 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere can AI be used? Insights from a deep ontology of work activities
Mar 21, 2026Artificial intelligence (AI) is poised to profoundly reshape how work is executed and organized, but we do not yet have deep frameworks for understanding where AI can be used. Here we provide a comprehensive ontology of work activities that can help systematically analyze and predict uses of AI. To do this, we disaggregate and then substantially reorganize the approximately 20K activities in the US Department of Labor's widely used O*NET occupational database. Next, we use this framework to classify descriptions of 13,275 AI software applications and a worldwide tally of 20.8 million robotic systems. Finally, we use the data about both these kinds of AI to generate graphical displays of how the estimated units and market values of all worldwide AI systems used today are distributed across the work activities that these systems help perform. We find a highly uneven distribution of AI market value across activities, with the top 1.6% of activities accounting for over 60% of AI market value. Most of the market value is used in information-based activities (72%), especially creating information (36%), and only 12% is used in physical activities. Interactive activities include both information-based and physical activities and account for 48% of AI market value, much of which (26%) involves transferring information. These results can be viewed as rough predictions of the AI applicability for all the different work activities down to very low levels of detail. Thus, we believe this systematic framework can help predict at a detailed level where today's AI systems can and cannot be used and how future AI capabilities may change this.
AGI-Elo: How Far Are We From Mastering A Task?
May 19, 2025As the field progresses toward Artificial General Intelligence (AGI), there is a pressing need for more comprehensive and insightful evaluation frameworks that go beyond aggregate performance metrics. This paper introduces a unified rating system that jointly models the difficulty of individual test cases and the competency of AI models (or humans) across vision, language, and action domains. Unlike existing metrics that focus solely on models, our approach allows for fine-grained, difficulty-aware evaluations through competitive interactions between models and tasks, capturing both the long-tail distribution of real-world challenges and the competency gap between current models and full task mastery. We validate the generalizability and robustness of our system through extensive experiments on multiple established datasets and models across distinct AGI domains. The resulting rating distributions offer novel perspectives and interpretable insights into task difficulty, model progression, and the outstanding challenges that remain on the path to achieving full AGI task mastery.
Supermind Ideator: Exploring generative AI to support creative problem-solving
Nov 03, 2023


Previous efforts to support creative problem-solving have included (a) techniques (such as brainstorming and design thinking) to stimulate creative ideas, and (b) software tools to record and share these ideas. Now, generative AI technologies can suggest new ideas that might never have occurred to the users, and users can then select from these ideas or use them to stimulate even more ideas. Here, we describe such a system, Supermind Ideator. The system uses a large language model (GPT 3.5) and adds prompting, fine tuning, and a user interface specifically designed to help people use creative problem-solving techniques. Some of these techniques can be applied to any problem; others are specifically intended to help generate innovative ideas about how to design groups of people and/or computers ("superminds"). We also describe our early experiences with using this system and suggest ways it could be extended to support additional techniques for other specific problem-solving domains.
A Test for Evaluating Performance in Human-Computer Systems
Jun 28, 2022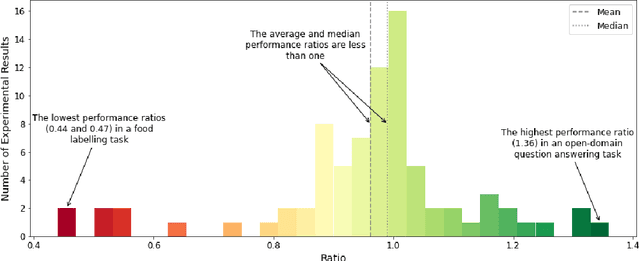
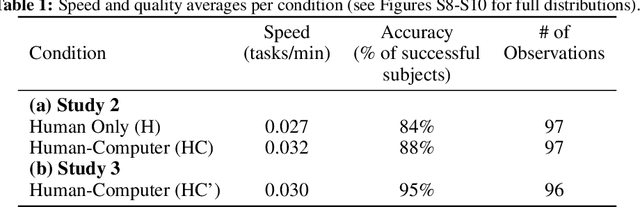

The Turing test for comparing computer performance to that of humans is well known, but, surprisingly, there is no widely used test for comparing how much better human-computer systems perform relative to humans alone, computers alone, or other baselines. Here, we show how to perform such a test using the ratio of means as a measure of effect size. Then we demonstrate the use of this test in three ways. First, in an analysis of 79 recently published experimental results, we find that, surprisingly, over half of the studies find a decrease in performance, the mean and median ratios of performance improvement are both approximately 1 (corresponding to no improvement at all), and the maximum ratio is 1.36 (a 36% improvement). Second, we experimentally investigate whether a higher performance improvement ratio is obtained when 100 human programmers generate software using GPT-3, a massive, state-of-the-art AI system. In this case, we find a speed improvement ratio of 1.27 (a 27% improvement). Finally, we find that 50 human non-programmers using GPT-3 can perform the task about as well as--and less expensively than--the human programmers. In this case, neither the non-programmers nor the computer would have been able to perform the task alone, so this is an example of a very strong form of human-computer synergy.