 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchINR: Patch-Based Implicit Neural Representations for Efficient and Scalable Inference
Jun 24, 2026Implicit Neural Representation (INR) provides an effective approach for continuous signal modeling, but classical per-pixel inference results in quadratic growth in inference count, leading to dramatically increased computational costs in high-resolution application scenarios. To address this issue, we propose a patch-based approach that treats non-overlapping patches as fundamental processing units and predicts entire pixel patches in a single forward pass, significantly reducing the number of inference queries required. To validate the effectiveness of our approach, we propose a hardware acceleration architecture on the Field Programmable Gate Array (FPGA) platform for the INR model, which features a configurable pipeline and supports dual-precision computation. Our patch-based INR achieves comparable reconstruction quality to pixel-level INR (34.97 dB PSNR with 2 x 2 patches) while reducing inference latency by 75% with only 0.6% parameter overhead.
ROMER: Expert Replacement and Router Calibration for Robust MoE LLMs on Analog Compute-in-Memory Systems
May 12, 2026Large language models (LLMs) with mixture-of-experts (MoE) architectures achieve remarkable scalability by sparsely activating a subset of experts per token, yet their frequent expert switching creates memory bandwidth bottlenecks that compute-in-memory (CIM) architectures are well-suited to mitigate. However, analog CIM systems suffer from inherent hardware imperfections that perturb stored weights, and its negative impact on MoE-based LLMs in noisy CIM environments remains unexplored. In this work, we present the first systematic investigation of MoE-based LLMs under noise model calibrated with real chip measurements, revealing that hardware noise critically disrupts expert load balance and renders clean-trained routing decisions consistently suboptimal. Based on these findings, we propose ROMER, a post-training calibration framework that (1) replaces underactivated experts with high-frequency ones to restore load balance, and (2) recalibrates router logits via percentile-based normalization to stabilize routing under noise. Extensive experiments across multiple benchmarks demonstrate that ROMER achieves up to 58.6\%, 58.8\%, and 59.8\% reduction in perplexity under real-chip noise conditions for DeepSeek-MoE, Qwen-MoE, and OLMoE, respectively, establishing its effectiveness and generalizability across diverse MoE architectures.
Can We Trust LLMs on Memristors? Diving into Reasoning Ability under Non-Ideality
Mar 14, 2026Memristor-based analog compute-in-memory (CIM) architectures provide a promising substrate for the efficient deployment of Large Language Models (LLMs), owing to superior energy efficiency and computational density. However, these architectures suffer from precision issues caused by intrinsic non-idealities of memristors. In this paper, we first conduct a comprehensive investigation into the impact of such typical non-idealities on LLM reasoning. Empirical results indicate that reasoning capability decreases significantly but varies for distinct benchmarks. Subsequently, we systematically appraise three training-free strategies, including thinking mode, in-context learning, and module redundancy. We thus summarize valuable guidelines, i.e., shallow layer redundancy is particularly effective for improving robustness, thinking mode performs better under low noise levels but degrades at higher noise, and in-context learning reduces output length with a slight performance trade-off. Our findings offer new insights into LLM reasoning under non-ideality and practical strategies to improve robustness.
Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
Jan 20, 2026Mechanistic Interpretability (MI) has emerged as a vital approach to demystify the opaque decision-making of Large Language Models (LLMs). However, existing reviews primarily treat MI as an observational science, summarizing analytical insights while lacking a systematic framework for actionable intervention. To bridge this gap, we present a practical survey structured around the pipeline: "Locate, Steer, and Improve." We formally categorize Localizing (diagnosis) and Steering (intervention) methods based on specific Interpretable Objects to establish a rigorous intervention protocol. Furthermore, we demonstrate how this framework enables tangible improvements in Alignment, Capability, and Efficiency, effectively operationalizing MI as an actionable methodology for model optimization. The curated paper list of this work is available at https://github.com/rattlesnakey/Awesome-Actionable-MI-Survey.
XStreamVGGT: Extremely Memory-Efficient Streaming Vision Geometry Grounded Transformer with KV Cache Compression
Jan 03, 2026Learning-based 3D visual geometry models have benefited substantially from large-scale transformers. Among these, StreamVGGT leverages frame-wise causal attention for strong streaming reconstruction, but suffers from unbounded KV cache growth, leading to escalating memory consumption and inference latency as input frames accumulate. We propose XStreamVGGT, a tuning-free approach that systematically compresses the KV cache through joint pruning and quantization, enabling extremely memory-efficient streaming inference. Specifically, redundant KVs originating from multi-view inputs are pruned through efficient token importance identification, enabling a fixed memory budget. Leveraging the unique distribution of KV tensors, we incorporate KV quantization to further reduce memory consumption. Extensive evaluations show that XStreamVGGT achieves mostly negligible performance degradation while substantially reducing memory usage by 4.42$\times$ and accelerating inference by 5.48$\times$, enabling scalable and practical streaming 3D applications. The code is available at https://github.com/ywh187/XStreamVGGT/.
Binary Weight Multi-Bit Activation Quantization for Compute-in-Memory CNN Accelerators
Aug 29, 2025



Compute-in-memory (CIM) accelerators have emerged as a promising way for enhancing the energy efficiency of convolutional neural networks (CNNs). Deploying CNNs on CIM platforms generally requires quantization of network weights and activations to meet hardware constraints. However, existing approaches either prioritize hardware efficiency with binary weight and activation quantization at the cost of accuracy, or utilize multi-bit weights and activations for greater accuracy but limited efficiency. In this paper, we introduce a novel binary weight multi-bit activation (BWMA) method for CNNs on CIM-based accelerators. Our contributions include: deriving closed-form solutions for weight quantization in each layer, significantly improving the representational capabilities of binarized weights; and developing a differentiable function for activation quantization, approximating the ideal multi-bit function while bypassing the extensive search for optimal settings. Through comprehensive experiments on CIFAR-10 and ImageNet datasets, we show that BWMA achieves notable accuracy improvements over existing methods, registering gains of 1.44\%-5.46\% and 0.35\%-5.37\% on respective datasets. Moreover, hardware simulation results indicate that 4-bit activation quantization strikes the optimal balance between hardware cost and model performance.
QuadINR: Hardware-Efficient Implicit Neural Representations Through Quadratic Activation
Aug 20, 2025Implicit Neural Representations (INRs) encode discrete signals continuously while addressing spectral bias through activation functions (AFs). Previous approaches mitigate this bias by employing complex AFs, which often incur significant hardware overhead. To tackle this challenge, we introduce QuadINR, a hardware-efficient INR that utilizes piecewise quadratic AFs to achieve superior performance with dramatic reductions in hardware consumption. The quadratic functions encompass rich harmonic content in their Fourier series, delivering enhanced expressivity for high-frequency signals, as verified through Neural Tangent Kernel (NTK) analysis. We develop a unified $N$-stage pipeline framework that facilitates efficient hardware implementation of various AFs in INRs. We demonstrate FPGA implementations on the VCU128 platform and an ASIC implementation in a 28nm process. Experiments across images and videos show that QuadINR achieves up to 2.06dB PSNR improvement over prior work, with an area of only 1914$\mu$m$^2$ and a dynamic power of 6.14mW, reducing resource and power consumption by up to 97\% and improving latency by up to 93\% vs existing baselines.
Decomposing Densification in Gaussian Splatting for Faster 3D Scene Reconstruction
Jul 27, 20253D Gaussian Splatting (GS) has emerged as a powerful representation for high-quality scene reconstruction, offering compelling rendering quality. However, the training process of GS often suffers from slow convergence due to inefficient densification and suboptimal spatial distribution of Gaussian primitives. In this work, we present a comprehensive analysis of the split and clone operations during the densification phase, revealing their distinct roles in balancing detail preservation and computational efficiency. Building upon this analysis, we propose a global-to-local densification strategy, which facilitates more efficient growth of Gaussians across the scene space, promoting both global coverage and local refinement. To cooperate with the proposed densification strategy and promote sufficient diffusion of Gaussian primitives in space, we introduce an energy-guided coarse-to-fine multi-resolution training framework, which gradually increases resolution based on energy density in 2D images. Additionally, we dynamically prune unnecessary Gaussian primitives to speed up the training. Extensive experiments on MipNeRF-360, Deep Blending, and Tanks & Temples datasets demonstrate that our approach significantly accelerates training,achieving over 2x speedup with fewer Gaussian primitives and superior reconstruction performance.
Nonparametric Teaching for Graph Property Learners
May 21, 2025Inferring properties of graph-structured data, e.g., the solubility of molecules, essentially involves learning the implicit mapping from graphs to their properties. This learning process is often costly for graph property learners like Graph Convolutional Networks (GCNs). To address this, we propose a paradigm called Graph Neural Teaching (GraNT) that reinterprets the learning process through a novel nonparametric teaching perspective. Specifically, the latter offers a theoretical framework for teaching implicitly defined (i.e., nonparametric) mappings via example selection. Such an implicit mapping is realized by a dense set of graph-property pairs, with the GraNT teacher selecting a subset of them to promote faster convergence in GCN training. By analytically examining the impact of graph structure on parameter-based gradient descent during training, and recasting the evolution of GCNs--shaped by parameter updates--through functional gradient descent in nonparametric teaching, we show for the first time that teaching graph property learners (i.e., GCNs) is consistent with teaching structure-aware nonparametric learners. These new findings readily commit GraNT to enhancing learning efficiency of the graph property learner, showing significant reductions in training time for graph-level regression (-36.62%), graph-level classification (-38.19%), node-level regression (-30.97%) and node-level classification (-47.30%), all while maintaining its generalization performance.
HaLoRA: Hardware-aware Low-Rank Adaptation for Large Language Models Based on Hybrid Compute-in-Memory Architecture
Feb 27, 2025
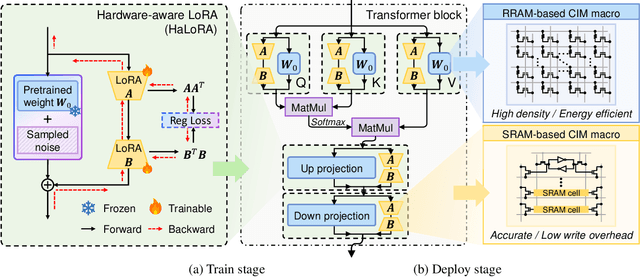
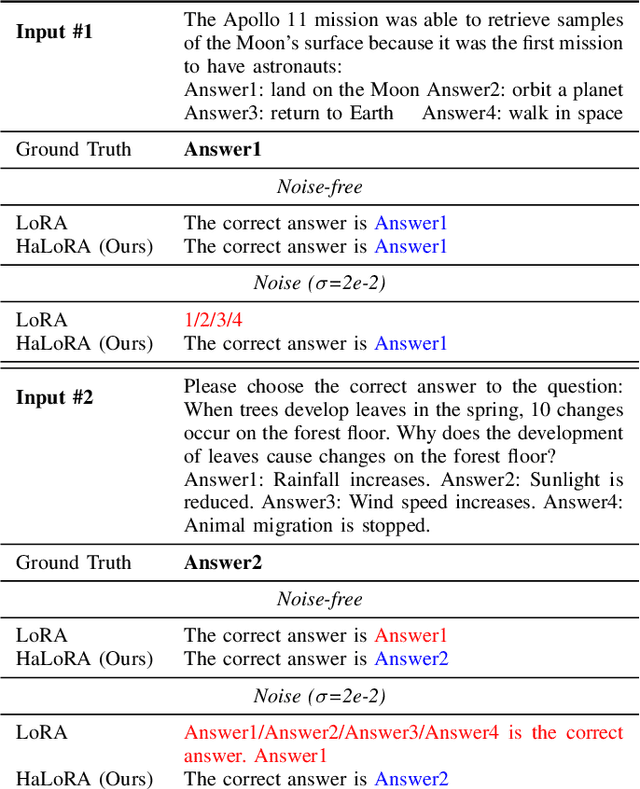
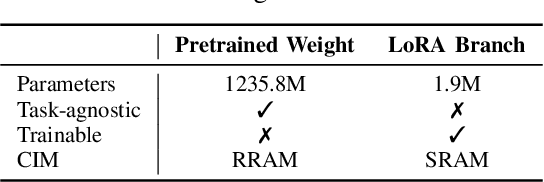
Low-rank adaptation (LoRA) is a predominant parameter-efficient finetuning method to adapt large language models (LLMs) for downstream tasks. In this paper, we first propose to deploy the LoRA-finetuned LLMs on the hybrid compute-in-memory (CIM) architecture (i.e., pretrained weights onto RRAM and LoRA onto SRAM). To address performance degradation from RRAM's inherent noise, we design a novel Hardware-aware Low-rank Adaption (HaLoRA) method, aiming to train a LoRA branch that is both robust and accurate by aligning the training objectives under both ideal and noisy conditions. Experiments finetuning LLaMA 3.2 1B and 3B demonstrate HaLoRA's effectiveness across multiple reasoning tasks, achieving up to 22.7 improvement in average score while maintaining robustness at various noise levels.