 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLGait: A Global-Local Temporal Receptive Field Network for Gait Recognition in the Wild
Aug 13, 2024



Gait recognition has attracted increasing attention from academia and industry as a human recognition technology from a distance in non-intrusive ways without requiring cooperation. Although advanced methods have achieved impressive success in lab scenarios, most of them perform poorly in the wild. Recently, some Convolution Neural Networks (ConvNets) based methods have been proposed to address the issue of gait recognition in the wild. However, the temporal receptive field obtained by convolution operations is limited for long gait sequences. If directly replacing convolution blocks with visual transformer blocks, the model may not enhance a local temporal receptive field, which is important for covering a complete gait cycle. To address this issue, we design a Global-Local Temporal Receptive Field Network (GLGait). GLGait employs a Global-Local Temporal Module (GLTM) to establish a global-local temporal receptive field, which mainly consists of a Pseudo Global Temporal Self-Attention (PGTA) and a temporal convolution operation. Specifically, PGTA is used to obtain a pseudo global temporal receptive field with less memory and computation complexity compared with a multi-head self-attention (MHSA). The temporal convolution operation is used to enhance the local temporal receptive field. Besides, it can also aggregate pseudo global temporal receptive field to a true holistic temporal receptive field. Furthermore, we also propose a Center-Augmented Triplet Loss (CTL) in GLGait to reduce the intra-class distance and expand the positive samples in the training stage. Extensive experiments show that our method obtains state-of-the-art results on in-the-wild datasets, $i.e.$, Gait3D and GREW. The code is available at https://github.com/bgdpgz/GLGait.
AdaLog: Post-Training Quantization for Vision Transformers with Adaptive Logarithm Quantizer
Jul 17, 2024



Vision Transformer (ViT) has become one of the most prevailing fundamental backbone networks in the computer vision community. Despite the high accuracy, deploying it in real applications raises critical challenges including the high computational cost and inference latency. Recently, the post-training quantization (PTQ) technique has emerged as a promising way to enhance ViT's efficiency. Nevertheless, existing PTQ approaches for ViT suffer from the inflexible quantization on the post-Softmax and post-GELU activations that obey the power-law-like distributions. To address these issues, we propose a novel non-uniform quantizer, dubbed the Adaptive Logarithm AdaLog (AdaLog) quantizer. It optimizes the logarithmic base to accommodate the power-law-like distribution of activations, while simultaneously allowing for hardware-friendly quantization and de-quantization. By employing the bias reparameterization, the AdaLog quantizer is applicable to both the post-Softmax and post-GELU activations. Moreover, we develop an efficient Fast Progressive Combining Search (FPCS) strategy to determine the optimal logarithm base for AdaLog, as well as the scaling factors and zero points for the uniform quantizers. Extensive experimental results on public benchmarks demonstrate the effectiveness of our approach for various ViT-based architectures and vision tasks including classification, object detection, and instance segmentation. Code is available at https://github.com/GoatWu/AdaLog.
FSD-BEV: Foreground Self-Distillation for Multi-view 3D Object Detection
Jul 14, 2024



Although multi-view 3D object detection based on the Bird's-Eye-View (BEV) paradigm has garnered widespread attention as an economical and deployment-friendly perception solution for autonomous driving, there is still a performance gap compared to LiDAR-based methods. In recent years, several cross-modal distillation methods have been proposed to transfer beneficial information from teacher models to student models, with the aim of enhancing performance. However, these methods face challenges due to discrepancies in feature distribution originating from different data modalities and network structures, making knowledge transfer exceptionally challenging. In this paper, we propose a Foreground Self-Distillation (FSD) scheme that effectively avoids the issue of distribution discrepancies, maintaining remarkable distillation effects without the need for pre-trained teacher models or cumbersome distillation strategies. Additionally, we design two Point Cloud Intensification (PCI) strategies to compensate for the sparsity of point clouds by frame combination and pseudo point assignment. Finally, we develop a Multi-Scale Foreground Enhancement (MSFE) module to extract and fuse multi-scale foreground features by predicted elliptical Gaussian heatmap, further improving the model's performance. We integrate all the above innovations into a unified framework named FSD-BEV. Extensive experiments on the nuScenes dataset exhibit that FSD-BEV achieves state-of-the-art performance, highlighting its effectiveness. The code and models are available at: https://github.com/CocoBoom/fsd-bev.
MutDet: Mutually Optimizing Pre-training for Remote Sensing Object Detection
Jul 13, 2024



Detection pre-training methods for the DETR series detector have been extensively studied in natural scenes, e.g., DETReg. However, the detection pre-training remains unexplored in remote sensing scenes. In existing pre-training methods, alignment between object embeddings extracted from a pre-trained backbone and detector features is significant. However, due to differences in feature extraction methods, a pronounced feature discrepancy still exists and hinders the pre-training performance. The remote sensing images with complex environments and more densely distributed objects exacerbate the discrepancy. In this work, we propose a novel Mutually optimizing pre-training framework for remote sensing object Detection, dubbed as MutDet. In MutDet, we propose a systemic solution against this challenge. Firstly, we propose a mutual enhancement module, which fuses the object embeddings and detector features bidirectionally in the last encoder layer, enhancing their information interaction.Secondly, contrastive alignment loss is employed to guide this alignment process softly and simultaneously enhances detector features' discriminativity. Finally, we design an auxiliary siamese head to mitigate the task gap arising from the introduction of enhancement module. Comprehensive experiments on various settings show new state-of-the-art transfer performance. The improvement is particularly pronounced when data quantity is limited. When using 10% of the DIOR-R data, MutDet improves DetReg by 6.1% in AP50. Codes and models are available at: https://github.com/floatingstarZ/MutDet.
Semantic Enhanced Few-shot Object Detection
Jun 19, 2024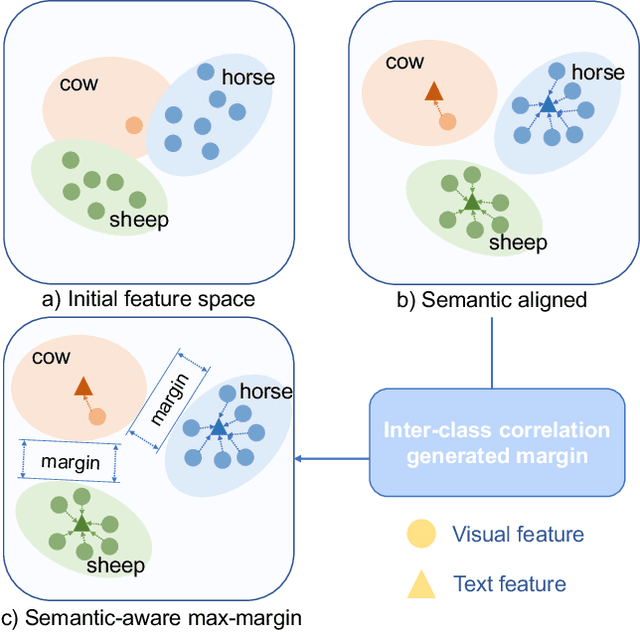
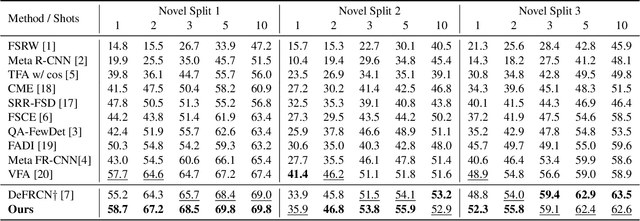
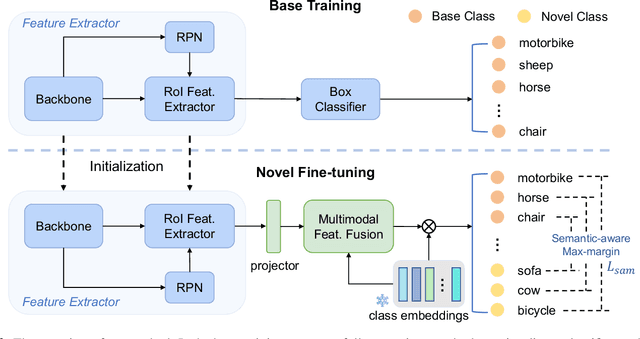
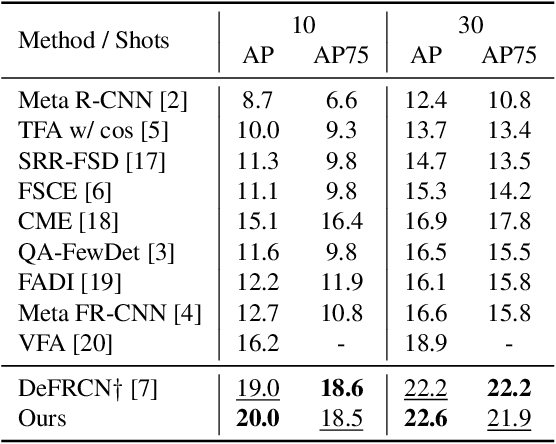
Few-shot object detection~(FSOD), which aims to detect novel objects with limited annotated instances, has made significant progress in recent years. However, existing methods still suffer from biased representations, especially for novel classes in extremely low-shot scenarios. During fine-tuning, a novel class may exploit knowledge from similar base classes to construct its own feature distribution, leading to classification confusion and performance degradation. To address these challenges, we propose a fine-tuning based FSOD framework that utilizes semantic embeddings for better detection. In our proposed method, we align the visual features with class name embeddings and replace the linear classifier with our semantic similarity classifier. Our method trains each region proposal to converge to the corresponding class embedding. Furthermore, we introduce a multimodal feature fusion to augment the vision-language communication, enabling a novel class to draw support explicitly from well-trained similar base classes. To prevent class confusion, we propose a semantic-aware max-margin loss, which adaptively applies a margin beyond similar classes. As a result, our method allows each novel class to construct a compact feature space without being confused with similar base classes. Extensive experiments on Pascal VOC and MS COCO demonstrate the superiority of our method.
Leveraging Predicate and Triplet Learning for Scene Graph Generation
Jun 04, 2024



Scene Graph Generation (SGG) aims to identify entities and predict the relationship triplets \textit{\textless subject, predicate, object\textgreater } in visual scenes. Given the prevalence of large visual variations of subject-object pairs even in the same predicate, it can be quite challenging to model and refine predicate representations directly across such pairs, which is however a common strategy adopted by most existing SGG methods. We observe that visual variations within the identical triplet are relatively small and certain relation cues are shared in the same type of triplet, which can potentially facilitate the relation learning in SGG. Moreover, for the long-tail problem widely studied in SGG task, it is also crucial to deal with the limited types and quantity of triplets in tail predicates. Accordingly, in this paper, we propose a Dual-granularity Relation Modeling (DRM) network to leverage fine-grained triplet cues besides the coarse-grained predicate ones. DRM utilizes contexts and semantics of predicate and triplet with Dual-granularity Constraints, generating compact and balanced representations from two perspectives to facilitate relation recognition. Furthermore, a Dual-granularity Knowledge Transfer (DKT) strategy is introduced to transfer variation from head predicates/triplets to tail ones, aiming to enrich the pattern diversity of tail classes to alleviate the long-tail problem. Extensive experiments demonstrate the effectiveness of our method, which establishes new state-of-the-art performance on Visual Genome, Open Image, and GQA datasets. Our code is available at \url{https://github.com/jkli1998/DRM}
4Diffusion: Multi-view Video Diffusion Model for 4D Generation
May 31, 2024



Current 4D generation methods have achieved noteworthy efficacy with the aid of advanced diffusion generative models. However, these methods lack multi-view spatial-temporal modeling and encounter challenges in integrating diverse prior knowledge from multiple diffusion models, resulting in inconsistent temporal appearance and flickers. In this paper, we propose a novel 4D generation pipeline, namely 4Diffusion aimed at generating spatial-temporally consistent 4D content from a monocular video. We first design a unified diffusion model tailored for multi-view video generation by incorporating a learnable motion module into a frozen 3D-aware diffusion model to capture multi-view spatial-temporal correlations. After training on a curated dataset, our diffusion model acquires reasonable temporal consistency and inherently preserves the generalizability and spatial consistency of the 3D-aware diffusion model. Subsequently, we propose 4D-aware Score Distillation Sampling loss, which is based on our multi-view video diffusion model, to optimize 4D representation parameterized by dynamic NeRF. This aims to eliminate discrepancies arising from multiple diffusion models, allowing for generating spatial-temporally consistent 4D content. Moreover, we devise an anchor loss to enhance the appearance details and facilitate the learning of dynamic NeRF. Extensive qualitative and quantitative experiments demonstrate that our method achieves superior performance compared to previous methods.
3D Face Modeling via Weakly-supervised Disentanglement Network joint Identity-consistency Prior
Apr 25, 2024



Generative 3D face models featuring disentangled controlling factors hold immense potential for diverse applications in computer vision and computer graphics. However, previous 3D face modeling methods face a challenge as they demand specific labels to effectively disentangle these factors. This becomes particularly problematic when integrating multiple 3D face datasets to improve the generalization of the model. Addressing this issue, this paper introduces a Weakly-Supervised Disentanglement Framework, denoted as WSDF, to facilitate the training of controllable 3D face models without an overly stringent labeling requirement. Adhering to the paradigm of Variational Autoencoders (VAEs), the proposed model achieves disentanglement of identity and expression controlling factors through a two-branch encoder equipped with dedicated identity-consistency prior. It then faithfully re-entangles these factors via a tensor-based combination mechanism. Notably, the introduction of the Neutral Bank allows precise acquisition of subject-specific information using only identity labels, thereby averting degeneration due to insufficient supervision. Additionally, the framework incorporates a label-free second-order loss function for the expression factor to regulate deformation space and eliminate extraneous information, resulting in enhanced disentanglement. Extensive experiments have been conducted to substantiate the superior performance of WSDF. Our code is available at https://github.com/liguohao96/WSDF.
LSP Framework: A Compensatory Model for Defeating Trigger Reverse Engineering via Label Smoothing Poisoning
Apr 19, 2024Deep neural networks are vulnerable to backdoor attacks. Among the existing backdoor defense methods, trigger reverse engineering based approaches, which reconstruct the backdoor triggers via optimizations, are the most versatile and effective ones compared to other types of methods. In this paper, we summarize and construct a generic paradigm for the typical trigger reverse engineering process. Based on this paradigm, we propose a new perspective to defeat trigger reverse engineering by manipulating the classification confidence of backdoor samples. To determine the specific modifications of classification confidence, we propose a compensatory model to compute the lower bound of the modification. With proper modifications, the backdoor attack can easily bypass the trigger reverse engineering based methods. To achieve this objective, we propose a Label Smoothing Poisoning (LSP) framework, which leverages label smoothing to specifically manipulate the classification confidences of backdoor samples. Extensive experiments demonstrate that the proposed work can defeat the state-of-the-art trigger reverse engineering based methods, and possess good compatibility with a variety of existing backdoor attacks.
AED-PADA:Improving Generalizability of Adversarial Example Detection via Principal Adversarial Domain Adaptation
Apr 19, 2024Adversarial example detection, which can be conveniently applied in many scenarios, is important in the area of adversarial defense. Unfortunately, existing detection methods suffer from poor generalization performance, because their training process usually relies on the examples generated from a single known adversarial attack and there exists a large discrepancy between the training and unseen testing adversarial examples. To address this issue, we propose a novel method, named Adversarial Example Detection via Principal Adversarial Domain Adaptation (AED-PADA). Specifically, our approach identifies the Principal Adversarial Domains (PADs), i.e., a combination of features of the adversarial examples from different attacks, which possesses large coverage of the entire adversarial feature space. Then, we pioneer to exploit multi-source domain adaptation in adversarial example detection with PADs as source domains. Experiments demonstrate the superior generalization ability of our proposed AED-PADA. Note that this superiority is particularly achieved in challenging scenarios characterized by employing the minimal magnitude constraint for the perturbations.