 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchINR: Patch-Based Implicit Neural Representations for Efficient and Scalable Inference
Jun 24, 2026Implicit Neural Representation (INR) provides an effective approach for continuous signal modeling, but classical per-pixel inference results in quadratic growth in inference count, leading to dramatically increased computational costs in high-resolution application scenarios. To address this issue, we propose a patch-based approach that treats non-overlapping patches as fundamental processing units and predicts entire pixel patches in a single forward pass, significantly reducing the number of inference queries required. To validate the effectiveness of our approach, we propose a hardware acceleration architecture on the Field Programmable Gate Array (FPGA) platform for the INR model, which features a configurable pipeline and supports dual-precision computation. Our patch-based INR achieves comparable reconstruction quality to pixel-level INR (34.97 dB PSNR with 2 x 2 patches) while reducing inference latency by 75% with only 0.6% parameter overhead.
Can We Trust LLMs on Memristors? Diving into Reasoning Ability under Non-Ideality
Mar 14, 2026Memristor-based analog compute-in-memory (CIM) architectures provide a promising substrate for the efficient deployment of Large Language Models (LLMs), owing to superior energy efficiency and computational density. However, these architectures suffer from precision issues caused by intrinsic non-idealities of memristors. In this paper, we first conduct a comprehensive investigation into the impact of such typical non-idealities on LLM reasoning. Empirical results indicate that reasoning capability decreases significantly but varies for distinct benchmarks. Subsequently, we systematically appraise three training-free strategies, including thinking mode, in-context learning, and module redundancy. We thus summarize valuable guidelines, i.e., shallow layer redundancy is particularly effective for improving robustness, thinking mode performs better under low noise levels but degrades at higher noise, and in-context learning reduces output length with a slight performance trade-off. Our findings offer new insights into LLM reasoning under non-ideality and practical strategies to improve robustness.
HaLoRA: Hardware-aware Low-Rank Adaptation for Large Language Models Based on Hybrid Compute-in-Memory Architecture
Feb 27, 2025
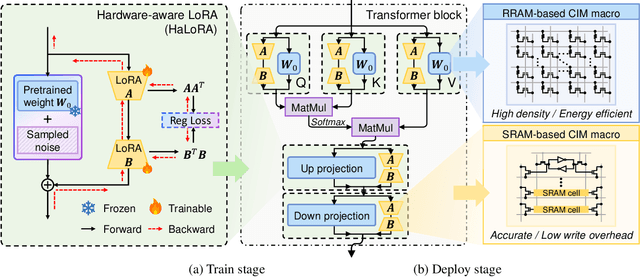
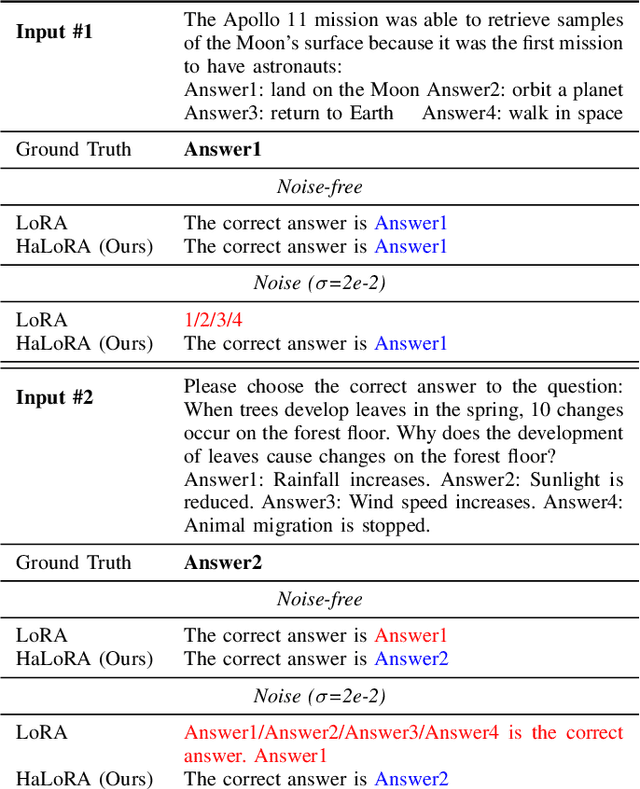
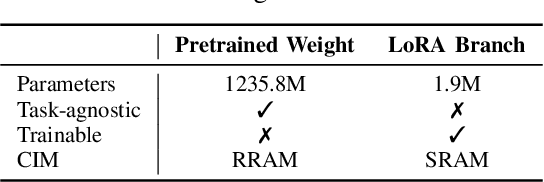
Low-rank adaptation (LoRA) is a predominant parameter-efficient finetuning method to adapt large language models (LLMs) for downstream tasks. In this paper, we first propose to deploy the LoRA-finetuned LLMs on the hybrid compute-in-memory (CIM) architecture (i.e., pretrained weights onto RRAM and LoRA onto SRAM). To address performance degradation from RRAM's inherent noise, we design a novel Hardware-aware Low-rank Adaption (HaLoRA) method, aiming to train a LoRA branch that is both robust and accurate by aligning the training objectives under both ideal and noisy conditions. Experiments finetuning LLaMA 3.2 1B and 3B demonstrate HaLoRA's effectiveness across multiple reasoning tasks, achieving up to 22.7 improvement in average score while maintaining robustness at various noise levels.
Stochastic Multivariate Universal-Radix Finite-State Machine: a Theoretically and Practically Elegant Nonlinear Function Approximator
May 03, 2024



Nonlinearities are crucial for capturing complex input-output relationships especially in deep neural networks. However, nonlinear functions often incur various hardware and compute overheads. Meanwhile, stochastic computing (SC) has emerged as a promising approach to tackle this challenge by trading output precision for hardware simplicity. To this end, this paper proposes a first-of-its-kind stochastic multivariate universal-radix finite-state machine (SMURF) that harnesses SC for hardware-simplistic multivariate nonlinear function generation at high accuracy. We present the finite-state machine (FSM) architecture for SMURF, as well as analytical derivations of sampling gate coefficients for accurately approximating generic nonlinear functions. Experiments demonstrate the superiority of SMURF, requiring only 16.07% area and 14.45% power consumption of Taylor-series approximation, and merely 2.22% area of look-up table (LUT) schemes.