 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Self-Driving Trigger at the LHC: Adaptive Response in Real Time
Jan 13, 2026Real-time data filtering and selection -- or trigger -- systems at high-throughput scientific facilities such as the experiments at the Large Hadron Collider (LHC) must process extremely high-rate data streams under stringent bandwidth, latency, and storage constraints. Yet these systems are typically designed as static, hand-tuned menus of selection criteria grounded in prior knowledge and simulation. In this work, we further explore the concept of a self-driving trigger, an autonomous data-filtering framework that reallocates resources and adjusts thresholds dynamically in real-time to optimize signal efficiency, rate stability, and computational cost as instrumentation and environmental conditions evolve. We introduce a benchmark ecosystem to emulate realistic collider scenarios and demonstrate real-time optimization of a menu including canonical energy sum triggers as well as modern anomaly-detection algorithms that target non-standard event topologies using machine learning. Using simulated data streams and publicly available collision data from the Compact Muon Solenoid (CMS) experiment, we demonstrate the capability to dynamically and automatically optimize trigger performance under specific cost objectives without manual retuning. Our adaptive strategy shifts trigger design from static menus with heuristic tuning to intelligent, automated, data-driven control, unlocking greater flexibility and discovery potential in future high-energy physics analyses.
Learning to Reason in 4D: Dynamic Spatial Understanding for Vision Language Models
Dec 23, 2025Vision-language models (VLM) excel at general understanding yet remain weak at dynamic spatial reasoning (DSR), i.e., reasoning about the evolvement of object geometry and relationship in 3D space over time, largely due to the scarcity of scalable 4D-aware training resources. To bridge this gap across aspects of dataset, benchmark and model, we introduce DSR Suite. First, we propose an automated pipeline that generates multiple-choice question-answer pairs from in-the-wild videos for DSR. By leveraging modern vision foundation models, the pipeline extracts rich geometric and motion information, including camera poses, local point clouds, object masks, orientations, and 3D trajectories. These geometric cues enable the construction of DSR-Train for learning and further human-refined DSR-Bench for evaluation. Compared with previous works, our data emphasize (i) in-the-wild video sources, (ii) object- and scene-level 3D requirements, (iii) viewpoint transformations, (iv) multi-object interactions, and (v) fine-grained, procedural answers. Beyond data, we propose a lightweight Geometry Selection Module (GSM) to seamlessly integrate geometric priors into VLMs, which condenses question semantics and extracts question-relevant knowledge from pretrained 4D reconstruction priors into a compact set of geometry tokens. This targeted extraction avoids overwhelming the model with irrelevant knowledge. Experiments show that integrating DSR-Train and GSM into Qwen2.5-VL-7B significantly enhances its dynamic spatial reasoning capability, while maintaining accuracy on general video understanding benchmarks.
MMhops-R1: Multimodal Multi-hop Reasoning
Dec 16, 2025


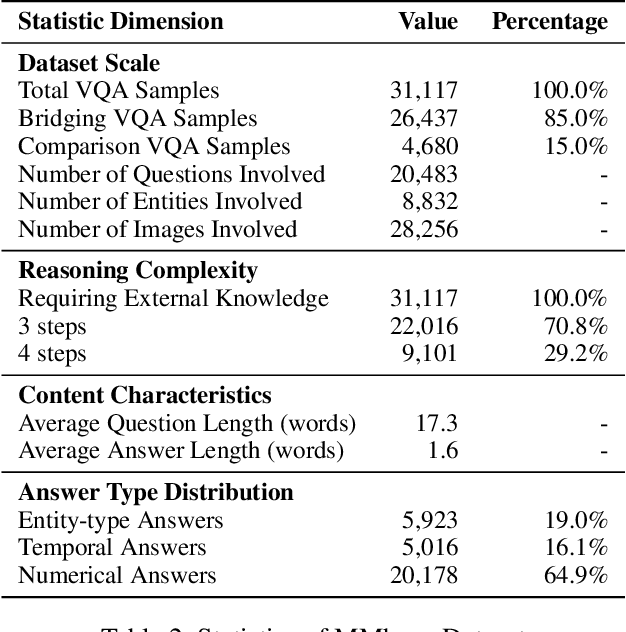
The ability to perform multi-modal multi-hop reasoning by iteratively integrating information across various modalities and external knowledge is critical for addressing complex real-world challenges. However, existing Multi-modal Large Language Models (MLLMs) are predominantly limited to single-step reasoning, as existing benchmarks lack the complexity needed to evaluate and drive multi-hop abilities. To bridge this gap, we introduce MMhops, a novel, large-scale benchmark designed to systematically evaluate and foster multi-modal multi-hop reasoning. MMhops dataset comprises two challenging task formats, Bridging and Comparison, which necessitate that models dynamically construct complex reasoning chains by integrating external knowledge. To tackle the challenges posed by MMhops, we propose MMhops-R1, a novel multi-modal Retrieval-Augmented Generation (mRAG) framework for dynamic reasoning. Our framework utilizes reinforcement learning to optimize the model for autonomously planning reasoning paths, formulating targeted queries, and synthesizing multi-level information. Comprehensive experiments demonstrate that MMhops-R1 significantly outperforms strong baselines on MMhops, highlighting that dynamic planning and multi-modal knowledge integration are crucial for complex reasoning. Moreover, MMhops-R1 demonstrates strong generalization to tasks requiring fixed-hop reasoning, underscoring the robustness of our dynamic planning approach. In conclusion, our work contributes a challenging new benchmark and a powerful baseline model, and we will release the associated code, data, and weights to catalyze future research in this critical area.
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
SAGA: Open-World Mobile Manipulation via Structured Affordance Grounding
Dec 14, 2025



We present SAGA, a versatile and adaptive framework for visuomotor control that can generalize across various environments, task objectives, and user specifications. To efficiently learn such capability, our key idea is to disentangle high-level semantic intent from low-level visuomotor control by explicitly grounding task objectives in the observed environment. Using an affordance-based task representation, we express diverse and complex behaviors in a unified, structured form. By leveraging multimodal foundation models, SAGA grounds the proposed task representation to the robot's visual observation as 3D affordance heatmaps, highlighting task-relevant entities while abstracting away spurious appearance variations that would hinder generalization. These grounded affordances enable us to effectively train a conditional policy on multi-task demonstration data for whole-body control. In a unified framework, SAGA can solve tasks specified in different forms, including language instructions, selected points, and example demonstrations, enabling both zero-shot execution and few-shot adaptation. We instantiate SAGA on a quadrupedal manipulator and conduct extensive experiments across eleven real-world tasks. SAGA consistently outperforms end-to-end and modular baselines by substantial margins. Together, these results demonstrate that structured affordance grounding offers a scalable and effective pathway toward generalist mobile manipulation.
Deep Pathomic Learning Defines Prognostic Subtypes and Molecular Drivers in Colorectal Cancer
Nov 19, 2025



Precise prognostic stratification of colorectal cancer (CRC) remains a major clinical challenge due to its high heterogeneity. The conventional TNM staging system is inadequate for personalized medicine. We aimed to develop and validate a novel multiple instance learning model TDAM-CRC using histopathological whole-slide images for accurate prognostic prediction and to uncover its underlying molecular mechanisms. We trained the model on the TCGA discovery cohort (n=581), validated it in an independent external cohort (n=1031), and further we integrated multi-omics data to improve model interpretability and identify novel prognostic biomarkers. The results demonstrated that the TDAM-CRC achieved robust risk stratification in both cohorts. Its predictive performance significantly outperformed the conventional clinical staging system and multiple state-of-the-art models. The TDAM-CRC risk score was confirmed as an independent prognostic factor in multivariable analysis. Multi-omics analysis revealed that the high-risk subtype is closely associated with metabolic reprogramming and an immunosuppressive tumor microenvironment. Through interaction network analysis, we identified and validated Mitochondrial Ribosomal Protein L37 (MRPL37) as a key hub gene linking deep pathomic features to clinical prognosis. We found that high expression of MRPL37, driven by promoter hypomethylation, serves as an independent biomarker of favorable prognosis. Finally, we constructed a nomogram incorporating the TDAM-CRC risk score and clinical factors to provide a precise and interpretable clinical decision-making tool for CRC patients. Our AI-driven pathological model TDAM-CRC provides a robust tool for improved CRC risk stratification, reveals new molecular targets, and facilitates personalized clinical decision-making.
Transformers Provably Learn Chain-of-Thought Reasoning with Length Generalization
Nov 10, 2025The ability to reason lies at the core of artificial intelligence (AI), and challenging problems usually call for deeper and longer reasoning to tackle. A crucial question about AI reasoning is whether models can extrapolate learned reasoning patterns to solve harder tasks with longer chain-of-thought (CoT). In this work, we present a theoretical analysis of transformers learning on synthetic state-tracking tasks with gradient descent. We mathematically prove how the algebraic structure of state-tracking problems governs the degree of extrapolation of the learned CoT. Specifically, our theory characterizes the length generalization of transformers through the mechanism of attention concentration, linking the retrieval robustness of the attention layer to the state-tracking task structure of long-context reasoning. Moreover, for transformers with limited reasoning length, we prove that a recursive self-training scheme can progressively extend the range of solvable problem lengths. To our knowledge, we provide the first optimization guarantee that constant-depth transformers provably learn $\mathsf{NC}^1$-complete problems with CoT, significantly going beyond prior art confined in $\mathsf{TC}^0$, unless the widely held conjecture $\mathsf{TC}^0 \neq \mathsf{NC}^1$ fails. Finally, we present a broad set of experiments supporting our theoretical results, confirming the length generalization behaviors and the mechanism of attention concentration.
Connections between reinforcement learning with feedback,test-time scaling, and diffusion guidance: An anthology
Sep 04, 2025In this note, we reflect on several fundamental connections among widely used post-training techniques. We clarify some intimate connections and equivalences between reinforcement learning with human feedback, reinforcement learning with internal feedback, and test-time scaling (particularly soft best-of-$N$ sampling), while also illuminating intrinsic links between diffusion guidance and test-time scaling. Additionally, we introduce a resampling approach for alignment and reward-directed diffusion models, sidestepping the need for explicit reinforcement learning techniques.
Cognitive Structure Generation: From Educational Priors to Policy Optimization
Aug 18, 2025Cognitive structure is a student's subjective organization of an objective knowledge system, reflected in the psychological construction of concepts and their relations. However, cognitive structure assessment remains a long-standing challenge in student modeling and psychometrics, persisting as a foundational yet largely unassessable concept in educational practice. This paper introduces a novel framework, Cognitive Structure Generation (CSG), in which we first pretrain a Cognitive Structure Diffusion Probabilistic Model (CSDPM) to generate students' cognitive structures from educational priors, and then further optimize its generative process as a policy with hierarchical reward signals via reinforcement learning to align with genuine cognitive development levels during students' learning processes. Experimental results on four popular real-world education datasets show that cognitive structures generated by CSG offer more comprehensive and effective representations for student modeling, substantially improving performance on KT and CD tasks while enhancing interpretability.
Direct Regret Optimization in Bayesian Optimization
Jul 09, 2025Bayesian optimization (BO) is a powerful paradigm for optimizing expensive black-box functions. Traditional BO methods typically rely on separate hand-crafted acquisition functions and surrogate models for the underlying function, and often operate in a myopic manner. In this paper, we propose a novel direct regret optimization approach that jointly learns the optimal model and non-myopic acquisition by distilling from a set of candidate models and acquisitions, and explicitly targets minimizing the multi-step regret. Our framework leverages an ensemble of Gaussian Processes (GPs) with varying hyperparameters to generate simulated BO trajectories, each guided by an acquisition function chosen from a pool of conventional choices, until a Bayesian early stop criterion is met. These simulated trajectories, capturing multi-step exploration strategies, are used to train an end-to-end decision transformer that directly learns to select next query points aimed at improving the ultimate objective. We further adopt a dense training--sparse learning paradigm: The decision transformer is trained offline with abundant simulated data sampled from ensemble GPs and acquisitions, while a limited number of real evaluations refine the GPs online. Experimental results on synthetic and real-world benchmarks suggest that our method consistently outperforms BO baselines, achieving lower simple regret and demonstrating more robust exploration in high-dimensional or noisy settings.