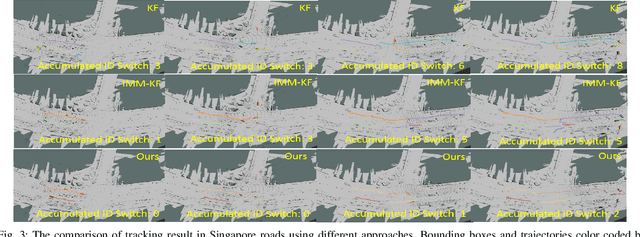
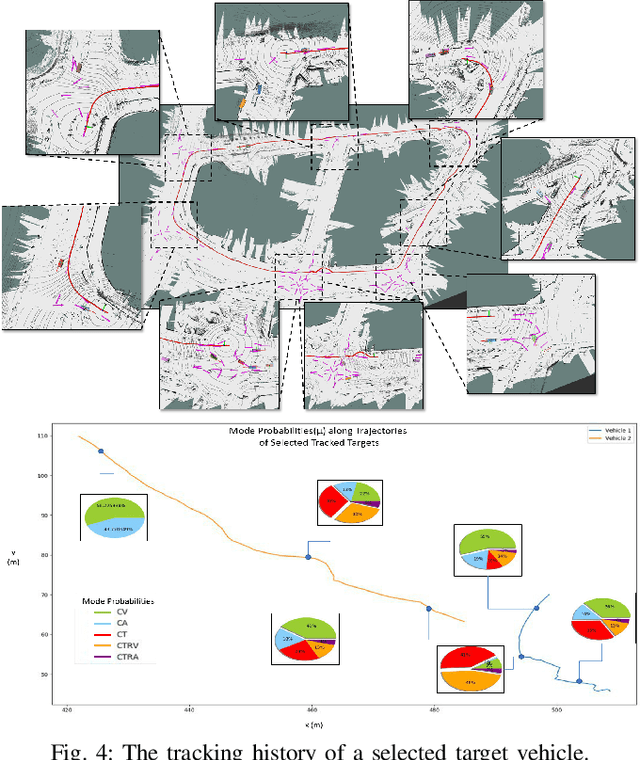
Target detection and tracking provides crucial information for motion planning and decision making in autonomous driving. This paper proposes an online multi-object tracking (MOT) framework with tracking-by-detection for maneuvering vehicles under motion uncertainty in dynamic road context. We employ a point cloud based vehicle detector to provide real-time 3D bounding boxes of detected vehicles and conduct the online bipartite optimization of the maneuver-orientated data association between the detections and the targets. Kalman Filter (KF) is adopted as the backbone for multi-object tracking. In order to entertain the maneuvering uncertainty, we leverage the interacting multiple model (IMM) approach to obtain the \textit{a-posterior} residual as the cost for each association hypothesis, which is calculated with the hybrid model posterior (after mode-switch). Road context is integrated to conduct adjustments of the time varying transition probability matrix (TPM) of the IMM to regulate the maneuvers according to road segments and traffic sign/signals, with which the data association is performed in a unified spatial-temporal fashion. Experiments show our framework is able to effectively track multiple vehicles with maneuvers subject to dynamic road context and localization drift.