 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINT: An Inequality Benchmark for Evaluating Generalization in Theorem Proving
Jul 06, 2020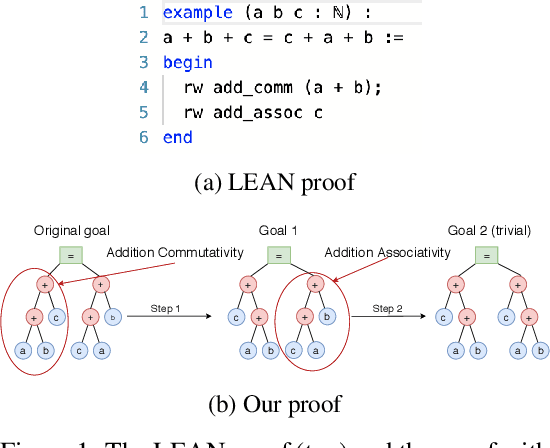
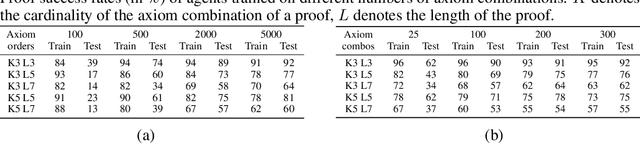
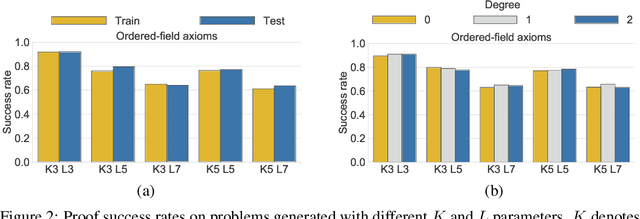
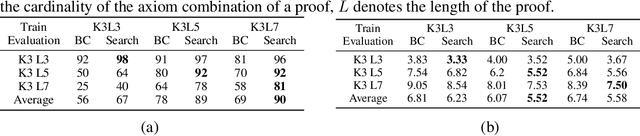
In learning-assisted theorem proving, one of the most critical challenges is to generalize to theorems unlike those seen at training time. In this paper, we introduce INT, an INequality Theorem proving benchmark, specifically designed to test agents' generalization ability. INT is based on a procedure for generating theorems and proofs; this procedure's knobs allow us to measure 6 different types of generalization, each reflecting a distinct challenge characteristic to automated theorem proving. In addition, unlike prior benchmarks for learning-assisted theorem proving, INT provides a lightweight and user-friendly theorem proving environment with fast simulations, conducive to performing learning-based and search-based research. We introduce learning-based baselines and evaluate them across 6 dimensions of generalization with the benchmark. We then evaluate the same agents augmented with Monte Carlo Tree Search (MCTS) at test time, and show that MCTS can help to prove new theorems.
Modelling High-Level Mathematical Reasoning in Mechanised Declarative Proofs
Jun 13, 2020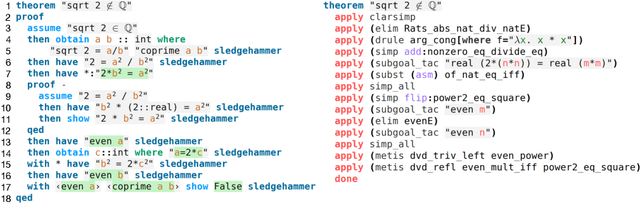


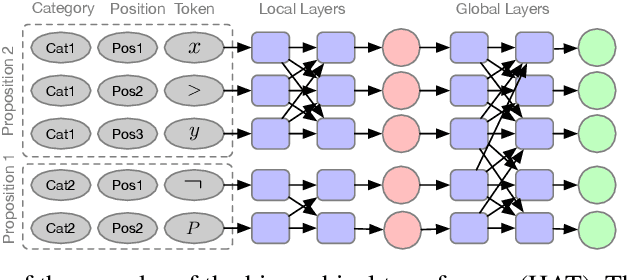
Mathematical proofs can be mechanised using proof assistants to eliminate gaps and errors. However, mechanisation still requires intensive labour. To promote automation, it is essential to capture high-level human mathematical reasoning, which we address as the problem of generating suitable propositions. We build a non-synthetic dataset from the largest repository of mechanised proofs and propose a task on causal reasoning, where a model is required to fill in a missing intermediate proposition given a causal context. Our experiments (using various neural sequence-to-sequence models) reveal that while the task is challenging, neural models can indeed capture non-trivial mathematical reasoning. We further propose a hierarchical transformer model that outperforms the transformer baseline.
Options as responses: Grounding behavioural hierarchies in multi-agent RL
Jun 06, 2019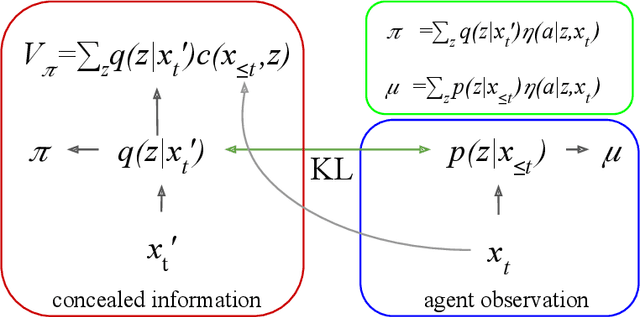
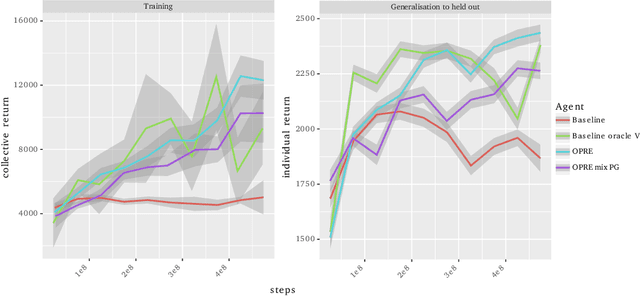
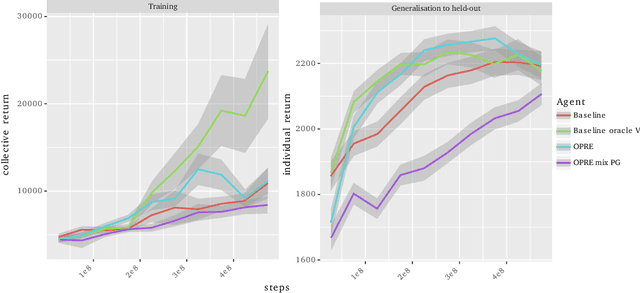
We propose a novel hierarchical agent architecture for multi-agent reinforcement learning with concealed information. The hierarchy is grounded in the concealed information about other players, which resolves "the chicken or the egg" nature of option discovery. We factorise the value function over a latent representation of the concealed information and then re-use this latent space to factorise the policy into options. Low-level policies (options) are trained to respond to particular states of other agents grouped by the latent representation, while the top level (meta-policy) learns to infer the latent representation from its own observation thereby to select the right option. This grounding facilitates credit assignment across the levels of hierarchy. We show that this helps generalisation---performance against a held-out set of pre-trained competitors, while training in self- or population-play---and resolution of social dilemmas in self-play.
Concurrent Meta Reinforcement Learning
Mar 07, 2019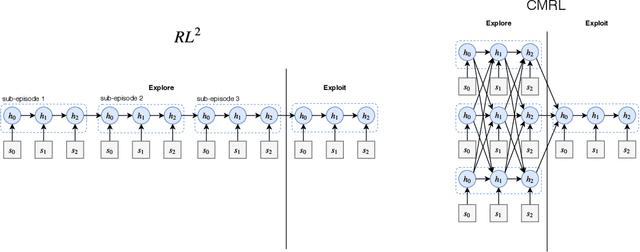
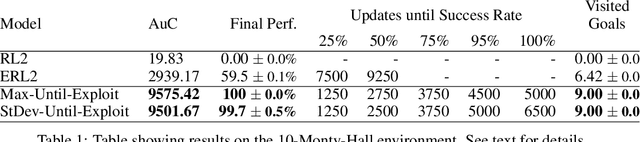

State-of-the-art meta reinforcement learning algorithms typically assume the setting of a single agent interacting with its environment in a sequential manner. A negative side-effect of this sequential execution paradigm is that, as the environment becomes more and more challenging, and thus requiring more interaction episodes for the meta-learner, it needs the agent to reason over longer and longer time-scales. To combat the difficulty of long time-scale credit assignment, we propose an alternative parallel framework, which we name "Concurrent Meta-Reinforcement Learning" (CMRL), that transforms the temporal credit assignment problem into a multi-agent reinforcement learning one. In this multi-agent setting, a set of parallel agents are executed in the same environment and each of these "rollout" agents are given the means to communicate with each other. The goal of the communication is to coordinate, in a collaborative manner, the most efficient exploration of the shared task the agents are currently assigned. This coordination therefore represents the meta-learning aspect of the framework, as each agent can be assigned or assign itself a particular section of the current task's state space. This framework is in contrast to standard RL methods that assume that each parallel rollout occurs independently, which can potentially waste computation if many of the rollouts end up sampling the same part of the state space. Furthermore, the parallel setting enables us to define several reward sharing functions and auxiliary losses that are non-trivial to apply in the sequential setting. We demonstrate the effectiveness of our proposed CMRL at improving over sequential methods in a variety of challenging tasks.
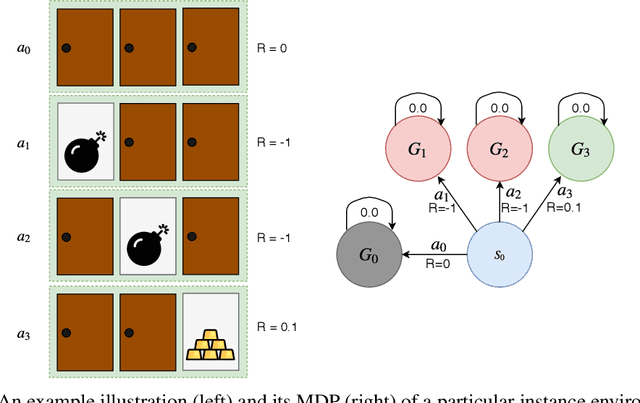
ACTRCE: Augmenting Experience via Teacher's Advice For Multi-Goal Reinforcement Learning
Feb 12, 2019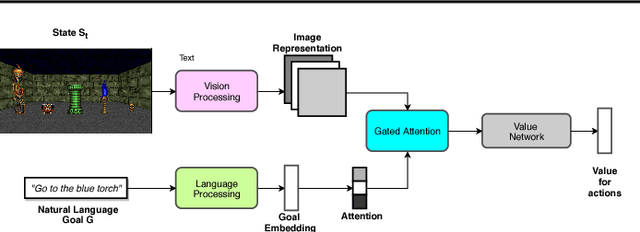
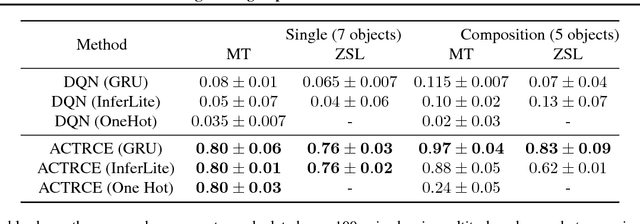
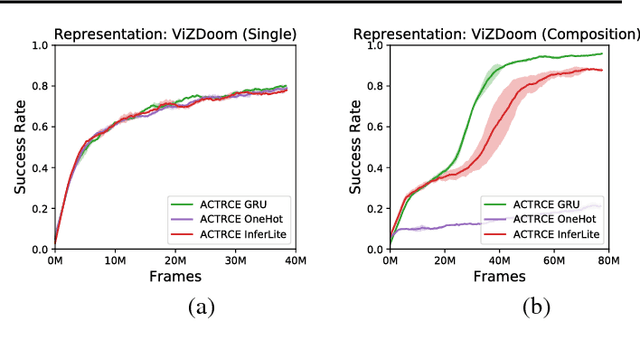

Sparse reward is one of the most challenging problems in reinforcement learning (RL). Hindsight Experience Replay (HER) attempts to address this issue by converting a failed experience to a successful one by relabeling the goals. Despite its effectiveness, HER has limited applicability because it lacks a compact and universal goal representation. We present Augmenting experienCe via TeacheR's adviCE (ACTRCE), an efficient reinforcement learning technique that extends the HER framework using natural language as the goal representation. We first analyze the differences among goal representation, and show that ACTRCE can efficiently solve difficult reinforcement learning problems in challenging 3D navigation tasks, whereas HER with non-language goal representation failed to learn. We also show that with language goal representations, the agent can generalize to unseen instructions, and even generalize to instructions with unseen lexicons. We further demonstrate it is crucial to use hindsight advice to solve challenging tasks, and even small amount of advice is sufficient for the agent to achieve good performance.
Understanding Short-Horizon Bias in Stochastic Meta-Optimization
Mar 06, 2018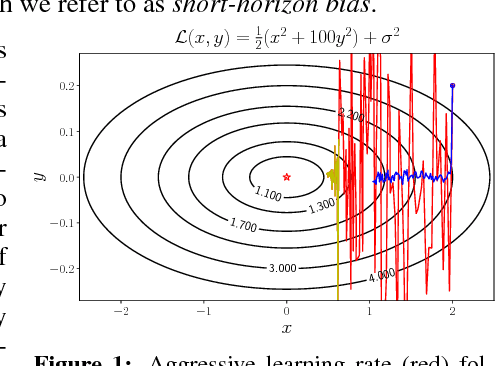
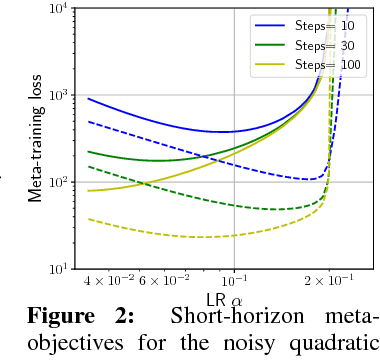
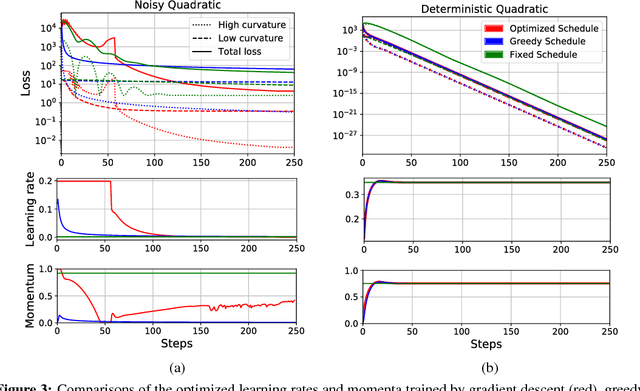
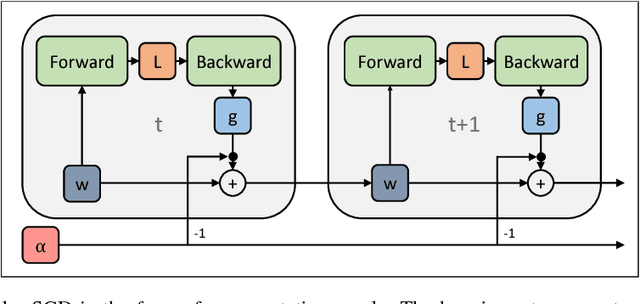
Careful tuning of the learning rate, or even schedules thereof, can be crucial to effective neural net training. There has been much recent interest in gradient-based meta-optimization, where one tunes hyperparameters, or even learns an optimizer, in order to minimize the expected loss when the training procedure is unrolled. But because the training procedure must be unrolled thousands of times, the meta-objective must be defined with an orders-of-magnitude shorter time horizon than is typical for neural net training. We show that such short-horizon meta-objectives cause a serious bias towards small step sizes, an effect we term short-horizon bias. We introduce a toy problem, a noisy quadratic cost function, on which we analyze short-horizon bias by deriving and comparing the optimal schedules for short and long time horizons. We then run meta-optimization experiments (both offline and online) on standard benchmark datasets, showing that meta-optimization chooses too small a learning rate by multiple orders of magnitude, even when run with a moderately long time horizon (100 steps) typical of work in the area. We believe short-horizon bias is a fundamental problem that needs to be addressed if meta-optimization is to scale to practical neural net training regimes.
Some Considerations on Learning to Explore via Meta-Reinforcement Learning
Mar 03, 2018
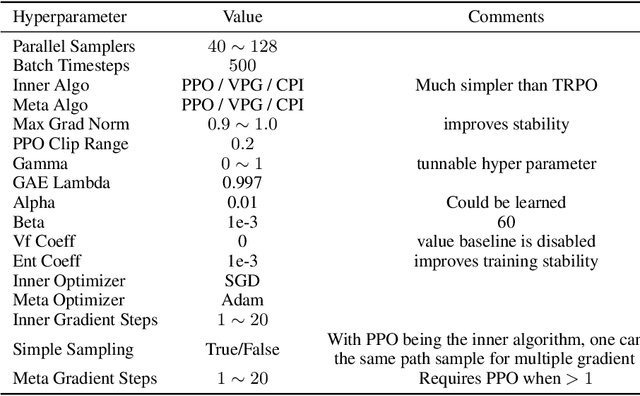

We consider the problem of exploration in meta reinforcement learning. Two new meta reinforcement learning algorithms are suggested: E-MAML and E-$\text{RL}^2$. Results are presented on a novel environment we call `Krazy World' and a set of maze environments. We show E-MAML and E-$\text{RL}^2$ deliver better performance on tasks where exploration is important.
Backpropagation through the Void: Optimizing control variates for black-box gradient estimation
Feb 23, 2018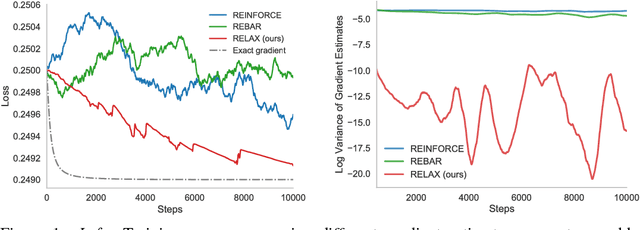
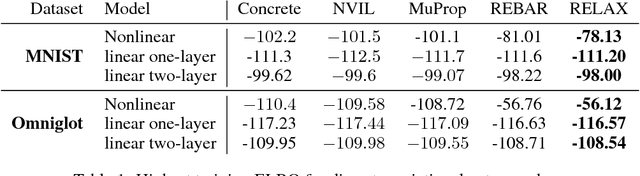
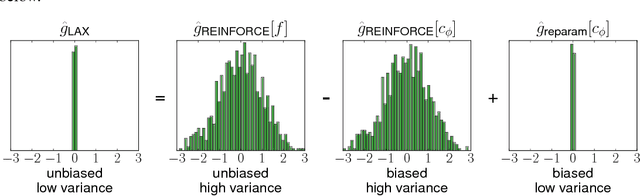

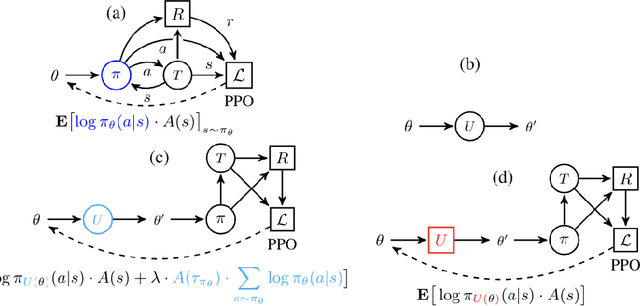
Gradient-based optimization is the foundation of deep learning and reinforcement learning. Even when the mechanism being optimized is unknown or not differentiable, optimization using high-variance or biased gradient estimates is still often the best strategy. We introduce a general framework for learning low-variance, unbiased gradient estimators for black-box functions of random variables. Our method uses gradients of a neural network trained jointly with model parameters or policies, and is applicable in both discrete and continuous settings. We demonstrate this framework for training discrete latent-variable models. We also give an unbiased, action-conditional extension of the advantage actor-critic reinforcement learning algorithm.
An Empirical Analysis of Proximal Policy Optimization with Kronecker-factored Natural Gradients
Jan 17, 2018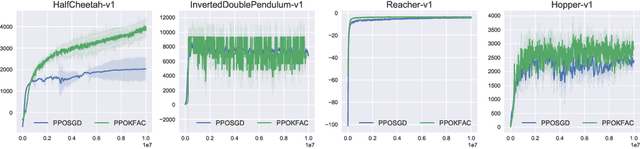
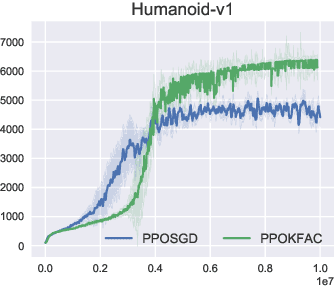
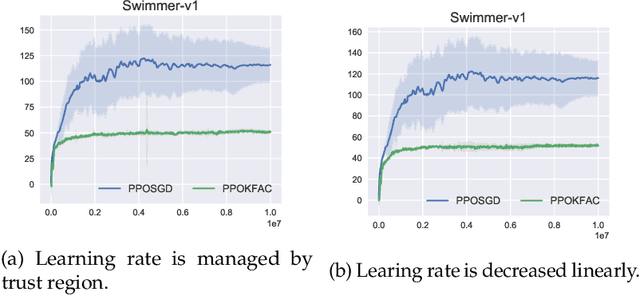
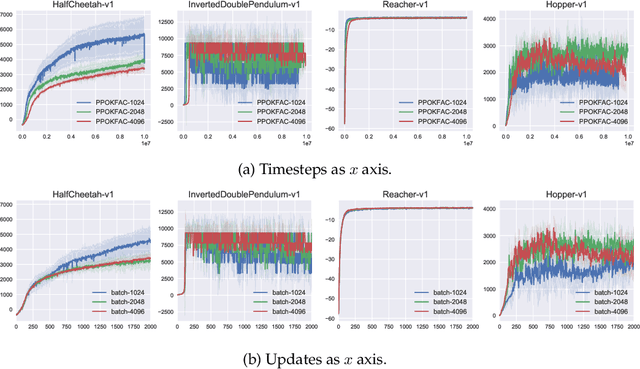
In this technical report, we consider an approach that combines the PPO objective and K-FAC natural gradient optimization, for which we call PPOKFAC. We perform a range of empirical analysis on various aspects of the algorithm, such as sample complexity, training speed, and sensitivity to batch size and training epochs. We observe that PPOKFAC is able to outperform PPO in terms of sample complexity and speed in a range of MuJoCo environments, while being scalable in terms of batch size. In spite of this, it seems that adding more epochs is not necessarily helpful for sample efficiency, and PPOKFAC seems to be worse than its A2C counterpart, ACKTR.
Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation
Aug 18, 2017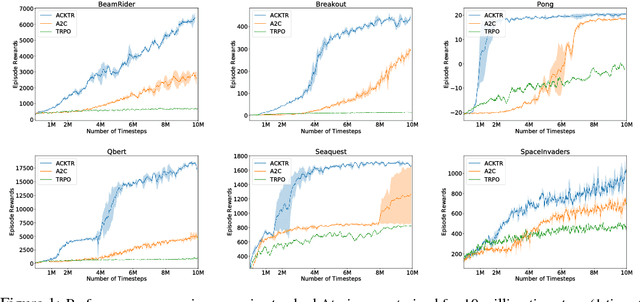
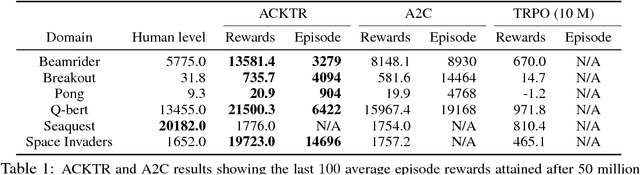
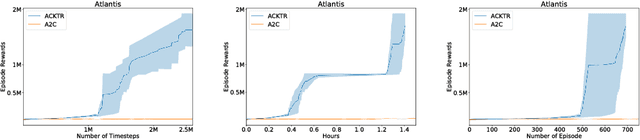
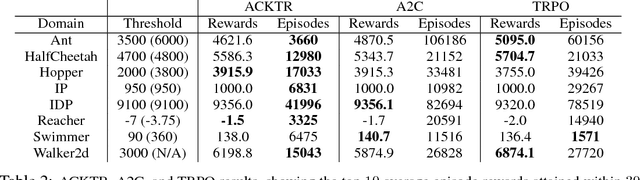
In this work, we propose to apply trust region optimization to deep reinforcement learning using a recently proposed Kronecker-factored approximation to the curvature. We extend the framework of natural policy gradient and propose to optimize both the actor and the critic using Kronecker-factored approximate curvature (K-FAC) with trust region; hence we call our method Actor Critic using Kronecker-Factored Trust Region (ACKTR). To the best of our knowledge, this is the first scalable trust region natural gradient method for actor-critic methods. It is also a method that learns non-trivial tasks in continuous control as well as discrete control policies directly from raw pixel inputs. We tested our approach across discrete domains in Atari games as well as continuous domains in the MuJoCo environment. With the proposed methods, we are able to achieve higher rewards and a 2- to 3-fold improvement in sample efficiency on average, compared to previous state-of-the-art on-policy actor-critic methods. Code is available at https://github.com/openai/baselines