 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointCSP: Cross-Sample Semantic Propagation and Stability Preservation in Self-Supervised Point Cloud Learning
May 03, 2026Scene-level point cloud self-supervised learning (PC-SSL) has demonstrated potential in enhancing the generalization capability of 3D vision models. Despite the advances in the field through existing methods, the sample-independent modeling paradigm still poses significant limitations in terms of maintaining consistent semantic representations across scenes. This challenge hinders the construction of a unified and transferable semantic space. To address this issue, we propose a PC-SSL framework based on cross-sample semantic propagation (CSP), in which samples within a batch are serialized into continuous input and processed by a state-space model to enable semantic state propagation. This mechanism explicitly models the dynamic dependencies across samples in the state space, allowing the network to establish cross-sample semantic consistency in the latent space and achieve global semantic alignment. Since serialization-based pretraining requires batch-level input organization, we further introduce an asymmetric semantic preservation distillation (SPD) during finetuning to achieve structural alignment of semantic transfer and eliminate inconsistencies caused by batch dependency. The proposed SPD ensures stable transfer of pretrained semantics through a heterogeneous input mechanism and a semantic feature alignment constraint. This enables the model to maintain structured semantic consistency and robustness under single-scene testing conditions. Extensive experiments on multiple benchmark datasets demonstrate that our method consistently outperforms state-of-the-art methods in both performance and semantic consistency.
Scalable Training of Mixture-of-Experts Models with Megatron Core
Mar 10, 2026Scaling Mixture-of-Experts (MoE) training introduces systems challenges absent in dense models. Because each token activates only a subset of experts, this sparsity allows total parameters to grow much faster than per-token computation, creating coupled constraints across memory, communication, and computation. Optimizing one dimension often shifts pressure to another, demanding co-design across the full system stack. We address these challenges for MoE training through integrated optimizations spanning memory (fine-grained recomputation, offloading, etc.), communication (optimized dispatchers, overlapping, etc.), and computation (Grouped GEMM, fusions, CUDA Graphs, etc.). The framework also provides Parallel Folding for flexible multi-dimensional parallelism, low-precision training support for FP8 and NVFP4, and efficient long-context training. On NVIDIA GB300 and GB200, it achieves 1,233/1,048 TFLOPS/GPU for DeepSeek-V3-685B and 974/919 TFLOPS/GPU for Qwen3-235B. As a performant, scalable, and production-ready open-source solution, it has been used across academia and industry for training MoE models ranging from billions to trillions of parameters on clusters scaling up to thousands of GPUs. This report explains how these techniques work, their trade-offs, and their interactions at the systems level, providing practical guidance for scaling MoE models with Megatron Core.
Equality before the Law: Legal Judgment Consistency Analysis for Fairness
Mar 25, 2021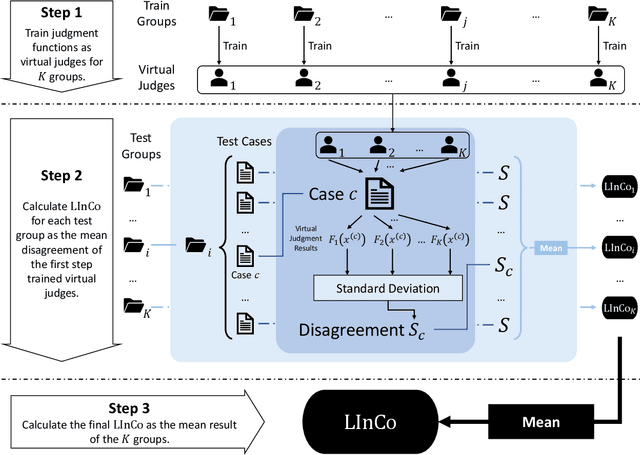
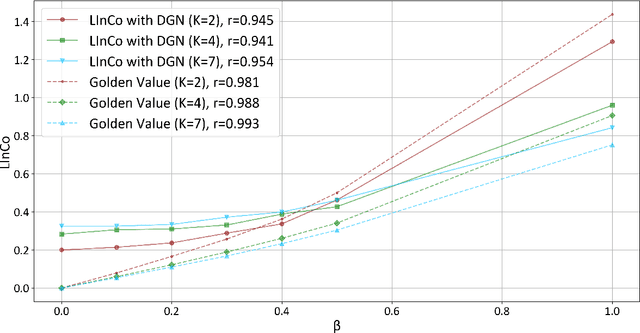
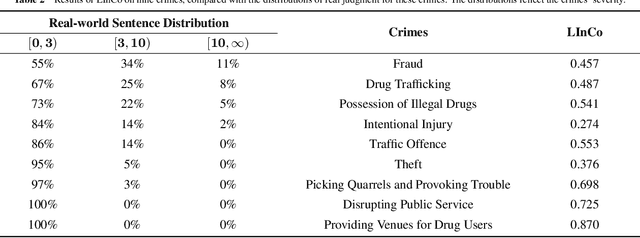

In a legal system, judgment consistency is regarded as one of the most important manifestations of fairness. However, due to the complexity of factual elements that impact sentencing in real-world scenarios, few works have been done on quantitatively measuring judgment consistency towards real-world data. In this paper, we propose an evaluation metric for judgment inconsistency, Legal Inconsistency Coefficient (LInCo), which aims to evaluate inconsistency between data groups divided by specific features (e.g., gender, region, race). We propose to simulate judges from different groups with legal judgment prediction (LJP) models and measure the judicial inconsistency with the disagreement of the judgment results given by LJP models trained on different groups. Experimental results on the synthetic data verify the effectiveness of LInCo. We further employ LInCo to explore the inconsistency in real cases and come to the following observations: (1) Both regional and gender inconsistency exist in the legal system, but gender inconsistency is much less than regional inconsistency; (2) The level of regional inconsistency varies little across different time periods; (3) In general, judicial inconsistency is negatively correlated with the severity of the criminal charges. Besides, we use LInCo to evaluate the performance of several de-bias methods, such as adversarial learning, and find that these mechanisms can effectively help LJP models to avoid suffering from data bias.