 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointCSP: Cross-Sample Semantic Propagation and Stability Preservation in Self-Supervised Point Cloud Learning
May 03, 2026Scene-level point cloud self-supervised learning (PC-SSL) has demonstrated potential in enhancing the generalization capability of 3D vision models. Despite the advances in the field through existing methods, the sample-independent modeling paradigm still poses significant limitations in terms of maintaining consistent semantic representations across scenes. This challenge hinders the construction of a unified and transferable semantic space. To address this issue, we propose a PC-SSL framework based on cross-sample semantic propagation (CSP), in which samples within a batch are serialized into continuous input and processed by a state-space model to enable semantic state propagation. This mechanism explicitly models the dynamic dependencies across samples in the state space, allowing the network to establish cross-sample semantic consistency in the latent space and achieve global semantic alignment. Since serialization-based pretraining requires batch-level input organization, we further introduce an asymmetric semantic preservation distillation (SPD) during finetuning to achieve structural alignment of semantic transfer and eliminate inconsistencies caused by batch dependency. The proposed SPD ensures stable transfer of pretrained semantics through a heterogeneous input mechanism and a semantic feature alignment constraint. This enables the model to maintain structured semantic consistency and robustness under single-scene testing conditions. Extensive experiments on multiple benchmark datasets demonstrate that our method consistently outperforms state-of-the-art methods in both performance and semantic consistency.
A Large-Scale Rich Context Query and Recommendation Dataset in Online Knowledge-Sharing
Jun 11, 2021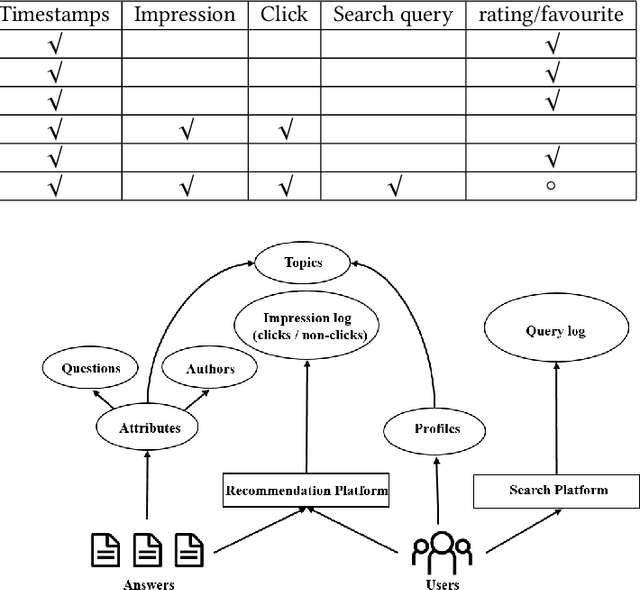
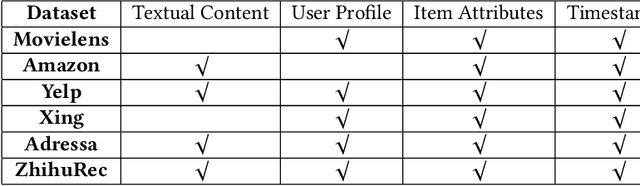

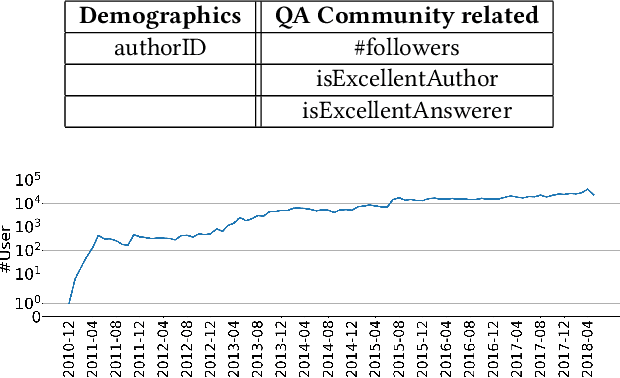
Data plays a vital role in machine learning studies. In the research of recommendation, both user behaviors and side information are helpful to model users. So, large-scale real scenario datasets with abundant user behaviors will contribute a lot. However, it is not easy to get such datasets as most of them are only hold and protected by companies. In this paper, a new large-scale dataset collected from a knowledge-sharing platform is presented, which is composed of around 100M interactions collected within 10 days, 798K users, 165K questions, 554K answers, 240K authors, 70K topics, and more than 501K user query keywords. There are also descriptions of users, answers, questions, authors, and topics, which are anonymous. Note that each user's latest query keywords have not been included in previous open datasets, which reveal users' explicit information needs. We characterize the dataset and demonstrate its potential applications for recommendation study. Multiple experiments show the dataset can be used to evaluate algorithms in general top-N recommendation, sequential recommendation, and context-aware recommendation. This dataset can also be used to integrate search and recommendation and recommendation with negative feedback. Besides, tasks beyond recommendation, such as user gender prediction, most valuable answerer identification, and high-quality answer recognition, can also use this dataset. To the best of our knowledge, this is the largest real-world interaction dataset for personalized recommendation.