 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization in Deep Neural Networks: Minimax Rates for Gradient Methods
Jun 04, 2026Understanding the generalization performance of over-parameterized neural networks has become a central topic in deep learning theory. While recent advances, particularly works under the Neural Tangent Kernel (NTK) regime, have shed light on the behavior of shallow architectures, the statistical generalization properties of deep neural networks (DNNs), especially in regression tasks, remain far less understood. In this paper, we make significant progress toward closing this gap by providing a comprehensive generalization analysis of DNNs trained using gradient-based methods. First, we establish, for the first time, a crucial connection between the learning dynamics of a DNN with smooth activation functions trained via gradient-based methods and those of kernel methods, showing that gradient-based methods on over-parameterized DNNs can fully inherit the favorable learning dynamics of their kernel counterparts. Building on this connection and the well-established optimality of kernel methods, we derive the first known minimax-optimal rates for the excess population risk of both gradient descent (GD) and stochastic gradient descent (SGD), under the assumption that network width scales polynomially with the sample size. Our results demonstrate that, with sufficient width, DNNs trained by GD or SGD can achieve generalization performance comparable to kernel-based methods.
Optimal Rates for Generalization of Gradient Descent Methods with Deep Neural Networks
Jun 04, 2026Recent progress has been made in understanding the statistical generalization performance of gradient descent methods for overparameterized neural networks within the neural tangent kernel (NTK) regime. However, most of the existing work on regression problems is limited to shallow network architectures, leaving a notable gap in the theory of deep neural networks. This paper addresses this gap by presenting a comprehensive generalization analysis for deep ReLU networks trained using gradient descent (GD) and stochastic gradient descent (SGD). Specifically, we establish the first known minimax-optimal rates of excess population risk for both GD and SGD with deep ReLU networks, under the assumption that the network width scales polynomially with respect to the network depth and training sample size. Our results demonstrate that with sufficient width, gradient descent methods for deep ReLU networks can achieve optimal generalization rates on par with kernel methods.
Population Risk Bounds for Kolmogorov-Arnold Networks Trained by DP-SGD with Correlated Noise
May 12, 2026We establish the first population risk bounds for Kolmogorov-Arnold Networks (KANs) trained by mini-batch SGD with gradient clipping, covering non-private SGD as well as differentially private SGD (DP-SGD) with Gaussian perturbations that interpolate between independent and temporally correlated noise. This setting is substantially closer to practice than prior KAN theory along two axes: training is by mini-batch SGD, the standard recipe for modern networks, rather than full-batch gradient descent (GD); and correlated-noise mechanisms have empirically shown a more favorable privacy-utility tradeoff than independent-noise mechanisms. Our results cover the corresponding full-batch GD and independent-noise DP-GD results for KANs by Wang et al. (2026), while yielding sharper fixed-second-layer specializations. The technical core is a new analysis route for correlated-noise DP training in the non-convex regime. Temporal dependence breaks the conditional-centering structure underlying standard one-step SGD arguments, and the projection step obstructs the exact cancellation structure of correlated perturbations. We address these difficulties through an auxiliary unprojected dynamics, a shifted iterate that absorbs the current noise perturbation, and a high-probability bootstrap certifying projection inactivity. Combining this optimization analysis with a stability-based generalization argument yields the stated population risk bounds. To the best of our knowledge, this is the first optimization and population risk analysis of a correlated-noise mechanism for DP training beyond convex learning, in particular for neural networks.
Optimization, Generalization and Differential Privacy Bounds for Gradient Descent on Kolmogorov-Arnold Networks
Jan 29, 2026Kolmogorov--Arnold Networks (KANs) have recently emerged as a structured alternative to standard MLPs, yet a principled theory for their training dynamics, generalization, and privacy properties remains limited. In this paper, we analyze gradient descent (GD) for training two-layer KANs and derive general bounds that characterize their training dynamics, generalization, and utility under differential privacy (DP). As a concrete instantiation, we specialize our analysis to logistic loss under an NTK-separable assumption, where we show that polylogarithmic network width suffices for GD to achieve an optimization rate of order $1/T$ and a generalization rate of order $1/n$, with $T$ denoting the number of GD iterations and $n$ the sample size. In the private setting, we characterize the noise required for $(ε,δ)$-DP and obtain a utility bound of order $\sqrt{d}/(nε)$ (with $d$ the input dimension), matching the classical lower bound for general convex Lipschitz problems. Our results imply that polylogarithmic width is not only sufficient but also necessary under differential privacy, revealing a qualitative gap between non-private (sufficiency only) and private (necessity also emerges) training regimes. Experiments further illustrate how these theoretical insights can guide practical choices, including network width selection and early stopping.
Generalization analysis with deep ReLU networks for metric and similarity learning
May 10, 2024While considerable theoretical progress has been devoted to the study of metric and similarity learning, the generalization mystery is still missing. In this paper, we study the generalization performance of metric and similarity learning by leveraging the specific structure of the true metric (the target function). Specifically, by deriving the explicit form of the true metric for metric and similarity learning with the hinge loss, we construct a structured deep ReLU neural network as an approximation of the true metric, whose approximation ability relies on the network complexity. Here, the network complexity corresponds to the depth, the number of nonzero weights and the computation units of the network. Consider the hypothesis space which consists of the structured deep ReLU networks, we develop the excess generalization error bounds for a metric and similarity learning problem by estimating the approximation error and the estimation error carefully. An optimal excess risk rate is derived by choosing the proper capacity of the constructed hypothesis space. To the best of our knowledge, this is the first-ever-known generalization analysis providing the excess generalization error for metric and similarity learning. In addition, we investigate the properties of the true metric of metric and similarity learning with general losses.
Generalization Guarantees of Gradient Descent for Multi-Layer Neural Networks
May 26, 2023
Recently, significant progress has been made in understanding the generalization of neural networks (NNs) trained by gradient descent (GD) using the algorithmic stability approach. However, most of the existing research has focused on one-hidden-layer NNs and has not addressed the impact of different network scaling parameters. In this paper, we greatly extend the previous work \cite{lei2022stability,richards2021stability} by conducting a comprehensive stability and generalization analysis of GD for multi-layer NNs. For two-layer NNs, our results are established under general network scaling parameters, relaxing previous conditions. In the case of three-layer NNs, our technical contribution lies in demonstrating its nearly co-coercive property by utilizing a novel induction strategy that thoroughly explores the effects of over-parameterization. As a direct application of our general findings, we derive the excess risk rate of $O(1/\sqrt{n})$ for GD algorithms in both two-layer and three-layer NNs. This sheds light on sufficient or necessary conditions for under-parameterized and over-parameterized NNs trained by GD to attain the desired risk rate of $O(1/\sqrt{n})$. Moreover, we demonstrate that as the scaling parameter increases or the network complexity decreases, less over-parameterization is required for GD to achieve the desired error rates. Additionally, under a low-noise condition, we obtain a fast risk rate of $O(1/n)$ for GD in both two-layer and three-layer NNs.
Stability and Generalization for Markov Chain Stochastic Gradient Methods
Sep 16, 2022Recently there is a large amount of work devoted to the study of Markov chain stochastic gradient methods (MC-SGMs) which mainly focus on their convergence analysis for solving minimization problems. In this paper, we provide a comprehensive generalization analysis of MC-SGMs for both minimization and minimax problems through the lens of algorithmic stability in the framework of statistical learning theory. For empirical risk minimization (ERM) problems, we establish the optimal excess population risk bounds for both smooth and non-smooth cases by introducing on-average argument stability. For minimax problems, we develop a quantitative connection between on-average argument stability and generalization error which extends the existing results for uniform stability \cite{lei2021stability}. We further develop the first nearly optimal convergence rates for convex-concave problems both in expectation and with high probability, which, combined with our stability results, show that the optimal generalization bounds can be attained for both smooth and non-smooth cases. To the best of our knowledge, this is the first generalization analysis of SGMs when the gradients are sampled from a Markov process.
Differentially Private Stochastic Gradient Descent with Low-Noise
Sep 09, 2022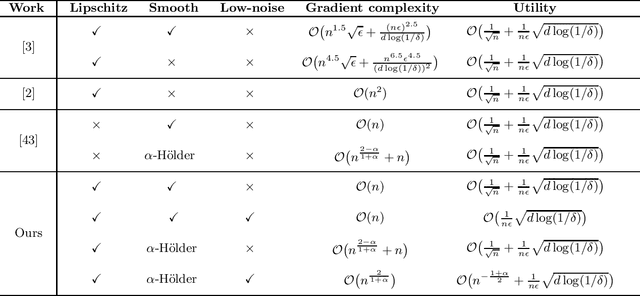

In this paper, by introducing a low-noise condition, we study privacy and utility (generalization) performances of differentially private stochastic gradient descent (SGD) algorithms in a setting of stochastic convex optimization (SCO) for both pointwise and pairwise learning problems. For pointwise learning, we establish sharper excess risk bounds of order $\mathcal{O}\Big( \frac{\sqrt{d\log(1/\delta)}}{n\epsilon} \Big)$ and $\mathcal{O}\Big( {n^{- \frac{1+\alpha}{2}}}+\frac{\sqrt{d\log(1/\delta)}}{n\epsilon}\Big)$ for the $(\epsilon,\delta)$-differentially private SGD algorithm for strongly smooth and $\alpha$-H\"older smooth losses, respectively, where $n$ is the sample size and $d$ is the dimensionality. For pairwise learning, inspired by \cite{lei2020sharper,lei2021generalization}, we propose a simple private SGD algorithm based on gradient perturbation which satisfies $(\epsilon,\delta)$-differential privacy, and develop novel utility bounds for the proposed algorithm. In particular, we prove that our algorithm can achieve excess risk rates $\mathcal{O}\Big(\frac{1}{\sqrt{n}}+\frac{\sqrt{d\log(1/\delta)}}{n\epsilon}\Big)$ with gradient complexity $\mathcal{O}(n)$ and $\mathcal{O}\big(n^{\frac{2-\alpha}{1+\alpha}}+n\big)$ for strongly smooth and $\alpha$-H\"older smooth losses, respectively. Further, faster learning rates are established in a low-noise setting for both smooth and non-smooth losses. To the best of our knowledge, this is the first utility analysis which provides excess population bounds better than $\mathcal{O}\Big(\frac{1}{\sqrt{n}}+\frac{\sqrt{d\log(1/\delta)}}{n\epsilon}\Big)$ for privacy-preserving pairwise learning.
Simple Stochastic and Online Gradient Descent Algorithms for Pairwise Learning
Nov 23, 2021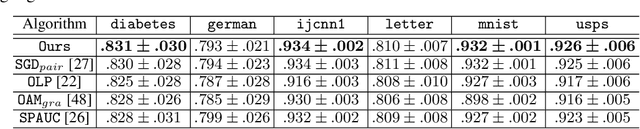
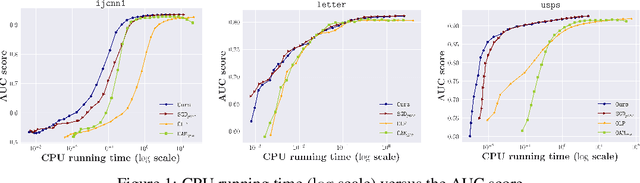
Pairwise learning refers to learning tasks where the loss function depends on a pair of instances. It instantiates many important machine learning tasks such as bipartite ranking and metric learning. A popular approach to handle streaming data in pairwise learning is an online gradient descent (OGD) algorithm, where one needs to pair the current instance with a buffering set of previous instances with a sufficiently large size and therefore suffers from a scalability issue. In this paper, we propose simple stochastic and online gradient descent methods for pairwise learning. A notable difference from the existing studies is that we only pair the current instance with the previous one in building a gradient direction, which is efficient in both the storage and computational complexity. We develop novel stability results, optimization, and generalization error bounds for both convex and nonconvex as well as both smooth and nonsmooth problems. We introduce novel techniques to decouple the dependency of models and the previous instance in both the optimization and generalization analysis. Our study resolves an open question on developing meaningful generalization bounds for OGD using a buffering set with a very small fixed size. We also extend our algorithms and stability analysis to develop differentially private SGD algorithms for pairwise learning which significantly improves the existing results.
Stability and Generalization for Randomized Coordinate Descent
Aug 17, 2021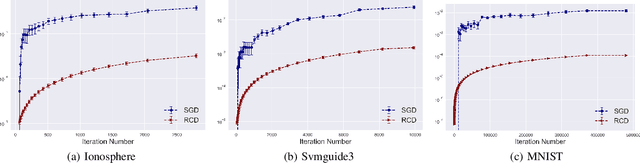
Randomized coordinate descent (RCD) is a popular optimization algorithm with wide applications in solving various machine learning problems, which motivates a lot of theoretical analysis on its convergence behavior. As a comparison, there is no work studying how the models trained by RCD would generalize to test examples. In this paper, we initialize the generalization analysis of RCD by leveraging the powerful tool of algorithmic stability. We establish argument stability bounds of RCD for both convex and strongly convex objectives, from which we develop optimal generalization bounds by showing how to early-stop the algorithm to tradeoff the estimation and optimization. Our analysis shows that RCD enjoys better stability as compared to stochastic gradient descent.