 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRhetorical Text-to-Image Generation via Two-layer Diffusion Policy Optimization
May 28, 2025Generating images from rhetorical languages remains a critical challenge for text-to-image models. Even state-of-the-art (SOTA) multimodal large language models (MLLM) fail to generate images based on the hidden meaning inherent in rhetorical language--despite such content being readily mappable to visual representations by humans. A key limitation is that current models emphasize object-level word embedding alignment, causing metaphorical expressions to steer image generation towards their literal visuals and overlook the intended semantic meaning. To address this, we propose Rhet2Pix, a framework that formulates rhetorical text-to-image generation as a multi-step policy optimization problem, incorporating a two-layer MDP diffusion module. In the outer layer, Rhet2Pix converts the input prompt into incrementally elaborated sub-sentences and executes corresponding image-generation actions, constructing semantically richer visuals. In the inner layer, Rhet2Pix mitigates reward sparsity during image generation by discounting the final reward and optimizing every adjacent action pair along the diffusion denoising trajectory. Extensive experiments demonstrate the effectiveness of Rhet2Pix in rhetorical text-to-image generation. Our model outperforms SOTA MLLMs such as GPT-4o, Grok-3 and leading academic baselines across both qualitative and quantitative evaluations. The code and dataset used in this work are publicly available.
Joint Graph Convolution for Analyzing Brain Structural and Functional Connectome
Oct 27, 2022The white-matter (micro-)structural architecture of the brain promotes synchrony among neuronal populations, giving rise to richly patterned functional connections. A fundamental problem for systems neuroscience is determining the best way to relate structural and functional networks quantified by diffusion tensor imaging and resting-state functional MRI. As one of the state-of-the-art approaches for network analysis, graph convolutional networks (GCN) have been separately used to analyze functional and structural networks, but have not been applied to explore inter-network relationships. In this work, we propose to couple the two networks of an individual by adding inter-network edges between corresponding brain regions, so that the joint structure-function graph can be directly analyzed by a single GCN. The weights of inter-network edges are learnable, reflecting non-uniform structure-function coupling strength across the brain. We apply our Joint-GCN to predict age and sex of 662 participants from the public dataset of the National Consortium on Alcohol and Neurodevelopment in Adolescence (NCANDA) based on their functional and micro-structural white-matter networks. Our results support that the proposed Joint-GCN outperforms existing multi-modal graph learning approaches for analyzing structural and functional networks.
Deconvolutional Networks on Graph Data
Oct 29, 2021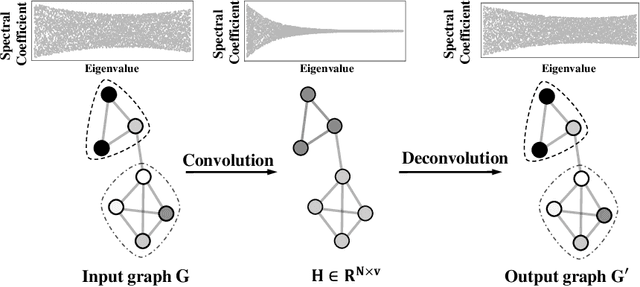
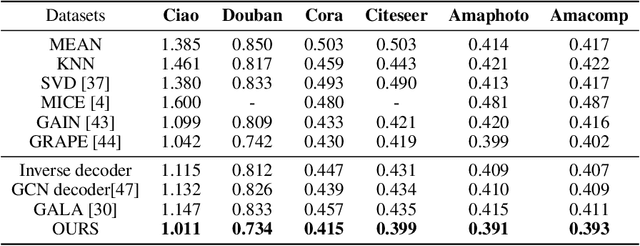
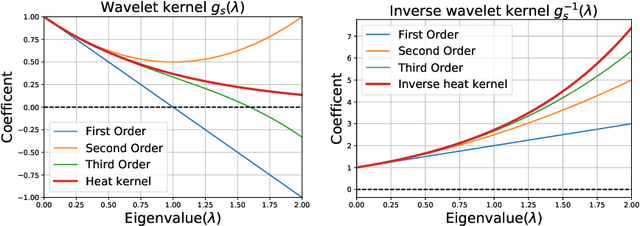
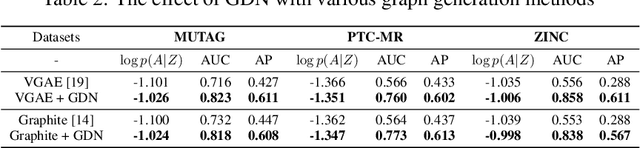
In this paper, we consider an inverse problem in graph learning domain -- ``given the graph representations smoothed by Graph Convolutional Network (GCN), how can we reconstruct the input graph signal?" We propose Graph Deconvolutional Network (GDN) and motivate the design of GDN via a combination of inverse filters in spectral domain and de-noising layers in wavelet domain, as the inverse operation results in a high frequency amplifier and may amplify the noise. We demonstrate the effectiveness of the proposed method on several tasks including graph feature imputation and graph structure generation.