 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Diagnosis of Wasted Computation in Multi-Agent LLM Systems via Failure-Aware Observability
May 31, 2026Tool-using multi-agent large language model (LLM) systems spend computation through model tokens, tool calls, retries, and code execution before producing an answer. When a run fails, final-answer evaluation reveals the endpoint but usually not the point at which the trajectory stopped making recoverable progress. This paper introduces a failure-aware observability framework for diagnosing wasted computation in multi-agent LLM traces. The framework maps recurring failure modes to online trace signals, including tool reliability, execution recovery, orchestration loops, evidence availability, information change, and budget pressure. We instantiate the framework in a three- agent question-answering system and evaluate it on 165 GAIA validation traces under identical execution caps. Operational failures remain common: 22/53 level-1 runs, 33/86 level-2 runs, and 12/26 level-3 runs fail to produce a usable final answer. The traces expose different mechanisms behind these outcomes, including insufficient evidence, repeated-action loops, max-step termination, tool-failure streaks, and execution calls that succeed without useful output. Mean token use rises from 8,152 tokens at level 1 to 16,389 tokens at level 3, while evidence availability and sentence-level support diverge. A cached 10-trace LLM-judge grounding audit shows that cheap online signals and deeper semantic metrics capture complementary layers of failure. The results position failure-aware observability as a diagnostic layer between raw execution logs and final-answer accuracy.
Architecture Matters More Than Scale: A Comparative Study of Retrieval and Memory Augmentation for Financial QA Under SME Compute Constraints
Apr 20, 2026The rapid adoption of artificial intelligence (AI) and large language models (LLMs) is transforming financial analytics by enabling natural language interfaces for reporting, decision support, and automated reasoning. However, limited empirical understanding exists regarding how different LLM-based reasoning architectures perform across realistic financial workflows, particularly under the cost, accuracy, and compliance constraints faced by small and medium-sized enterprises (SMEs). SMEs typically operate within severe infrastructure constraints, lacking cloud GPU budgets, dedicated AI teams, and API-scale inference capacity, making architectural efficiency a first-class concern. To ensure practical relevance, we introduce an explicit SME-constrained evaluation setting in which all experiments are conducted using a locally hosted 8B-parameter instruction-tuned model without cloud-scale infrastructure. This design isolates the impact of architectural choices within a realistic deployment environment. We systematically compare four reasoning architectures: baseline LLM, retrieval-augmented generation (RAG), structured long-term memory, and memory-augmented conversational reasoning across both FinQA and ConvFinQA benchmarks. Results reveal a consistent architectural inversion: structured memory improves precision in deterministic, operand-explicit tasks, while retrieval-based approaches outperform memory-centric methods in conversational, reference-implicit settings. Based on these findings, we propose a hybrid deployment framework that dynamically selects reasoning strategies to balance numerical accuracy, auditability, and infrastructure efficiency, providing a practical pathway for financial AI adoption in resource-constrained environments.
TA-Mem: Tool-Augmented Autonomous Memory Retrieval for LLM in Long-Term Conversational QA
Mar 10, 2026Large Language Model (LLM) has exhibited strong reasoning ability in text-based contexts across various domains, yet the limitation of context window poses challenges for the model on long-range inference tasks and necessitates a memory storage system. While many current storage approaches have been proposed with episodic notes and graph representations of memory, retrieval methods still primarily rely on predefined workflows or static similarity top-k over embeddings. To address this inflexibility, we introduced a novel tool-augmented autonomous memory retrieval framework (TA-Mem), which contains: (1) a memory extraction LLM agent which is prompted to adaptively chuck an input into sub-context based on semantic correlation, and extract information into structured notes, (2) a multi-indexed memory database designed for different types of query methods including both key-based lookup and similarity-based retrieval, (3) a tool-augmented memory retrieval agent which explores the memory autonomously by selecting appropriate tools provided by the database based on the user input, and decides whether to proceed to the next iteration or finalizing the response after reasoning on the fetched memories. The TA-Mem is evaluated on the LoCoMo dataset, achieving significant performance improvements over existing baseline approaches. In addition, an analysis of tool use across different question types also demonstrates the adaptivity of the proposed method.
Tiny-Critic RAG: Empowering Agentic Fallback with Parameter-Efficient Small Language Models
Mar 01, 2026Retrieval-Augmented Generation (RAG) grounds Large Language Models (LLMs) to mitigate factual hallucinations. Recent paradigms shift from static pipelines to Modular and Agentic RAG frameworks, granting models autonomy for multi-hop reasoning or self-correction. However, current reflective RAG heavily relies on massive LLMs as universal evaluators. In high-throughput systems, executing complete forward passes for billion-parameter models merely for binary routing introduces severe computational redundancy. Furthermore, in autonomous agent scenarios, inaccurate retrieval causes models to expend excessive tokens on spurious reasoning and redundant tool calls, inflating Time-to-First-Token (TTFT) and costs. We propose Tiny-Critic RAG, decoupling evaluation by deploying a parameter-efficient Small Language Model (SLM) via Low-Rank Adaptation (LoRA). Acting as a deterministic gatekeeper, Tiny-Critic employs constrained decoding and non-thinking inference modes for ultra-low latency binary routing. Evaluations on noise-injected datasets demonstrate Tiny-Critic RAG achieves routing accuracy comparable to GPT-4o-mini while reducing latency by an order of magnitude, establishing a highly cost-effective paradigm for agent deployment.
Learning Skill Equivalencies Across Platform Taxonomies
Feb 25, 2021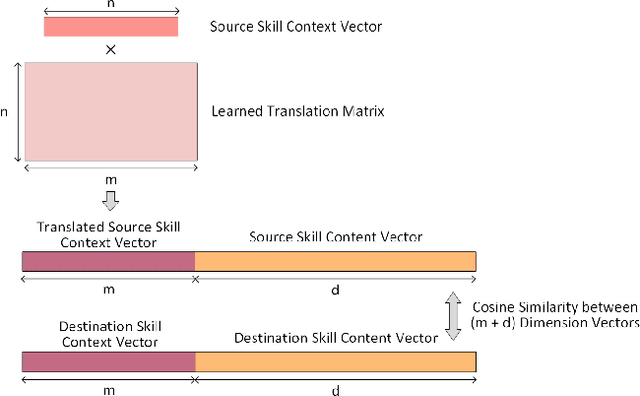
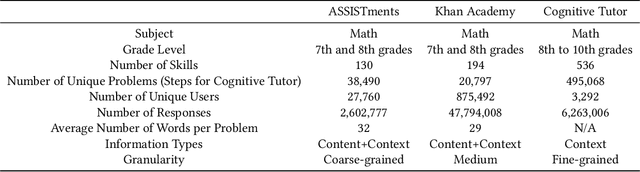
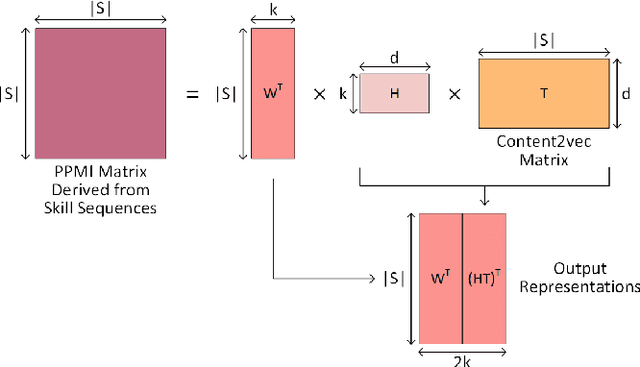
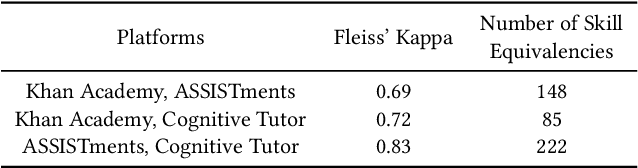
Assessment and reporting of skills is a central feature of many digital learning platforms. With students often using multiple platforms, cross-platform assessment has emerged as a new challenge. While technologies such as Learning Tools Interoperability (LTI) have enabled communication between platforms, reconciling the different skill taxonomies they employ has not been solved at scale. In this paper, we introduce and evaluate a methodology for finding and linking equivalent skills between platforms by utilizing problem content as well as the platform's clickstream data. We propose six models to represent skills as continuous real-valued vectors and leverage machine translation to map between skill spaces. The methods are tested on three digital learning platforms: ASSISTments, Khan Academy, and Cognitive Tutor. Our results demonstrate reasonable accuracy in skill equivalency prediction from a fine-grained taxonomy to a coarse-grained one, achieving an average recall@5 of 0.8 between the three platforms. Our skill translation approach has implications for aiding in the tedious, manual process of taxonomy to taxonomy mapping work, also called crosswalks, within the tutoring as well as standardized testing worlds.