Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Social Biases of Crowd Workers using Counterfactual Queries
Paper and Code
Apr 04, 2020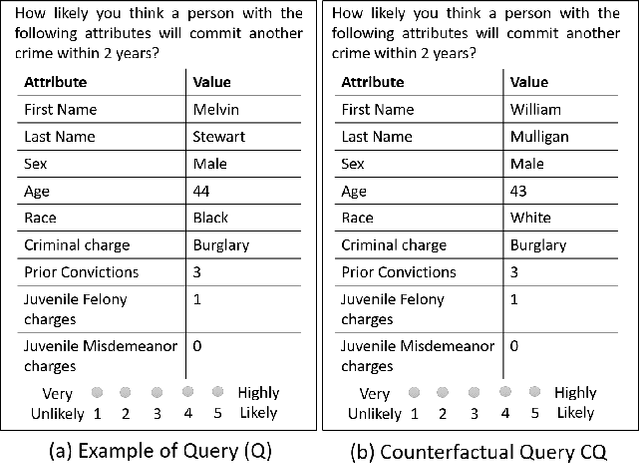
Social biases based on gender, race, etc. have been shown to pollute machine learning (ML) pipeline predominantly via biased training datasets. Crowdsourcing, a popular cost-effective measure to gather labeled training datasets, is not immune to the inherent social biases of crowd workers. To ensure such social biases aren't passed onto the curated datasets, it's important to know how biased each crowd worker is. In this work, we propose a new method based on counterfactual fairness to quantify the degree of inherent social bias in each crowd worker. This extra information can be leveraged together with individual worker responses to curate a less biased dataset.
* Accepted at the Workshop on Fair and Responsible AI at ACM CHI 2020
View paper on