 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Ask Gauss: Improved One-Run Privacy Auditing
Jun 10, 2026Privacy auditing provides an important safeguard by estimating the actual information leaked by a model, thus ensuring that theoretical privacy guarantees hold in practice. We study empirical privacy auditing for differentially private (DP) machine learning, focusing on efficient one-run methods for mechanisms such as DP-SGD. Prior one-run approaches threshold training examples or "canaries" into binary membership guesses, which discards useful information. We show that, in the white-box DP-SGD setting, canary-aligned signals naturally form a sequence of random variables whose normalized sum is asymptotically Gaussian. Leveraging this distributional perspective, we develop a DP-auditing framework that leads to tighter privacy lower bounds from a single training run.
Sequential Auditing for f-Differential Privacy
Feb 06, 2026We present new auditors to assess Differential Privacy (DP) of an algorithm based on output samples. Such empirical auditors are common to check for algorithmic correctness and implementation bugs. Most existing auditors are batch-based or targeted toward the traditional notion of $(\varepsilon,δ)$-DP; typically both. In this work, we shift the focus to the highly expressive privacy concept of $f$-DP, in which the entire privacy behavior is captured by a single tradeoff curve. Our auditors detect violations across the full privacy spectrum with statistical significance guarantees, which are supported by theory and simulations. Most importantly, and in contrast to prior work, our auditors do not require a user-specified sample size as an input. Rather, they adaptively determine a near-optimal number of samples needed to reach a decision, thereby avoiding the excessively large sample sizes common in many auditing studies. This reduction in sampling cost becomes especially beneficial for expensive training procedures such as DP-SGD. Our method supports both whitebox and blackbox settings and can also be executed in single-run frameworks.
Trustworthy Reputation Games and Applications to Proof-of-Reputation Blockchains
May 20, 2025Reputation systems play an essential role in the Internet era, as they enable people to decide whom to trust, by collecting and aggregating data about users' behavior. Recently, several works proposed the use of reputation for the design and scalability improvement of decentralized (blockchain) ledgers; however, such systems are prone to manipulation and to our knowledge no game-theoretic treatment exists that can support their economic robustness. In this work we put forth a new model for the design of what we call, {\em trustworthy reputation systems}. Concretely, we describe a class of games, which we term {\em trustworthy reputation games}, that enable a set of users to report a function of their beliefs about the trustworthiness of each server in a set -- i.e., their estimate of the probability that this server will behave according to its specified strategy -- in a way that satisfies the following properties: 1. It is $(\epsilon$-)best response for any rational user in the game to play a prescribed (truthful) strategy according to their true belief. 2. Assuming that the users' beliefs are not too far from the {\em true} trustworthiness of the servers, playing the above ($\epsilon-$)Nash equilibrium allows anyone who observes the users' strategies to estimate the relative trustworthiness of any two servers. Our utilities and decoding function build on a connection between the well known PageRank algorithm and the problem of trustworthiness discovery, which can be of independent interest. Finally, we show how the above games are motivated by and can be leveraged in proof-of-reputation (PoR) blockchains.
Privacy-Utility Tradeoff of OLS with Random Projections
Sep 03, 2023



We study the differential privacy (DP) of a core ML problem, linear ordinary least squares (OLS), a.k.a. $\ell_2$-regression. Our key result is that the approximate LS algorithm (ALS) (Sarlos, 2006), a randomized solution to the OLS problem primarily used to improve performance on large datasets, also preserves privacy. ALS achieves a better privacy/utility tradeoff, without modifications or further noising, when compared to alternative private OLS algorithms which modify and/or noise OLS. We give the first {\em tight} DP-analysis for the ALS algorithm and the standard Gaussian mechanism (Dwork et al., 2014) applied to OLS. Our methodology directly improves the privacy analysis of (Blocki et al., 2012) and (Sheffet, 2019)) and introduces new tools which may be of independent interest: (1) the exact spectrum of $(\epsilon, \delta)$-DP parameters (``DP spectrum") for mechanisms whose output is a $d$-dimensional Gaussian, and (2) an improved DP spectrum for random projection (compared to (Blocki et al., 2012) and (Sheffet, 2019)). All methods for private OLS (including ours) assume, often implicitly, restrictions on the input database, such as bounds on leverage and residuals. We prove that such restrictions are necessary. Hence, computing the privacy of mechanisms such as ALS must estimate these database parameters, which can be infeasible in big datasets. For more complex ML models, DP bounds may not even be tractable. There is a need for blackbox DP-estimators (Lu et al., 2022) which empirically estimate a data-dependent privacy. We demonstrate the effectiveness of such a DP-estimator by empirically recovering a DP-spectrum that matches our theory for OLS. This validates the DP-estimator in a nontrivial ML application, opening the door to its use in more complex nonlinear ML settings where theory is unavailable.
PD-ML-Lite: Private Distributed Machine Learning from Lighweight Cryptography
Jan 23, 2019
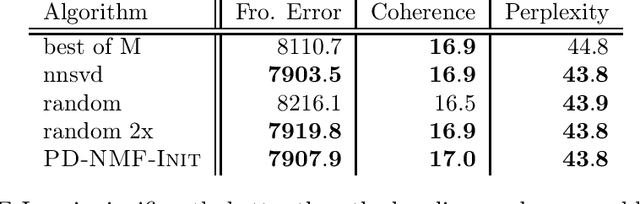
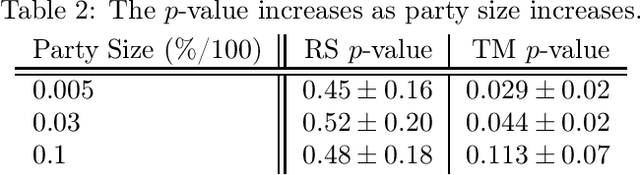
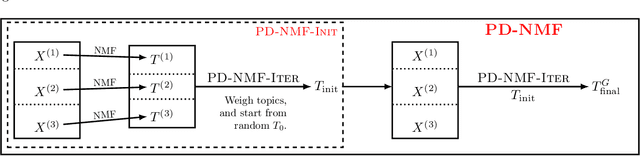
Privacy is a major issue in learning from distributed data. Recently the cryptographic literature has provided several tools for this task. However, these tools either reduce the quality/accuracy of the learning algorithm---e.g., by adding noise---or they incur a high performance penalty and/or involve trusting external authorities. We propose a methodology for {\sl private distributed machine learning from light-weight cryptography} (in short, PD-ML-Lite). We apply our methodology to two major ML algorithms, namely non-negative matrix factorization (NMF) and singular value decomposition (SVD). Our resulting protocols are communication optimal, achieve the same accuracy as their non-private counterparts, and satisfy a notion of privacy---which we define---that is both intuitive and measurable. Our approach is to use lightweight cryptographic protocols (secure sum and normalized secure sum) to build learning algorithms rather than wrap complex learning algorithms in a heavy-cost MPC framework. We showcase our algorithms' utility and privacy on several applications: for NMF we consider topic modeling and recommender systems, and for SVD, principal component regression, and low rank approximation.