 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing credit mobility through stakeholder-informed AI design and adoption
Jan 09, 2026Transferring from a 2-year to a 4-year college is crucial for socioeconomic mobility, yet students often face challenges ensuring their credits are fully recognized, leading to delays in their academic progress and unexpected costs. Determining whether courses at different institutions are equivalent (i.e., articulation) is essential for successful credit transfer, as it minimizes unused credits and increases the likelihood of bachelor's degree completion. However, establishing articulation agreements remains time- and resource-intensive, as all candidate articulations are reviewed manually. Although recent efforts have explored the use of artificial intelligence to support this work, its use in articulation practice remains limited. Given these challenges and the need for scalable support, this study applies artificial intelligence to suggest articulations between institutions in collaboration with the State University of New York system, one of the largest systems of higher education in the US. To develop our methodology, we first surveyed articulation staff and faculty to assess adoption rates of baseline algorithmic recommendations and gather feedback on perceptions and concerns about these recommendations. Building on these insights, we developed a supervised alignment method that addresses superficial matching and institutional biases in catalog descriptions, achieving a 5.5-fold improvement in accuracy over previous methods. Based on articulation predictions of this method and a 61% average surveyed adoption rate among faculty and staff, these findings project a 12-fold increase in valid credit mobility opportunities that would otherwise remain unrealized. This study suggests that stakeholder-informed design of AI in higher education administration can expand student credit mobility and help reshape current institutional decision-making in course articulation.
PromptHive: Bringing Subject Matter Experts Back to the Forefront with Collaborative Prompt Engineering for Educational Content Creation
Oct 21, 2024



Involving subject matter experts in prompt engineering can guide LLM outputs toward more helpful, accurate, and tailored content that meets the diverse needs of different domains. However, iterating towards effective prompts can be challenging without adequate interface support for systematic experimentation within specific task contexts. In this work, we introduce PromptHive, a collaborative interface for prompt authoring, designed to better connect domain knowledge with prompt engineering through features that encourage rapid iteration on prompt variations. We conducted an evaluation study with ten subject matter experts in math and validated our design through two collaborative prompt-writing sessions and a learning gain study with 358 learners. Our results elucidate the prompt iteration process and validate the tool's usability, enabling non-AI experts to craft prompts that generate content comparable to human-authored materials while reducing perceived cognitive load by half and shortening the authoring process from several months to just a few hours.
Leveraging LLM-Respondents for Item Evaluation: a Psychometric Analysis
Jul 15, 2024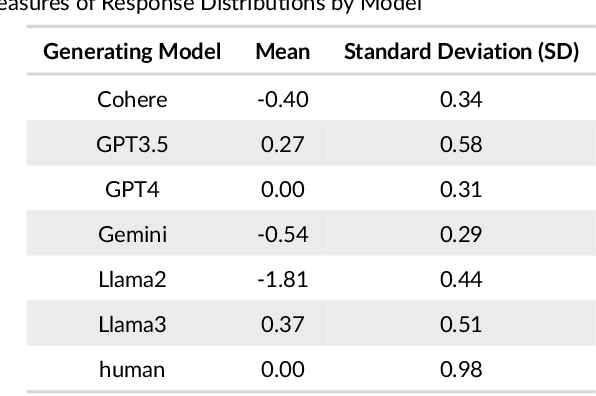
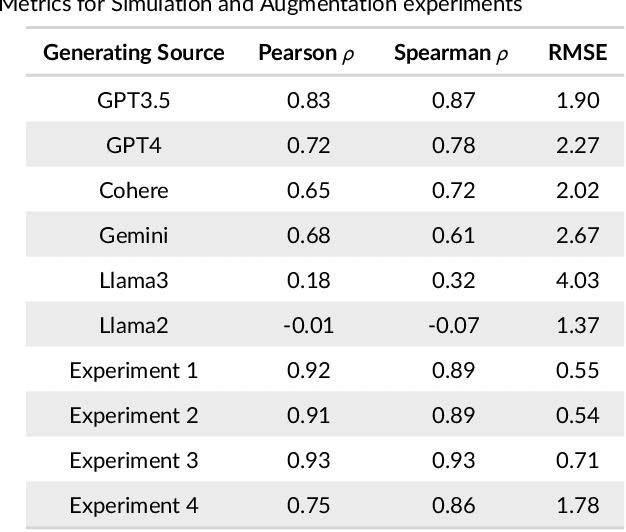
Effective educational measurement relies heavily on the curation of well-designed item pools (i.e., possessing the right psychometric properties). However, item calibration is time-consuming and costly, requiring a sufficient number of respondents for the response process. We explore using six different LLMs (GPT-3.5, GPT-4, Llama 2, Llama 3, Gemini-Pro, and Cohere Command R Plus) and various combinations of them using sampling methods to produce responses with psychometric properties similar to human answers. Results show that some LLMs have comparable or higher proficiency in College Algebra than college students. No single LLM mimics human respondents due to narrow proficiency distributions, but an ensemble of LLMs can better resemble college students' ability distribution. The item parameters calibrated by LLM-Respondents have high correlations (e.g. > 0.8 for GPT-3.5) compared to their human calibrated counterparts, and closely resemble the parameters of the human subset (e.g. 0.02 Spearman correlation difference). Several augmentation strategies are evaluated for their relative performance, with resampling methods proving most effective, enhancing the Spearman correlation from 0.89 (human only) to 0.93 (augmented human).
Representational Alignment Supports Effective Machine Teaching
Jun 06, 2024A good teacher should not only be knowledgeable; but should be able to communicate in a way that the student understands -- to share the student's representation of the world. In this work, we integrate insights from machine teaching and pragmatic communication with the burgeoning literature on representational alignment to characterize a utility curve defining a relationship between representational alignment and teacher capability for promoting student learning. To explore the characteristics of this utility curve, we design a supervised learning environment that disentangles representational alignment from teacher accuracy. We conduct extensive computational experiments with machines teaching machines, complemented by a series of experiments in which machines teach humans. Drawing on our findings that improved representational alignment with a student improves student learning outcomes (i.e., task accuracy), we design a classroom matching procedure that assigns students to teachers based on the utility curve. If we are to design effective machine teachers, it is not enough to build teachers that are accurate -- we want teachers that can align, representationally, to their students too.
Survey of Computerized Adaptive Testing: A Machine Learning Perspective
Apr 05, 2024Computerized Adaptive Testing (CAT) provides an efficient and tailored method for assessing the proficiency of examinees, by dynamically adjusting test questions based on their performance. Widely adopted across diverse fields like education, healthcare, sports, and sociology, CAT has revolutionized testing practices. While traditional methods rely on psychometrics and statistics, the increasing complexity of large-scale testing has spurred the integration of machine learning techniques. This paper aims to provide a machine learning-focused survey on CAT, presenting a fresh perspective on this adaptive testing method. By examining the test question selection algorithm at the heart of CAT's adaptivity, we shed light on its functionality. Furthermore, we delve into cognitive diagnosis models, question bank construction, and test control within CAT, exploring how machine learning can optimize these components. Through an analysis of current methods, strengths, limitations, and challenges, we strive to develop robust, fair, and efficient CAT systems. By bridging psychometric-driven CAT research with machine learning, this survey advocates for a more inclusive and interdisciplinary approach to the future of adaptive testing.
Learning gain differences between ChatGPT and human tutor generated algebra hints
Feb 14, 2023

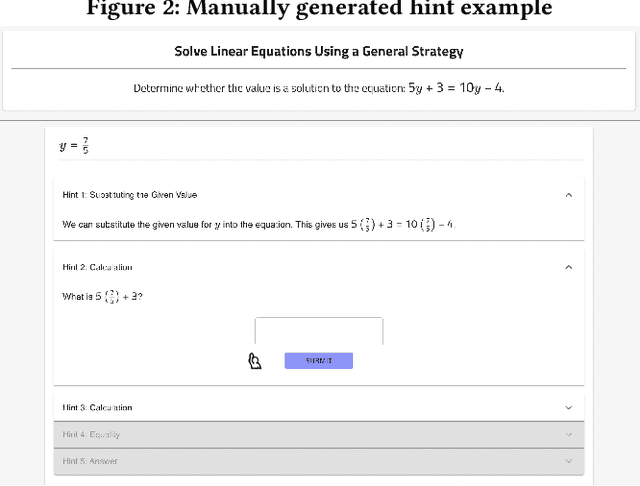

Large Language Models (LLMs), such as ChatGPT, are quickly advancing AI to the frontiers of practical consumer use and leading industries to re-evaluate how they allocate resources for content production. Authoring of open educational resources and hint content within adaptive tutoring systems is labor intensive. Should LLMs like ChatGPT produce educational content on par with human-authored content, the implications would be significant for further scaling of computer tutoring system approaches. In this paper, we conduct the first learning gain evaluation of ChatGPT by comparing the efficacy of its hints with hints authored by human tutors with 77 participants across two algebra topic areas, Elementary Algebra and Intermediate Algebra. We find that 70% of hints produced by ChatGPT passed our manual quality checks and that both human and ChatGPT conditions produced positive learning gains. However, gains were only statistically significant for human tutor created hints. Learning gains from human-created hints were substantially and statistically significantly higher than ChatGPT hints in both topic areas, though ChatGPT participants in the Intermediate Algebra experiment were near ceiling and not even with the control at pre-test. We discuss the limitations of our study and suggest several future directions for the field. Problem and hint content used in the experiment is provided for replicability.
Insights into undergraduate pathways using course load analytics
Dec 20, 2022



Course load analytics (CLA) inferred from LMS and enrollment features can offer a more accurate representation of course workload to students than credit hours and potentially aid in their course selection decisions. In this study, we produce and evaluate the first machine-learned predictions of student course load ratings and generalize our model to the full 10,000 course catalog of a large public university. We then retrospectively analyze longitudinal differences in the semester load of student course selections throughout their degree. CLA by semester shows that a student's first semester at the university is among their highest load semesters, as opposed to a credit hour-based analysis, which would indicate it is among their lowest. Investigating what role predicted course load may play in program retention, we find that students who maintain a semester load that is low as measured by credit hours but high as measured by CLA are more likely to leave their program of study. This discrepancy in course load is particularly pertinent in STEM and associated with high prerequisite courses. Our findings have implications for academic advising, institutional handling of the freshman experience, and student-facing analytics to help students better plan, anticipate, and prepare for their selected courses.
Towards Equity and Algorithmic Fairness in Student Grade Prediction
May 14, 2021
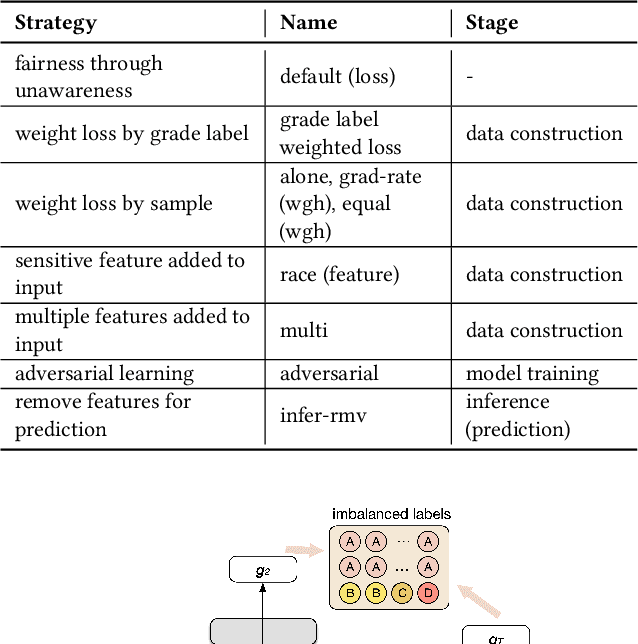
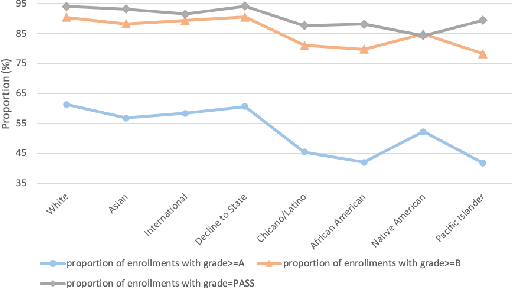
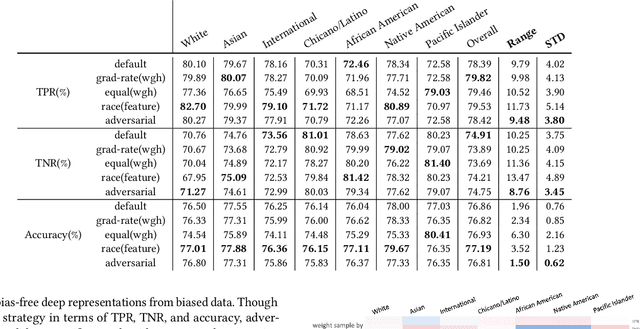
Equity of educational outcome and fairness of AI with respect to race have been topics of increasing importance in education. In this work, we address both with empirical evaluations of grade prediction in higher education, an important task to improve curriculum design, plan interventions for academic support, and offer course guidance to students. With fairness as the aim, we trial several strategies for both label and instance balancing to attempt to minimize differences in algorithm performance with respect to race. We find that an adversarial learning approach, combined with grade label balancing, achieved by far the fairest results. With equity of educational outcome as the aim, we trial strategies for boosting predictive performance on historically underserved groups and find success in sampling those groups in inverse proportion to their historic outcomes. With AI-infused technology supports increasingly prevalent on campuses, our methodologies fill a need for frameworks to consider performance trade-offs with respect to sensitive student attributes and allow institutions to instrument their AI resources in ways that are attentive to equity and fairness.
Learning Skill Equivalencies Across Platform Taxonomies
Feb 25, 2021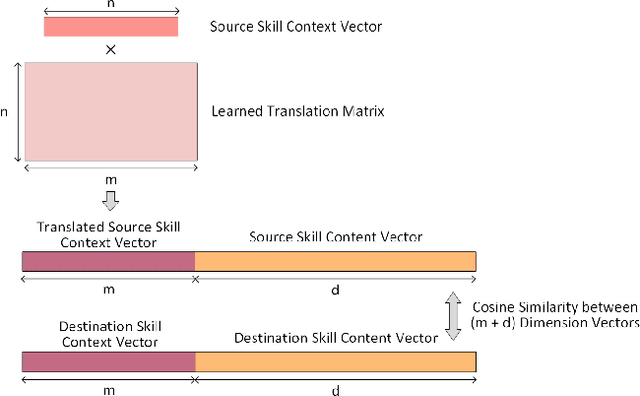
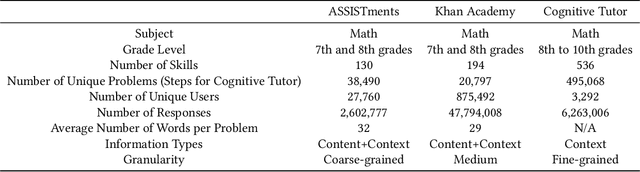
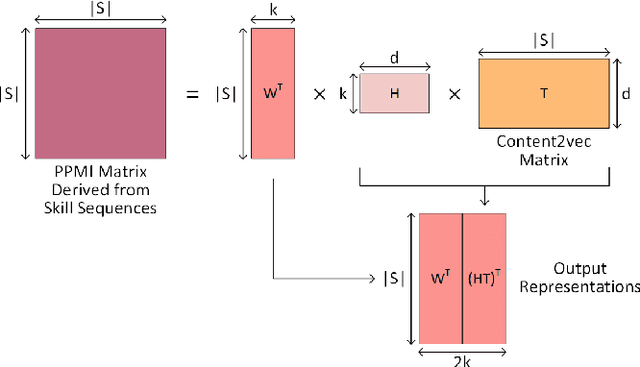
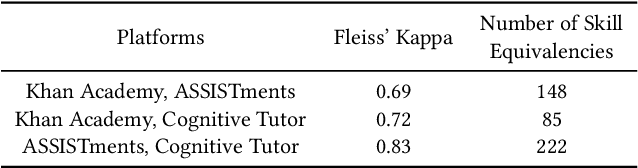
Assessment and reporting of skills is a central feature of many digital learning platforms. With students often using multiple platforms, cross-platform assessment has emerged as a new challenge. While technologies such as Learning Tools Interoperability (LTI) have enabled communication between platforms, reconciling the different skill taxonomies they employ has not been solved at scale. In this paper, we introduce and evaluate a methodology for finding and linking equivalent skills between platforms by utilizing problem content as well as the platform's clickstream data. We propose six models to represent skills as continuous real-valued vectors and leverage machine translation to map between skill spaces. The methods are tested on three digital learning platforms: ASSISTments, Khan Academy, and Cognitive Tutor. Our results demonstrate reasonable accuracy in skill equivalency prediction from a fine-grained taxonomy to a coarse-grained one, achieving an average recall@5 of 0.8 between the three platforms. Our skill translation approach has implications for aiding in the tedious, manual process of taxonomy to taxonomy mapping work, also called crosswalks, within the tutoring as well as standardized testing worlds.
Goal-based Course Recommendation
Dec 25, 2018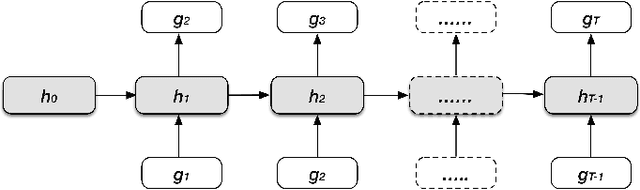
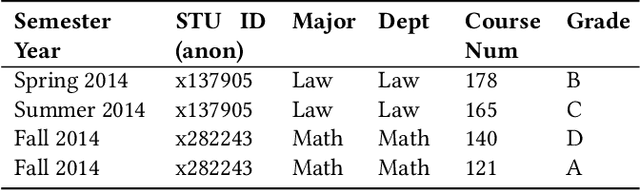
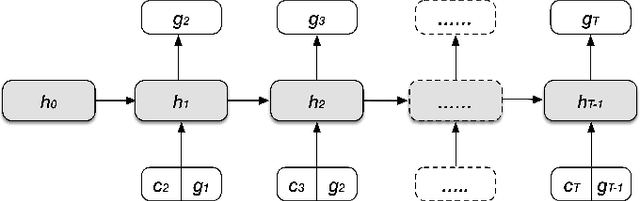
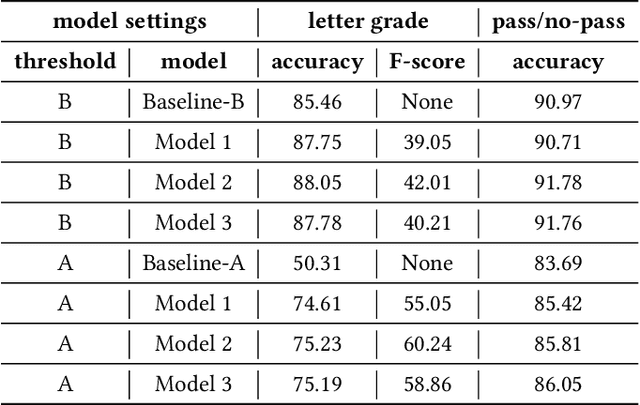
With cross-disciplinary academic interests increasing and academic advising resources over capacity, the importance of exploring data-assisted methods to support student decision making has never been higher. We build on the findings and methodologies of a quickly developing literature around prediction and recommendation in higher education and develop a novel recurrent neural network-based recommendation system for suggesting courses to help students prepare for target courses of interest, personalized to their estimated prior knowledge background and zone of proximal development. We validate the model using tests of grade prediction and the ability to recover prerequisite relationships articulated by the university. In the third validation, we run the fully personalized recommendation for students the semester before taking a historically difficult course and observe differential overlap with our would-be suggestions. While not proof of causal effectiveness, these three evaluation perspectives on the performance of the goal-based model build confidence and bring us one step closer to deployment of this personalized course preparation affordance in the wild.