 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Neural Light Field on Mobile Devices
Dec 15, 2022Recent efforts in Neural Rendering Fields (NeRF) have shown impressive results on novel view synthesis by utilizing implicit neural representation to represent 3D scenes. Due to the process of volumetric rendering, the inference speed for NeRF is extremely slow, limiting the application scenarios of utilizing NeRF on resource-constrained hardware, such as mobile devices. Many works have been conducted to reduce the latency of running NeRF models. However, most of them still require high-end GPU for acceleration or extra storage memory, which is all unavailable on mobile devices. Another emerging direction utilizes the neural light field (NeLF) for speedup, as only one forward pass is performed on a ray to predict the pixel color. Nevertheless, to reach a similar rendering quality as NeRF, the network in NeLF is designed with intensive computation, which is not mobile-friendly. In this work, we propose an efficient network that runs in real-time on mobile devices for neural rendering. We follow the setting of NeLF to train our network. Unlike existing works, we introduce a novel network architecture that runs efficiently on mobile devices with low latency and small size, i.e., saving $15\times \sim 24\times$ storage compared with MobileNeRF. Our model achieves high-resolution generation while maintaining real-time inference for both synthetic and real-world scenes on mobile devices, e.g., $18.04$ms (iPhone 13) for rendering one $1008\times756$ image of real 3D scenes. Additionally, we achieve similar image quality as NeRF and better quality than MobileNeRF (PSNR $26.15$ vs. $25.91$ on the real-world forward-facing dataset).
NeRFInvertor: High Fidelity NeRF-GAN Inversion for Single-shot Real Image Animation
Nov 30, 2022Nerf-based Generative models have shown impressive capacity in generating high-quality images with consistent 3D geometry. Despite successful synthesis of fake identity images randomly sampled from latent space, adopting these models for generating face images of real subjects is still a challenging task due to its so-called inversion issue. In this paper, we propose a universal method to surgically fine-tune these NeRF-GAN models in order to achieve high-fidelity animation of real subjects only by a single image. Given the optimized latent code for an out-of-domain real image, we employ 2D loss functions on the rendered image to reduce the identity gap. Furthermore, our method leverages explicit and implicit 3D regularizations using the in-domain neighborhood samples around the optimized latent code to remove geometrical and visual artifacts. Our experiments confirm the effectiveness of our method in realistic, high-fidelity, and 3D consistent animation of real faces on multiple NeRF-GAN models across different datasets.
Look More but Care Less in Video Recognition
Nov 18, 2022



Existing action recognition methods typically sample a few frames to represent each video to avoid the enormous computation, which often limits the recognition performance. To tackle this problem, we propose Ample and Focal Network (AFNet), which is composed of two branches to utilize more frames but with less computation. Specifically, the Ample Branch takes all input frames to obtain abundant information with condensed computation and provides the guidance for Focal Branch by the proposed Navigation Module; the Focal Branch squeezes the temporal size to only focus on the salient frames at each convolution block; in the end, the results of two branches are adaptively fused to prevent the loss of information. With this design, we can introduce more frames to the network but cost less computation. Besides, we demonstrate AFNet can utilize fewer frames while achieving higher accuracy as the dynamic selection in intermediate features enforces implicit temporal modeling. Further, we show that our method can be extended to reduce spatial redundancy with even less cost. Extensive experiments on five datasets demonstrate the effectiveness and efficiency of our method.
Parameter-Efficient Masking Networks
Oct 13, 2022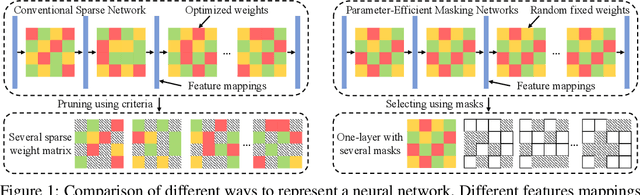
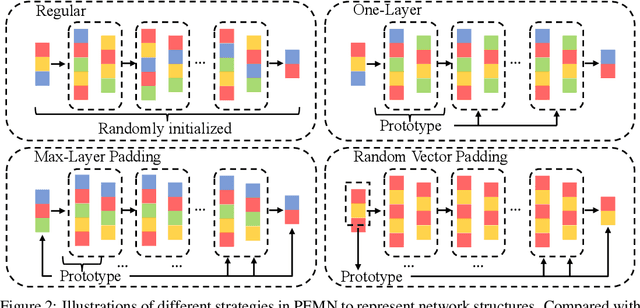
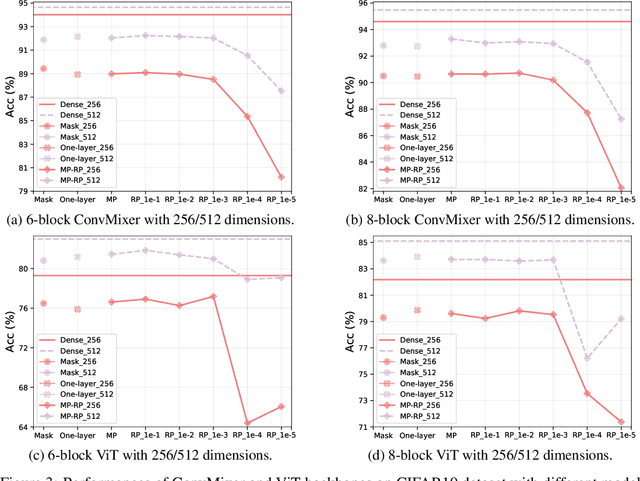
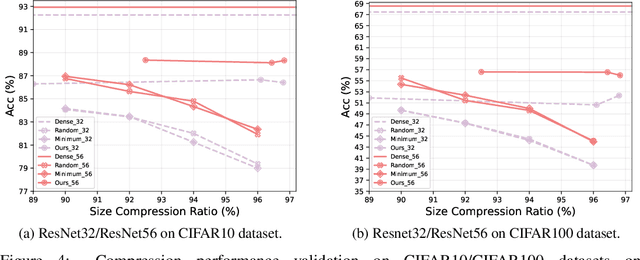
A deeper network structure generally handles more complicated non-linearity and performs more competitively. Nowadays, advanced network designs often contain a large number of repetitive structures (e.g., Transformer). They empower the network capacity to a new level but also increase the model size inevitably, which is unfriendly to either model restoring or transferring. In this study, we are the first to investigate the representative potential of fixed random weights with limited unique values by learning diverse masks and introduce the Parameter-Efficient Masking Networks (PEMN). It also naturally leads to a new paradigm for model compression to diminish the model size. Concretely, motivated by the repetitive structures in modern neural networks, we utilize one random initialized layer, accompanied with different masks, to convey different feature mappings and represent repetitive network modules. Therefore, the model can be expressed as \textit{one-layer} with a bunch of masks, which significantly reduce the model storage cost. Furthermore, we enhance our strategy by learning masks for a model filled by padding a given random weights vector. In this way, our method can further lower the space complexity, especially for models without many repetitive architectures. We validate the potential of PEMN learning masks on random weights with limited unique values and test its effectiveness for a new compression paradigm based on different network architectures. Code is available at https://github.com/yueb17/PEMN
Trainability Preserving Neural Structured Pruning
Jul 25, 2022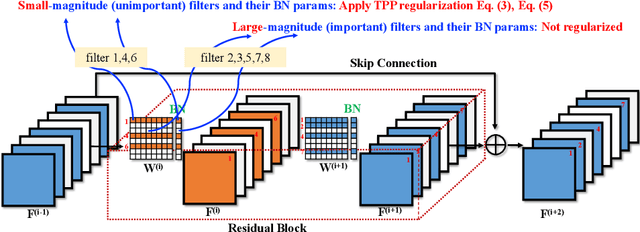
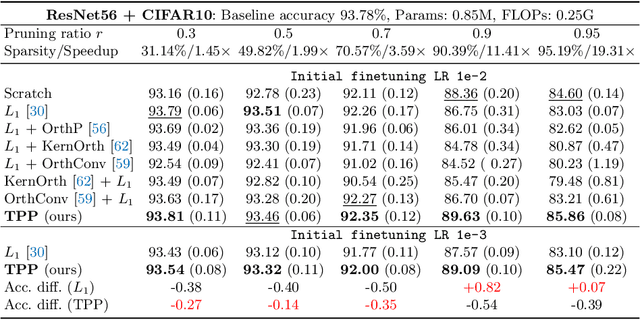
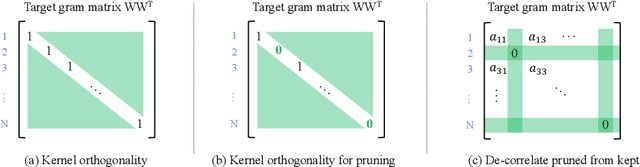
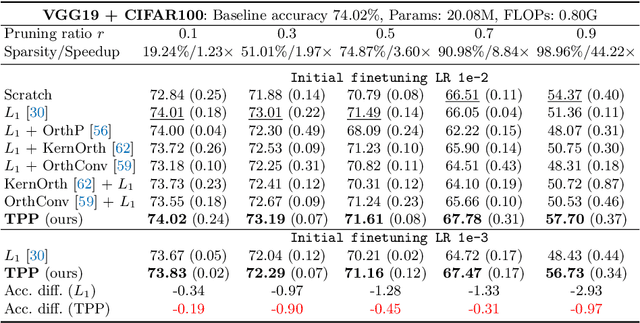
Several recent works empirically find finetuning learning rate is critical to the final performance in neural network structured pruning. Further researches find that the network trainability broken by pruning answers for it, thus calling for an urgent need to recover trainability before finetuning. Existing attempts propose to exploit weight orthogonalization to achieve dynamical isometry for improved trainability. However, they only work for linear MLP networks. How to develop a filter pruning method that maintains or recovers trainability and is scalable to modern deep networks remains elusive. In this paper, we present trainability preserving pruning (TPP), a regularization-based structured pruning method that can effectively maintain trainability during sparsification. Specifically, TPP regularizes the gram matrix of convolutional kernels so as to de-correlate the pruned filters from the kept filters. Beside the convolutional layers, we also propose to regularize the BN parameters for better preserving trainability. Empirically, TPP can compete with the ground-truth dynamical isometry recovery method on linear MLP networks. On non-linear networks (ResNet56/VGG19, CIFAR datasets), it outperforms the other counterpart solutions by a large margin. Moreover, TPP can also work effectively with modern deep networks (ResNets) on ImageNet, delivering encouraging performance in comparison to many top-performing filter pruning methods. To our best knowledge, this is the first approach that effectively maintains trainability during pruning for the large-scale deep neural networks.
Towards Layer-wise Image Vectorization
Jun 09, 2022
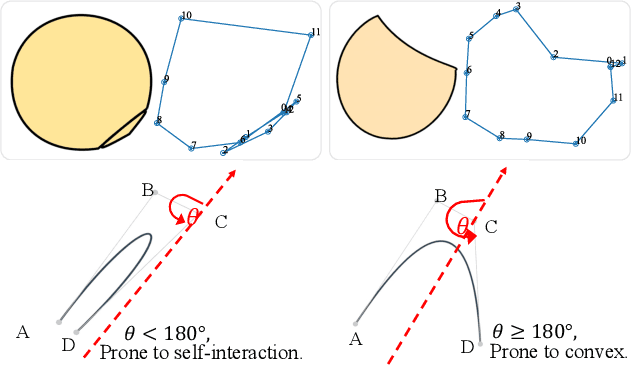


Image rasterization is a mature technique in computer graphics, while image vectorization, the reverse path of rasterization, remains a major challenge. Recent advanced deep learning-based models achieve vectorization and semantic interpolation of vector graphs and demonstrate a better topology of generating new figures. However, deep models cannot be easily generalized to out-of-domain testing data. The generated SVGs also contain complex and redundant shapes that are not quite convenient for further editing. Specifically, the crucial layer-wise topology and fundamental semantics in images are still not well understood and thus not fully explored. In this work, we propose Layer-wise Image Vectorization, namely LIVE, to convert raster images to SVGs and simultaneously maintain its image topology. LIVE can generate compact SVG forms with layer-wise structures that are semantically consistent with human perspective. We progressively add new bezier paths and optimize these paths with the layer-wise framework, newly designed loss functions, and component-wise path initialization technique. Our experiments demonstrate that LIVE presents more plausible vectorized forms than prior works and can be generalized to new images. With the help of this newly learned topology, LIVE initiates human editable SVGs for both designers and other downstream applications. Codes are made available at https://github.com/Picsart-AI-Research/LIVE-Layerwise-Image-Vectorization.
Test-time Fourier Style Calibration for Domain Generalization
May 18, 2022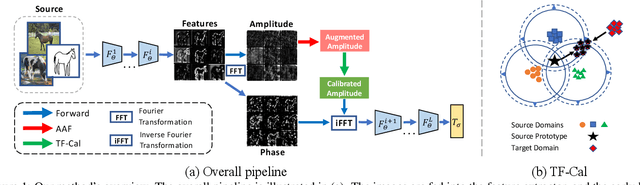
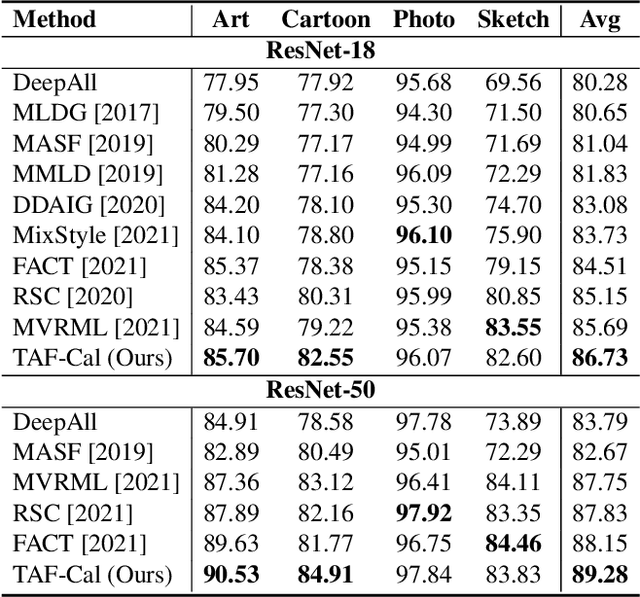
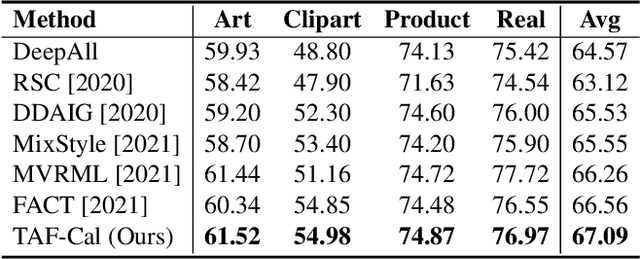
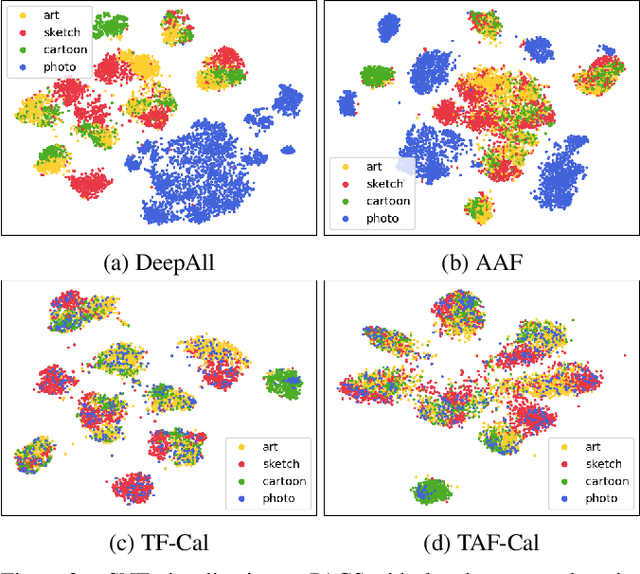
The topic of generalizing machine learning models learned on a collection of source domains to unknown target domains is challenging. While many domain generalization (DG) methods have achieved promising results, they primarily rely on the source domains at train-time without manipulating the target domains at test-time. Thus, it is still possible that those methods can overfit to source domains and perform poorly on target domains. Driven by the observation that domains are strongly related to styles, we argue that reducing the gap between source and target styles can boost models' generalizability. To solve the dilemma of having no access to the target domain during training, we introduce Test-time Fourier Style Calibration (TF-Cal) for calibrating the target domain style on the fly during testing. To access styles, we utilize Fourier transformation to decompose features into amplitude (style) features and phase (semantic) features. Furthermore, we present an effective technique to Augment Amplitude Features (AAF) to complement TF-Cal. Extensive experiments on several popular DG benchmarks and a segmentation dataset for medical images demonstrate that our method outperforms state-of-the-art methods.
R2L: Distilling Neural Radiance Field to Neural Light Field for Efficient Novel View Synthesis
Mar 31, 2022
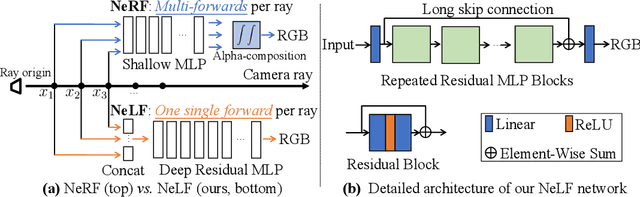
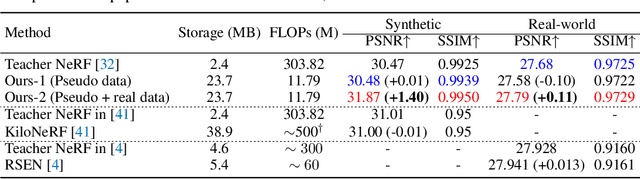
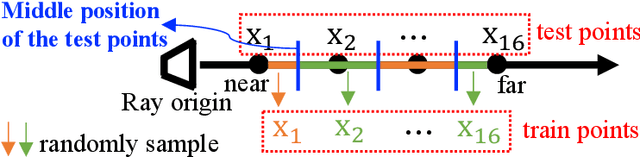
Recent research explosion on Neural Radiance Field (NeRF) shows the encouraging potential to represent complex scenes with neural networks. One major drawback of NeRF is its prohibitive inference time: Rendering a single pixel requires querying the NeRF network hundreds of times. To resolve it, existing efforts mainly attempt to reduce the number of required sampled points. However, the problem of iterative sampling still exists. On the other hand, Neural Light Field (NeLF) presents a more straightforward representation over NeRF in novel view synthesis -- the rendering of a pixel amounts to one single forward pass without ray-marching. In this work, we present a deep residual MLP network (88 layers) to effectively learn the light field. We show the key to successfully learning such a deep NeLF network is to have sufficient data, for which we transfer the knowledge from a pre-trained NeRF model via data distillation. Extensive experiments on both synthetic and real-world scenes show the merits of our method over other counterpart algorithms. On the synthetic scenes, we achieve 26-35x FLOPs reduction (per camera ray) and 28-31x runtime speedup, meanwhile delivering significantly better (1.4-2.8 dB average PSNR improvement) rendering quality than NeRF without any customized implementation tricks.
Single-Stream Multi-Level Alignment for Vision-Language Pretraining
Mar 30, 2022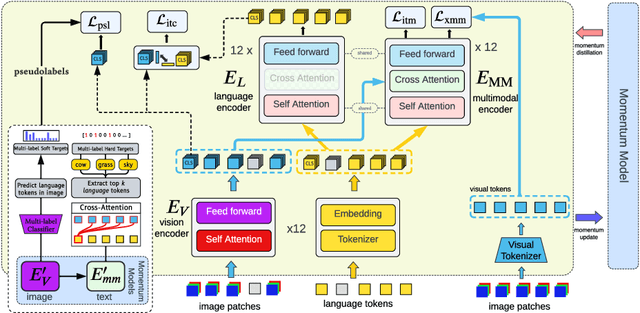
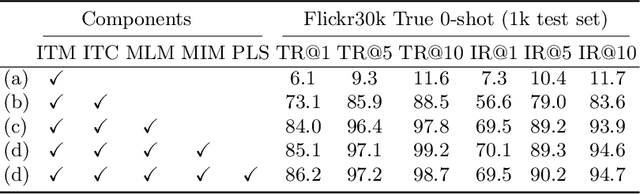
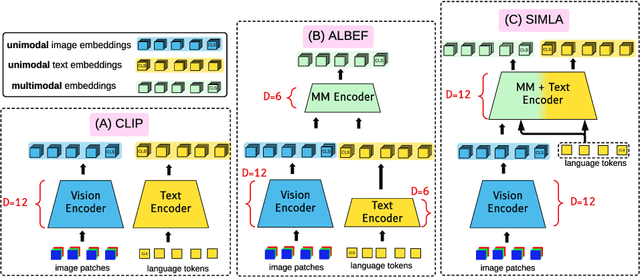
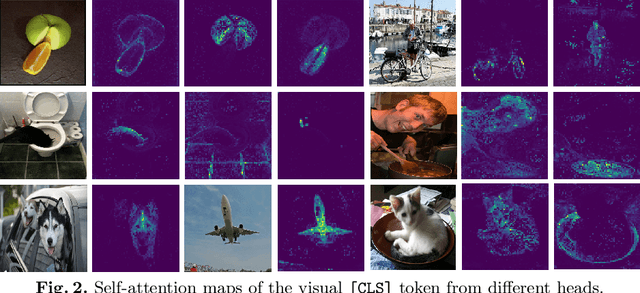
Recent progress in large-scale vision-language pre-training has shown the importance of aligning the visual and text modalities for downstream vision-language tasks. Many methods use a dual-stream architecture that fuses visual tokens and language tokens after representation learning, which aligns only at a global level and cannot extract finer-scale semantics. In contrast, we propose a single stream model that aligns the modalities at multiple levels: i) instance level, ii) fine-grained patch level, iii) conceptual semantic level. We achieve this using two novel tasks: symmetric cross-modality reconstruction and a pseudo-labeled key word prediction. In the former part, we mask the input tokens from one of the modalities and use the cross-modal information to reconstruct the masked token, thus improving fine-grained alignment between the two modalities. In the latter part, we parse the caption to select a few key words and feed it together with the momentum encoder pseudo signal to self-supervise the visual encoder, enforcing it to learn rich semantic concepts that are essential for grounding a textual token to an image region. We demonstrate top performance on a set of Vision-Language downstream tasks such as zero-shot/fine-tuned image/text retrieval, referring expression, and VQA. We also demonstrate how the proposed models can align the modalities at multiple levels.
Adaptive Trajectory Prediction via Transferable GNN
Mar 26, 2022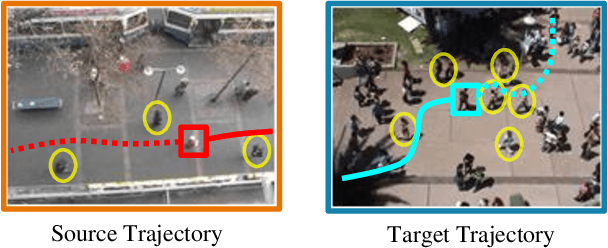
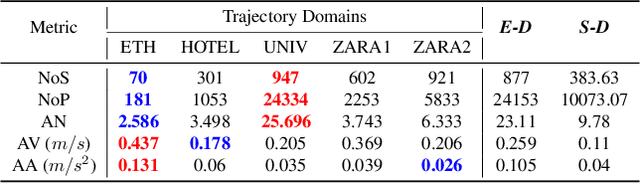
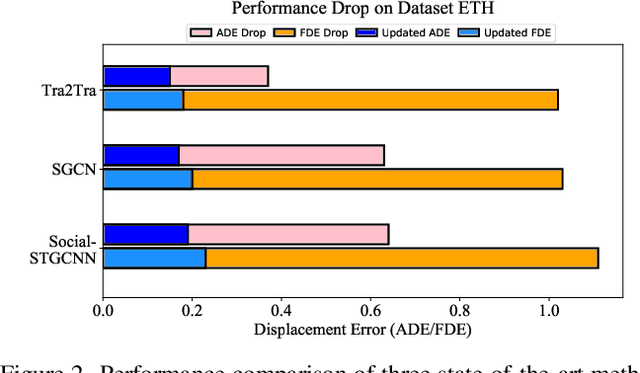

Pedestrian trajectory prediction is an essential component in a wide range of AI applications such as autonomous driving and robotics. Existing methods usually assume the training and testing motions follow the same pattern while ignoring the potential distribution differences (e.g., shopping mall and street). This issue results in inevitable performance decrease. To address this issue, we propose a novel Transferable Graph Neural Network (T-GNN) framework, which jointly conducts trajectory prediction as well as domain alignment in a unified framework. Specifically, a domain-invariant GNN is proposed to explore the structural motion knowledge where the domain-specific knowledge is reduced. Moreover, an attention-based adaptive knowledge learning module is further proposed to explore fine-grained individual-level feature representations for knowledge transfer. By this way, disparities across different trajectory domains will be better alleviated. More challenging while practical trajectory prediction experiments are designed, and the experimental results verify the superior performance of our proposed model. To the best of our knowledge, our work is the pioneer which fills the gap in benchmarks and techniques for practical pedestrian trajectory prediction across different domains.