 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel LineUpper: Supporting Interactive Model Comparison at Multiple Levels for AutoML
Apr 09, 2021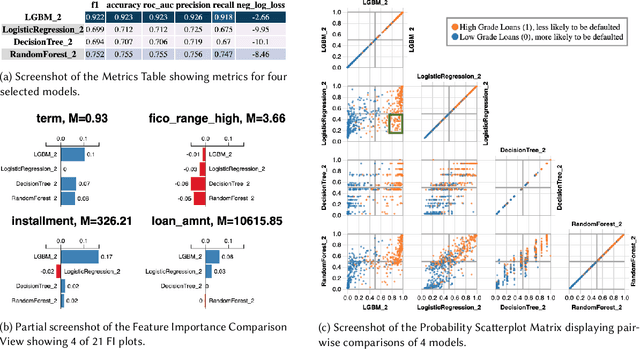
Automated Machine Learning (AutoML) is a rapidly growing set of technologies that automate the model development pipeline by searching model space and generating candidate models. A critical, final step of AutoML is human selection of a final model from dozens of candidates. In current AutoML systems, selection is supported only by performance metrics. Prior work has shown that in practice, people evaluate ML models based on additional criteria, such as the way a model makes predictions. Comparison may happen at multiple levels, from types of errors, to feature importance, to how the model makes predictions of specific instances. We developed \tool{} to support interactive model comparison for AutoML by integrating multiple Explainable AI (XAI) and visualization techniques. We conducted a user study in which we both evaluated the system and used it as a technology probe to understand how users perform model comparison in an AutoML system. We discuss design implications for utilizing XAI techniques for model comparison and supporting the unique needs of data scientists in comparing AutoML models.
Enhancing the Generalization Performance and Speed Up Training for DRL-based Mapless Navigation
Mar 22, 2021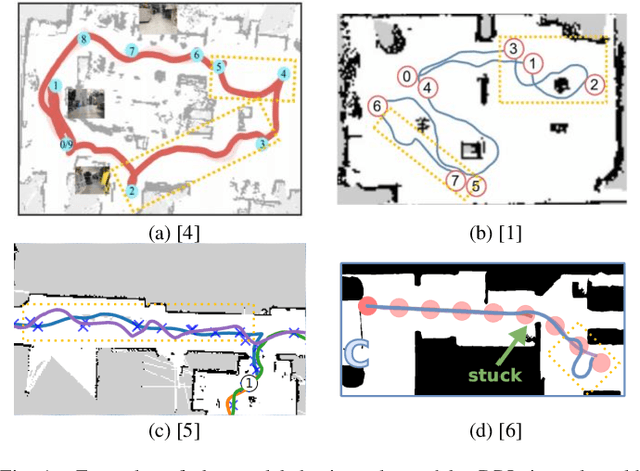
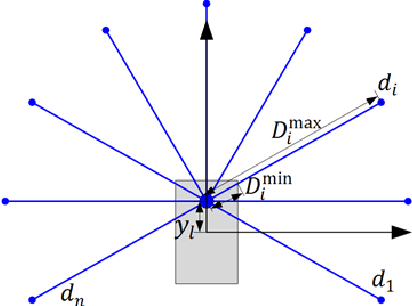
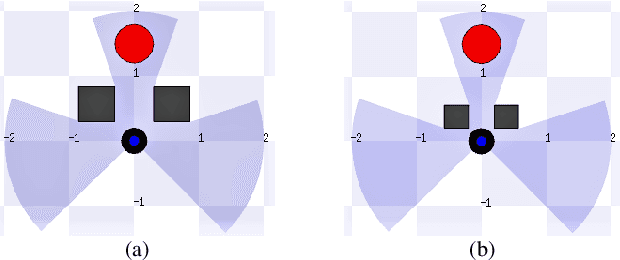
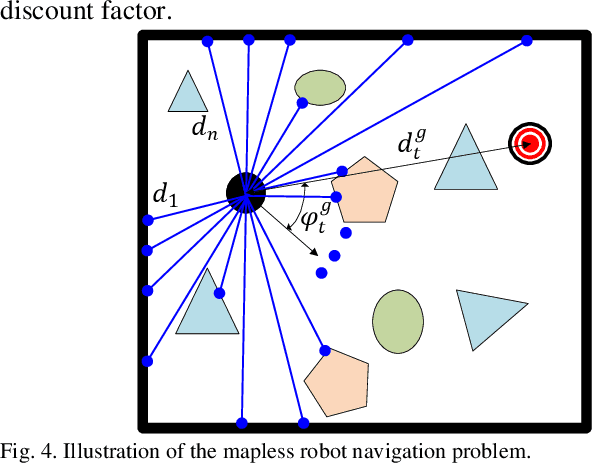
Training an agent to navigate with DRL is data-hungry, which requires millions of training steps. Besides, the DRL agents performing well in training scenarios are found to perform poorly in some unseen real-world scenarios. In this paper, we discuss why the DRL agent fails in such unseen scenarios and find the representation of LiDAR readings is the key factor behind the agent's performance degradation. Moreover, we propose an easy, but efficient input pre-processing (IP) approach to accelerate training and enhance the performance of the DRL agent in such scenarios. The proposed IP functions can highlight the important short-distance values of laser scans and compress the range of less-important long-distance values. Extensive comparative experiments are carried out, and the experimental results demonstrate the high performance of the proposed IP approaches.
How Much Automation Does a Data Scientist Want?
Jan 07, 2021

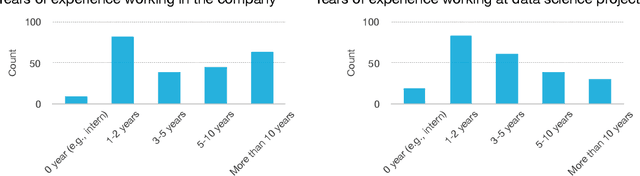
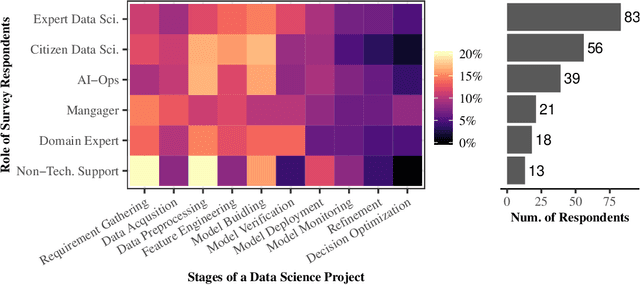
Data science and machine learning (DS/ML) are at the heart of the recent advancements of many Artificial Intelligence (AI) applications. There is an active research thread in AI, \autoai, that aims to develop systems for automating end-to-end the DS/ML Lifecycle. However, do DS and ML workers really want to automate their DS/ML workflow? To answer this question, we first synthesize a human-centered AutoML framework with 6 User Role/Personas, 10 Stages and 43 Sub-Tasks, 5 Levels of Automation, and 5 Types of Explanation, through reviewing research literature and marketing reports. Secondly, we use the framework to guide the design of an online survey study with 217 DS/ML workers who had varying degrees of experience, and different user roles "matching" to our 6 roles/personas. We found that different user personas participated in distinct stages of the lifecycle -- but not all stages. Their desired levels of automation and types of explanation for AutoML also varied significantly depending on the DS/ML stage and the user persona. Based on the survey results, we argue there is no rationale from user needs for complete automation of the end-to-end DS/ML lifecycle. We propose new next steps for user-controlled DS/ML automation.
Uncertainty as a Form of Transparency: Measuring, Communicating, and Using Uncertainty
Nov 15, 2020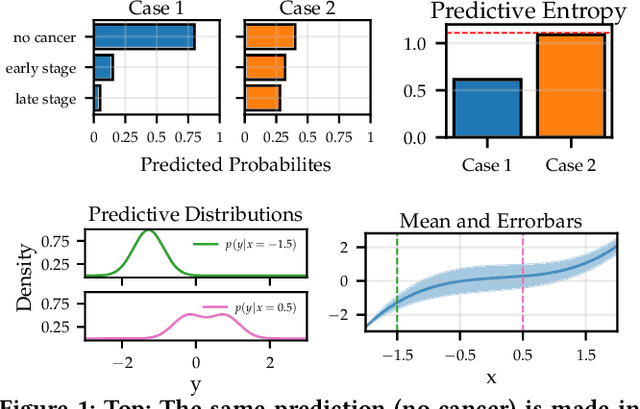

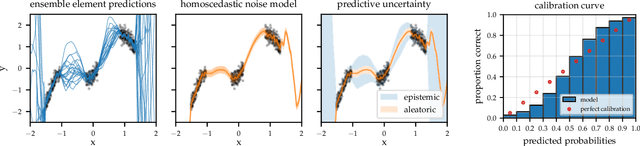
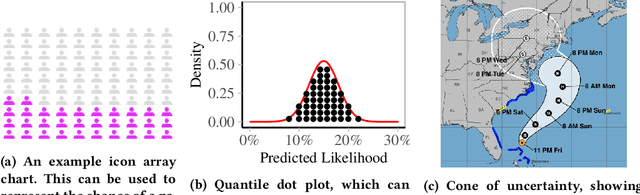
Transparency of algorithmic systems entails exposing system properties to various stakeholders for purposes that include understanding, improving, and/or contesting predictions. The machine learning (ML) community has mostly considered explainability as a proxy for transparency. With this work, we seek to encourage researchers to study uncertainty as a form of transparency and practitioners to communicate uncertainty estimates to stakeholders. First, we discuss methods for assessing uncertainty. Then, we describe the utility of uncertainty for mitigating model unfairness, augmenting decision-making, and building trustworthy systems. We also review methods for displaying uncertainty to stakeholders and discuss how to collect information required for incorporating uncertainty into existing ML pipelines. Our contribution is an interdisciplinary review to inform how to measure, communicate, and use uncertainty as a form of transparency.
Learn to Navigate Maplessly with Varied LiDAR Configurations: A Support Point Based Approach
Oct 20, 2020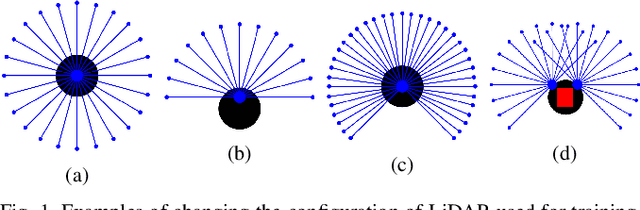
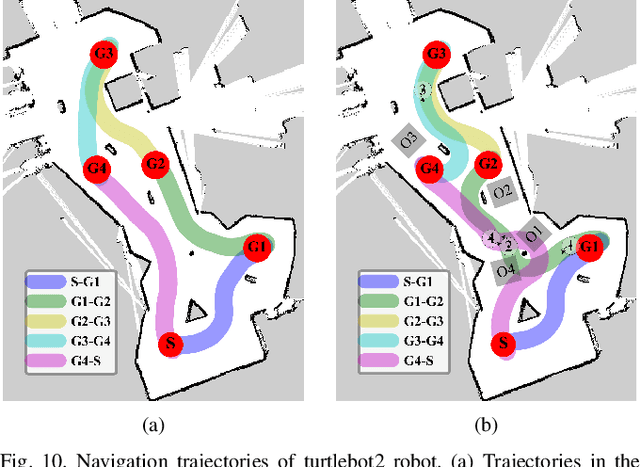
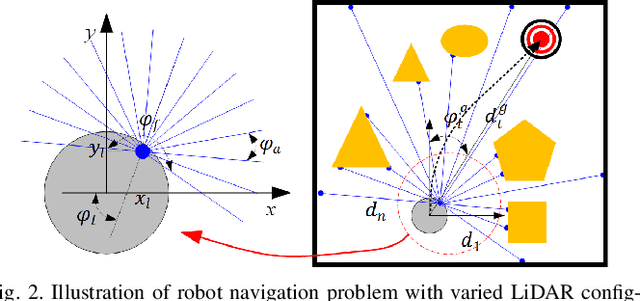
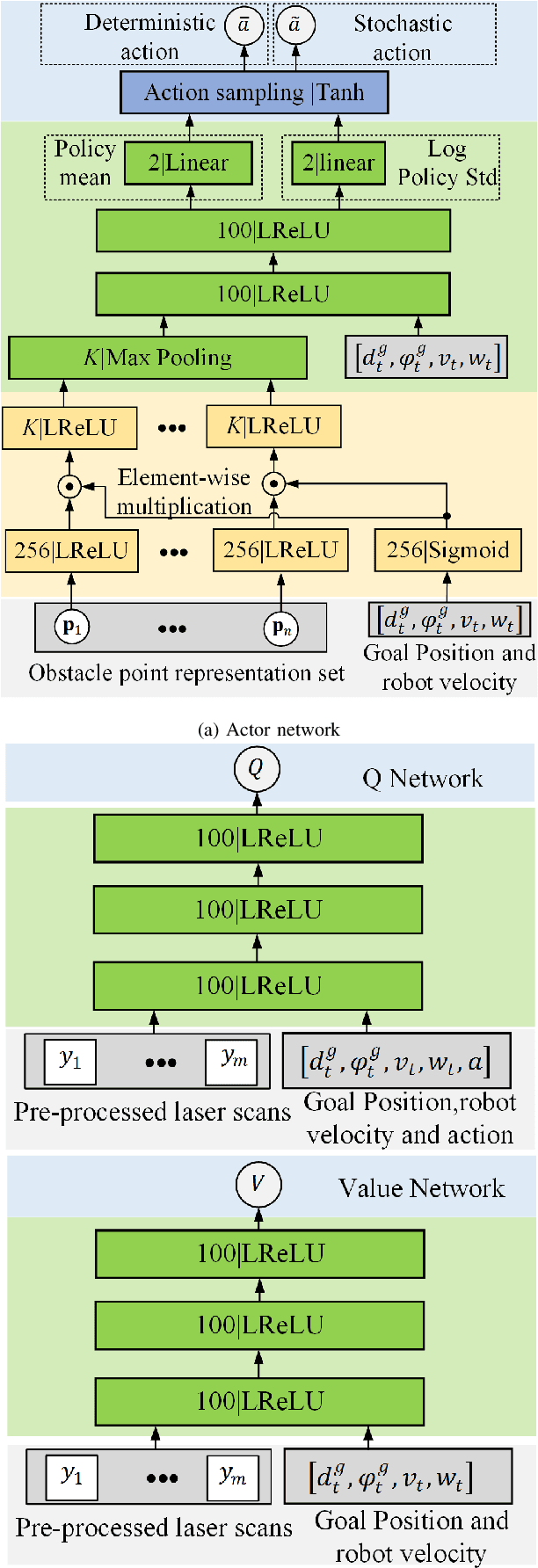
Deep reinforcement learning (DRL) demonstrates great potential in mapless navigation domain. However, such a navigation model is normally restricted to a fixed configuration of the range sensor because its input format is fixed. In this paper, we propose a DRL model that can address range data obtained from different range sensors with different installation positions. Our model first extracts the goal-directed features from each obstacle point. Subsequently, it chooses global obstacle features from all point-feature candidates and uses these features for the final decision. As only a few points are used to support the final decision, we refer to these points as support points and our approach as support-point based navigation (SPN). Our model can handle data from different LiDAR setups and demonstrates good performance in simulation and real-world experiments. It can also be used to guide the installation of range sensors to enhance robot navigation performance.
Deciding Fast and Slow: The Role of Cognitive Biases in AI-assisted Decision-making
Oct 15, 2020
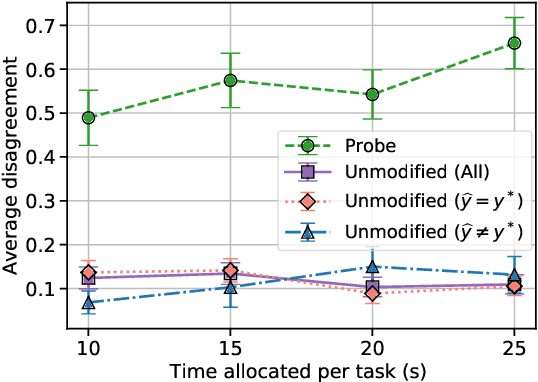
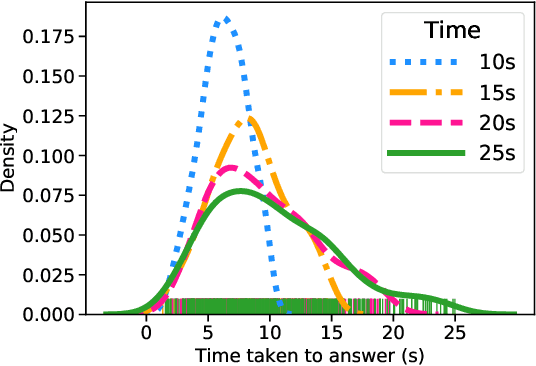
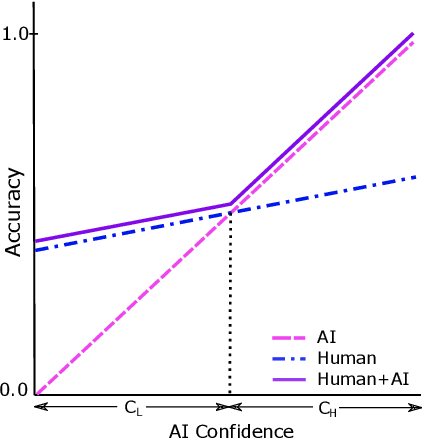
Several strands of research have aimed to bridge the gap between artificial intelligence (AI) and human decision-makers in AI-assisted decision-making, where humans are the consumers of AI model predictions and the ultimate decision-makers in high-stakes applications. However, people's perception and understanding is often distorted by their cognitive biases, like confirmation bias, anchoring bias, availability bias, to name a few. In this work, we use knowledge from the field of cognitive science to account for cognitive biases in the human-AI collaborative decision-making system and mitigate their negative effects. To this end, we mathematically model cognitive biases and provide a general framework through which researchers and practitioners can understand the interplay between cognitive biases and human-AI accuracy. We then focus on anchoring bias, a bias commonly witnessed in human-AI partnerships. We devise a cognitive science-driven, time-based approach to de-anchoring. A user experiment shows the effectiveness of this approach in human-AI collaborative decision-making. Using the results from this first experiment, we design a time allocation strategy for a resource constrained setting so as to achieve optimal human-AI collaboration under some assumptions. A second user study shows that our time allocation strategy can effectively debias the human when the AI model has low confidence and is incorrect.
Active Learning++: Incorporating Annotator's Rationale using Local Model Explanation
Sep 06, 2020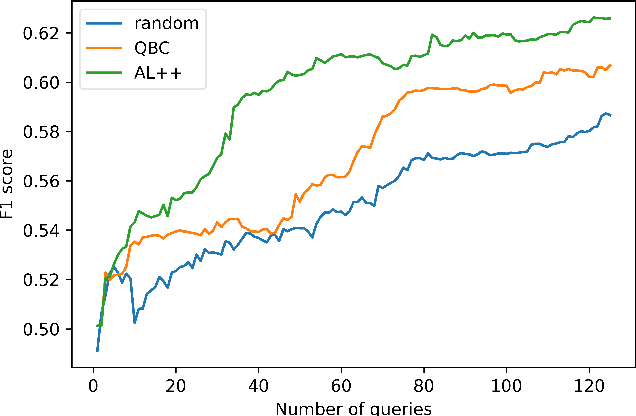
We propose a new active learning (AL) framework, Active Learning++, which can utilize an annotator's labels as well as its rationale. Annotators can provide their rationale for choosing a label by ranking input features based on their importance for a given query. To incorporate this additional input, we modified the disagreement measure for a bagging-based Query by Committee (QBC) sampling strategy. Instead of weighing all committee models equally to select the next instance, we assign higher weight to the committee model with higher agreement with the annotator's ranking. Specifically, we generated a feature importance-based local explanation for each committee model. The similarity score between feature rankings provided by the annotator and the local model explanation is used to assign a weight to each corresponding committee model. This approach is applicable to any kind of ML model using model-agnostic techniques to generate local explanation such as LIME. With a simulation study, we show that our framework significantly outperforms a QBC based vanilla AL framework.
Measuring Social Biases of Crowd Workers using Counterfactual Queries
Apr 04, 2020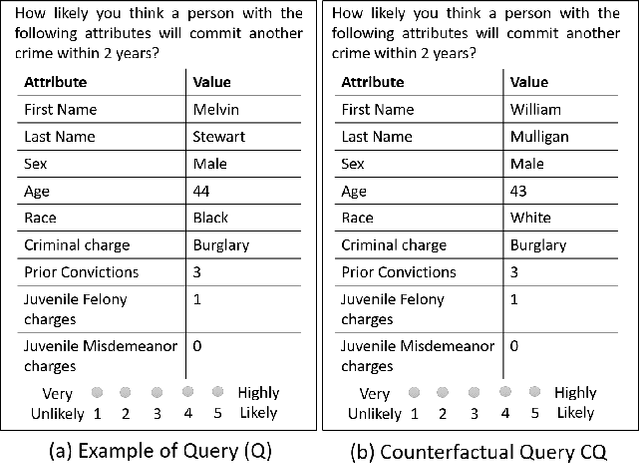
Social biases based on gender, race, etc. have been shown to pollute machine learning (ML) pipeline predominantly via biased training datasets. Crowdsourcing, a popular cost-effective measure to gather labeled training datasets, is not immune to the inherent social biases of crowd workers. To ensure such social biases aren't passed onto the curated datasets, it's important to know how biased each crowd worker is. In this work, we propose a new method based on counterfactual fairness to quantify the degree of inherent social bias in each crowd worker. This extra information can be leveraged together with individual worker responses to curate a less biased dataset.
Model Agnostic Multilevel Explanations
Mar 12, 2020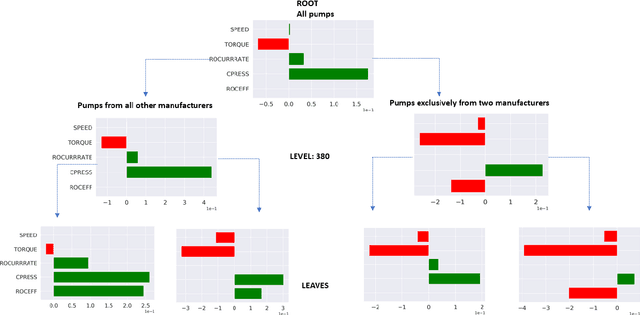
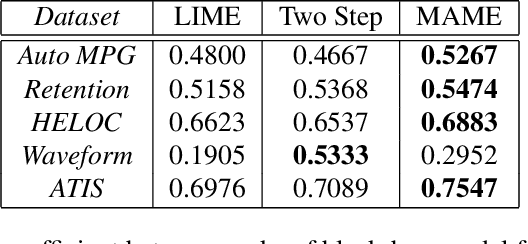
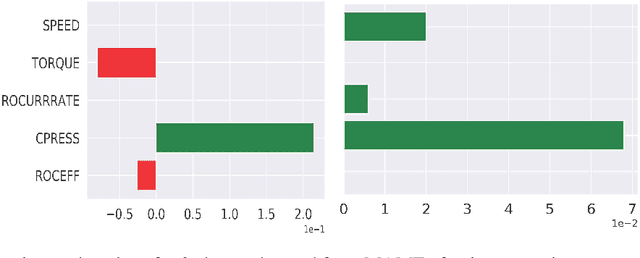
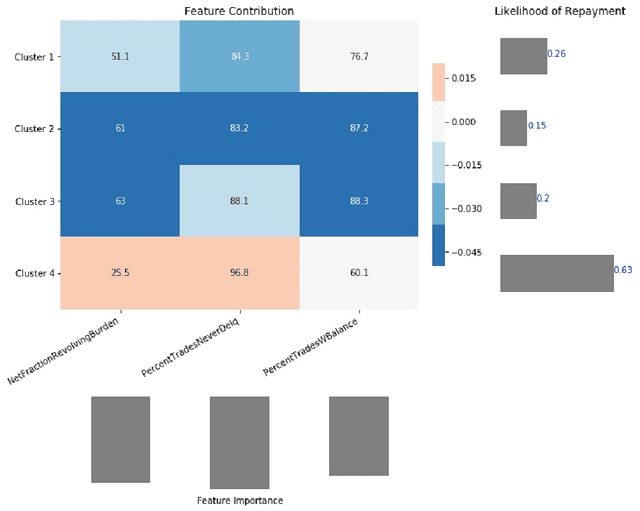
In recent years, post-hoc local instance-level and global dataset-level explainability of black-box models has received a lot of attention. Much less attention has been given to obtaining insights at intermediate or group levels, which is a need outlined in recent works that study the challenges in realizing the guidelines in the General Data Protection Regulation (GDPR). In this paper, we propose a meta-method that, given a typical local explainability method, can build a multilevel explanation tree. The leaves of this tree correspond to the local explanations, the root corresponds to the global explanation, and intermediate levels correspond to explanations for groups of data points that it automatically clusters. The method can also leverage side information, where users can specify points for which they may want the explanations to be similar. We argue that such a multilevel structure can also be an effective form of communication, where one could obtain few explanations that characterize the entire dataset by considering an appropriate level in our explanation tree. Explanations for novel test points can be cost-efficiently obtained by associating them with the closest training points. When the local explainability technique is generalized additive (viz. LIME, GAMs), we develop a fast approximate algorithm for building the multilevel tree and study its convergence behavior. We validate the effectiveness of the proposed technique based on two human studies -- one with experts and the other with non-expert users -- on real world datasets, and show that we produce high fidelity sparse explanations on several other public datasets.
Map-less Navigation: A Single DRL-based Controller for Robots with Varied Dimensions
Feb 15, 2020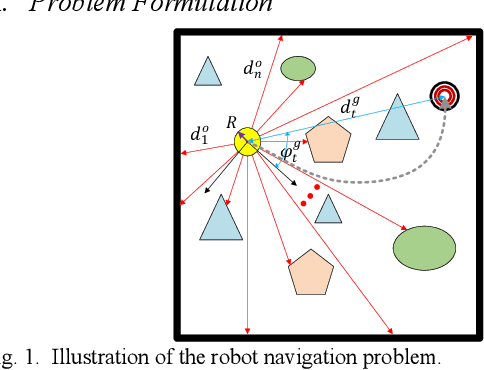
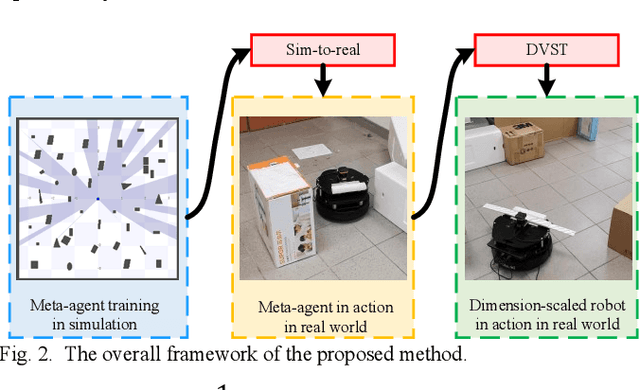

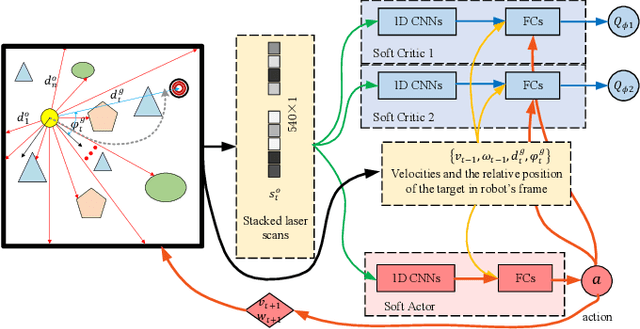
Deep reinforcement learning (DRL) has shown great potential in training control agents for map-less robot navigation. However, the trained agents are generally dependent on the employed robot in training or dimension-specific, which cannot be directly reused by robots with different dimensional configurations. To address this issue, a novel DRL-based robot navigation method is proposed in this paper. The proposed approach trains a meta-robot with DRL and then transfers the meta-skill to a robot with a different dimensional configuration (named dimension-scaled robot) using a method named dimension-variable skill transfer (DVST), referred to as DRL-DVST. During the training phase, the meta-agent learns to perform self-navigation with the meta-robot in a simulation environment. In the skill-transfer phase, the observations of the dimension-scaled robot are transferred to the meta-agent in a scaled manner, and the control policy generated by the meta-agent is scaled back to the dimension-scaled robot. Simulation and real-world experimental results indicate that robots with different sizes and angular velocity bounds can accomplish navigation tasks in unknown and dynamic environments without any retraining. This work greatly extends the application range of DRL-based navigation methods from the fixed dimensional configuration to varied dimensional configurations.