 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFHAvatar: Fast and High-Fidelity Reconstruction of Face-and-Hair Composable 3D Head Avatar from Few Casual Captures
Mar 24, 2026We present FHAvatar, a novel framework for reconstructing 3D Gaussian avatars with composable face and hair components from an arbitrary number of views. Unlike previous approaches that couple facial and hair representations within a unified modeling process, we explicitly decouple two components in texture space by representing the face with planar Gaussians and the hair with strand-based Gaussians. To overcome the limitations of existing methods that rely on dense multi-view captures or costly per-identity optimization, we propose an aggregated transformer backbone to learn geometry-aware cross-view priors and head-hair structural coherence from multi-view datasets, enabling effective and efficient feature extraction and fusion from few casual captures. Extensive quantitative and qualitative experiments demonstrate that FHAvatar achieves state-of-the-art reconstruction quality from only a few observations of new identities within minutes, while supporting real-time animation, convenient hairstyle transfer, and stylized editing, broadening the accessibility and applicability of digital avatar creation.
GraphiContact: Pose-aware Human-Scene Robust Contact Perception for Interactive Systems
Mar 19, 2026Monocular vertex-level human-scene contact prediction is a fundamental capability for interactive systems such as assistive monitoring, embodied AI, and rehabilitation analysis. In this work, we study this task jointly with single-image 3D human mesh reconstruction, using reconstructed body geometry as a scaffold for contact reasoning. Existing approaches either focus on contact prediction without sufficiently exploiting explicit 3D human priors, or emphasize pose/mesh reconstruction without directly optimizing robust vertex-level contact inference under occlusion and perceptual noise. To address this gap, we propose GraphiContact, a pose-aware framework that transfers complementary human priors from two pretrained Transformer encoders and predicts per-vertex human-scene contact on the reconstructed mesh. To improve robustness in real-world scenarios, we further introduce a Single-Image Multi-Infer Uncertainty (SIMU) training strategy with token-level adaptive routing, which simulates occlusion and noisy observations during training while preserving efficient single-branch inference at test time. Experiments on five benchmark datasets show that GraphiContact achieves consistent gains on both contact prediction and 3D human reconstruction. Our code, based on the GraphiContact method, provides comprehensive 3D human reconstruction and interaction analysis, and will be publicly available at https://github.com/Aveiro-Lin/GraphiContact.
PEP-GS: Perceptually-Enhanced Precise Structured 3D Gaussians for View-Adaptive Rendering
Nov 08, 2024



Recent advances in structured 3D Gaussians for view-adaptive rendering, particularly through methods like Scaffold-GS, have demonstrated promising results in neural scene representation. However, existing approaches still face challenges in perceptual consistency and precise view-dependent effects. We present PEP-GS, a novel framework that enhances structured 3D Gaussians through three key innovations: (1) a Local-Enhanced Multi-head Self-Attention (LEMSA) mechanism that replaces spherical harmonics for more accurate view-dependent color decoding, and (2) Kolmogorov-Arnold Networks (KAN) that optimize Gaussian opacity and covariance functions for enhanced interpretability and splatting precision. (3) a Neural Laplacian Pyramid Decomposition (NLPD) that improves perceptual similarity across views. Our comprehensive evaluation across multiple datasets indicates that, compared to the current state-of-the-art methods, these improvements are particularly evident in challenging scenarios such as view-dependent effects, specular reflections, fine-scale details and false geometry generation.
Large Language Models for Mobility in Transportation Systems: A Survey on Forecasting Tasks
May 03, 2024

Mobility analysis is a crucial element in the research area of transportation systems. Forecasting traffic information offers a viable solution to address the conflict between increasing transportation demands and the limitations of transportation infrastructure. Predicting human travel is significant in aiding various transportation and urban management tasks, such as taxi dispatch and urban planning. Machine learning and deep learning methods are favored for their flexibility and accuracy. Nowadays, with the advent of large language models (LLMs), many researchers have combined these models with previous techniques or applied LLMs to directly predict future traffic information and human travel behaviors. However, there is a lack of comprehensive studies on how LLMs can contribute to this field. This survey explores existing approaches using LLMs for mobility forecasting problems. We provide a literature review concerning the forecasting applications within transportation systems, elucidating how researchers utilize LLMs, showcasing recent state-of-the-art advancements, and identifying the challenges that must be overcome to fully leverage LLMs in this domain.
Form 10-Q Itemization
Apr 23, 2021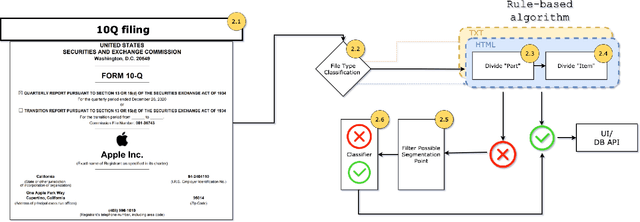


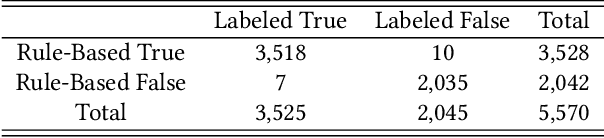
Form 10-Q, the quarterly financial statement, is one of the most crucial filings for US public firms to disclose their financial and other relevant business operation information. Due to the gigantic number of 10-Q filings prevailing in the market for each quarter and diverse variations in the implementation of format given company-specific nature, it has long been a problem in the field to provide a generalized way to dissect and retrieve the itemized information. In this paper, we create a tool to itemize 10-Q filings using multi-stage processes, blending a rule-based algorithm with a CNN deep learning model. The implementation is an integrated pipeline which provides a solution to the item retrieval on a large scale. This would enable cross sectional and longitudinal textual analysis on massive number of companies.