 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Learning Rules for Out-of-Equilibrium Physical Generative Models
Jun 23, 2025We show that the out-of-equilibrium driving protocol of score-based generative models (SGMs) can be learned via a local learning rule. The gradient with respect to the parameters of the driving protocol are computed directly from force measurements or from observed system dynamics. As a demonstration, we implement an SGM in a network of driven, nonlinear, overdamped oscillators coupled to a thermal bath. We first apply it to the problem of sampling from a mixture of two Gaussians in 2D. Finally, we train a network of 10x10 oscillators to sample images of 0s and 1s from the MNIST dataset.
Provably efficient variational generative modeling of quantum many-body systems via quantum-probabilistic information geometry
Jun 09, 2022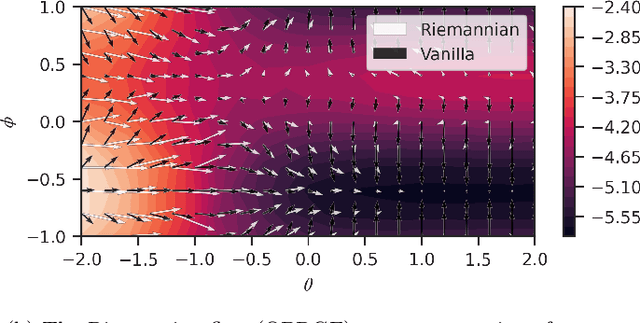
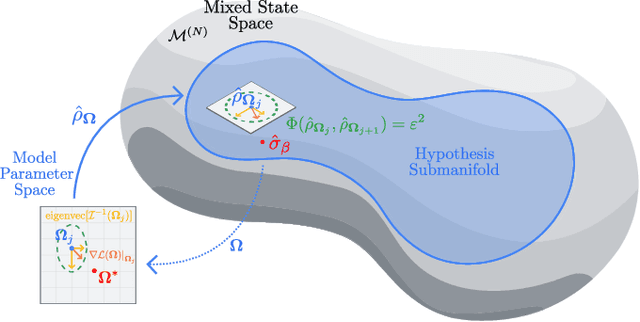
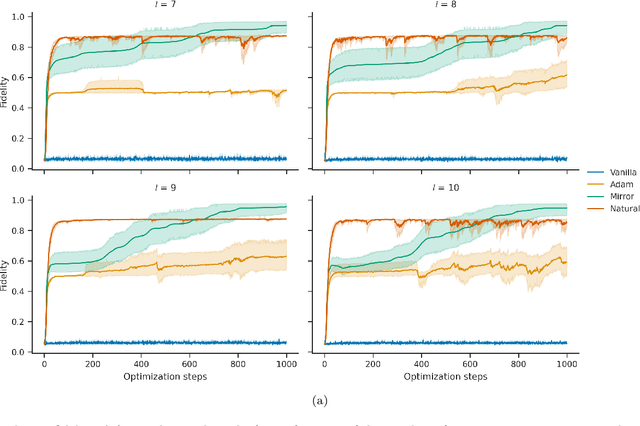
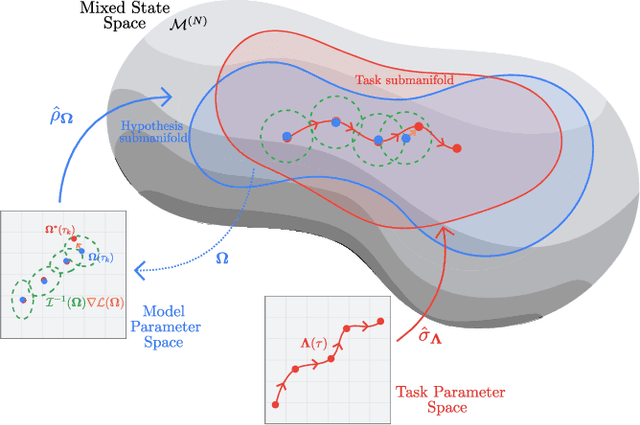
The dual tasks of quantum Hamiltonian learning and quantum Gibbs sampling are relevant to many important problems in physics and chemistry. In the low temperature regime, algorithms for these tasks often suffer from intractabilities, for example from poor sample- or time-complexity. With the aim of addressing such intractabilities, we introduce a generalization of quantum natural gradient descent to parameterized mixed states, as well as provide a robust first-order approximating algorithm, Quantum-Probabilistic Mirror Descent. We prove data sample efficiency for the dual tasks using tools from information geometry and quantum metrology, thus generalizing the seminal result of classical Fisher efficiency to a variational quantum algorithm for the first time. Our approaches extend previously sample-efficient techniques to allow for flexibility in model choice, including to spectrally-decomposed models like Quantum Hamiltonian-Based Models, which may circumvent intractable time complexities. Our first-order algorithm is derived using a novel quantum generalization of the classical mirror descent duality. Both results require a special choice of metric, namely, the Bogoliubov-Kubo-Mori metric. To test our proposed algorithms numerically, we compare their performance to existing baselines on the task of quantum Gibbs sampling for the transverse field Ising model. Finally, we propose an initialization strategy leveraging geometric locality for the modelling of sequences of states such as those arising from quantum-stochastic processes. We demonstrate its effectiveness empirically for both real and imaginary time evolution while defining a broader class of potential applications.
Probabilistic Graphical Models and Tensor Networks: A Hybrid Framework
Jun 29, 2021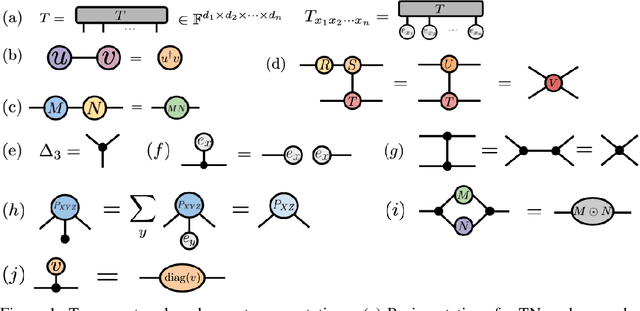
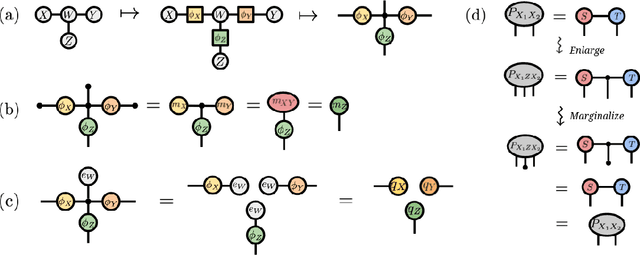
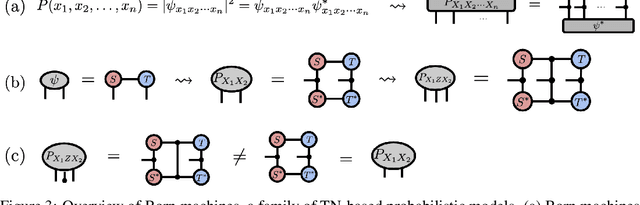
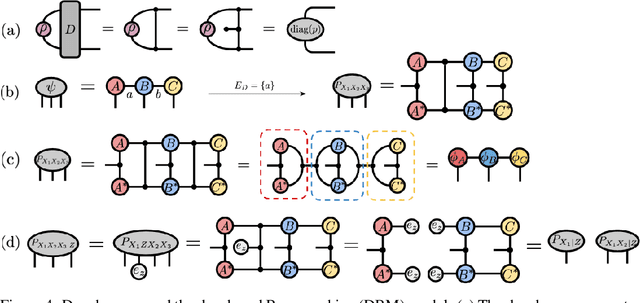
We investigate a correspondence between two formalisms for discrete probabilistic modeling: probabilistic graphical models (PGMs) and tensor networks (TNs), a powerful modeling framework for simulating complex quantum systems. The graphical calculus of PGMs and TNs exhibits many similarities, with discrete undirected graphical models (UGMs) being a special case of TNs. However, more general probabilistic TN models such as Born machines (BMs) employ complex-valued hidden states to produce novel forms of correlation among the probabilities. While representing a new modeling resource for capturing structure in discrete probability distributions, this behavior also renders the direct application of standard PGM tools impossible. We aim to bridge this gap by introducing a hybrid PGM-TN formalism that integrates quantum-like correlations into PGM models in a principled manner, using the physically-motivated concept of decoherence. We first prove that applying decoherence to the entirety of a BM model converts it into a discrete UGM, and conversely, that any subgraph of a discrete UGM can be represented as a decohered BM. This method allows a broad family of probabilistic TN models to be encoded as partially decohered BMs, a fact we leverage to combine the representational strengths of both model families. We experimentally verify the performance of such hybrid models in a sequential modeling task, and identify promising uses of our method within the context of existing applications of graphical models.
On Linear Identifiability of Learned Representations
Jul 08, 2020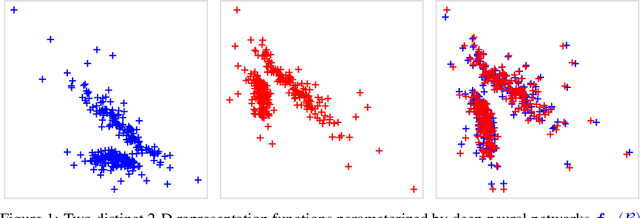
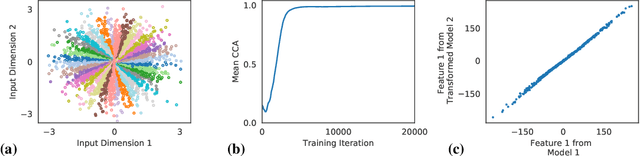
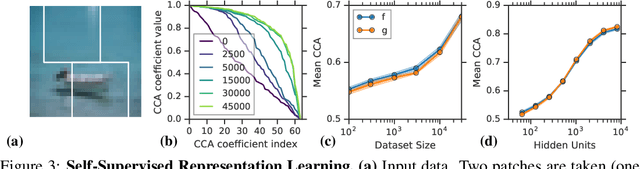
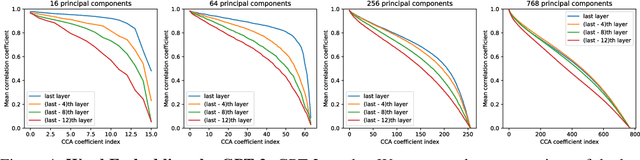
Identifiability is a desirable property of a statistical model: it implies that the true model parameters may be estimated to any desired precision, given sufficient computational resources and data. We study identifiability in the context of representation learning: discovering nonlinear data representations that are optimal with respect to some downstream task. When parameterized as deep neural networks, such representation functions typically lack identifiability in parameter space, because they are overparameterized by design. In this paper, building on recent advances in nonlinear ICA, we aim to rehabilitate identifiability by showing that a large family of discriminative models are in fact identifiable in function space, up to a linear indeterminacy. Many models for representation learning in a wide variety of domains have been identifiable in this sense, including text, images and audio, state-of-the-art at time of publication. We derive sufficient conditions for linear identifiability and provide empirical support for the result on both simulated and real-world data.
Learning Composable Energy Surrogates for PDE Order Reduction
May 15, 2020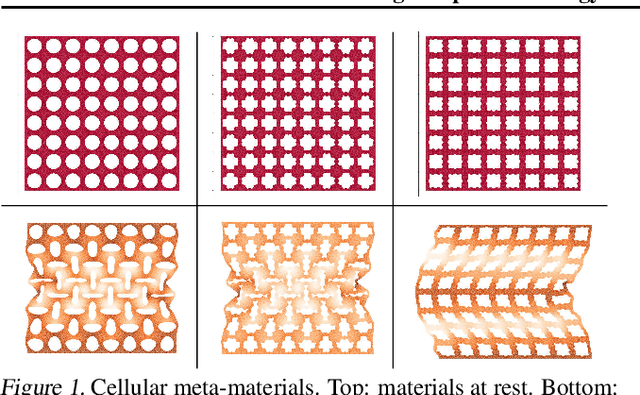
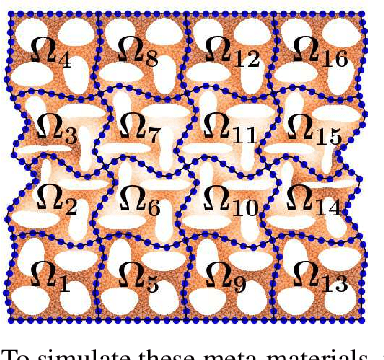
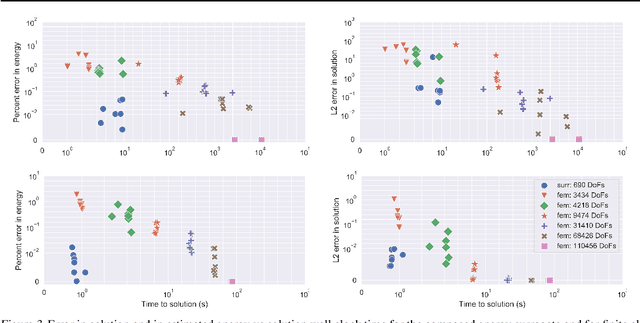
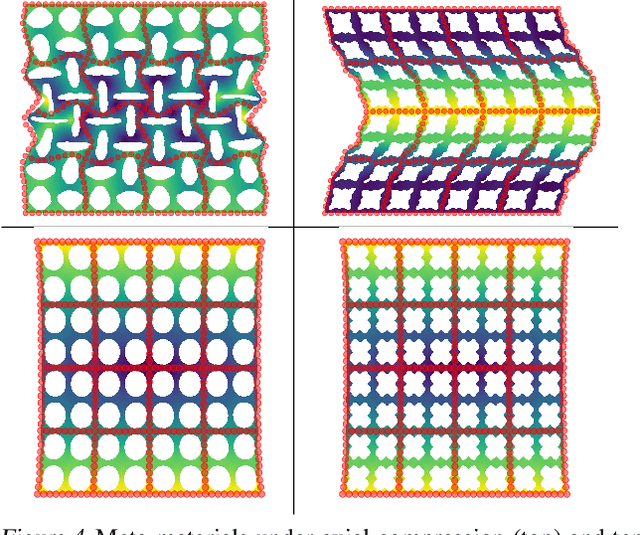
Meta-materials are an important emerging class of engineered materials in which complex macroscopic behaviour--whether electromagnetic, thermal, or mechanical--arises from modular substructure. Simulation and optimization of these materials are computationally challenging, as rich substructures necessitate high-fidelity finite element meshes to solve the governing PDEs. To address this, we leverage parametric modular structure to learn component-level surrogates, enabling cheaper high-fidelity simulation. We use a neural network to model the stored potential energy in a component given boundary conditions. This yields a structured prediction task: macroscopic behavior is determined by the minimizer of the system's total potential energy, which can be approximated by composing these surrogate models. Composable energy surrogates thus permit simulation in the reduced basis of component boundaries. Costly ground-truth simulation of the full structure is avoided, as training data are generated by performing finite element analysis with individual components. Using dataset aggregation to choose training boundary conditions allows us to learn energy surrogates which produce accurate macroscopic behavior when composed, accelerating simulation of parametric meta-materials.
Efficient Amortised Bayesian Inference for Hierarchical and Nonlinear Dynamical Systems
May 28, 2019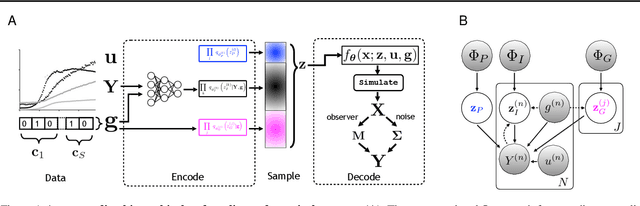

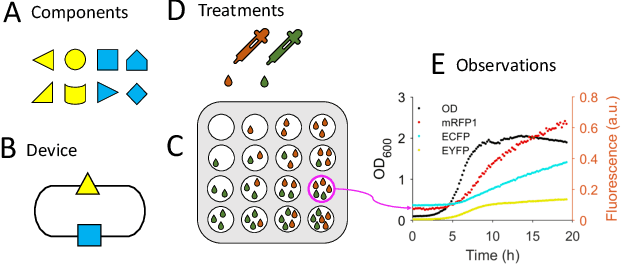
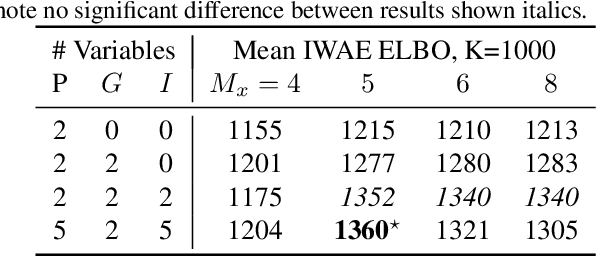
We introduce a flexible, scalable Bayesian inference framework for nonlinear dynamical systems characterised by distinct and hierarchical variability at the individual, group, and population levels. Our model class is a generalisation of nonlinear mixed-effects (NLME) dynamical systems, the statistical workhorse for many experimental sciences. We cast parameter inference as stochastic optimisation of an end-to-end differentiable, block-conditional variational autoencoder. We specify the dynamics of the data-generating process as an ordinary differential equation (ODE) such that both the ODE and its solver are fully differentiable. This model class is highly flexible: the ODE right-hand sides can be a mixture of user-prescribed or "white-box" sub-components and neural network or "black-box" sub-components. Using stochastic optimisation, our amortised inference algorithm could seamlessly scale up to massive data collection pipelines (common in labs with robotic automation). Finally, our framework supports interpretability with respect to the underlying dynamics, as well as predictive generalization to unseen combinations of group components (also called "zero-shot" learning). We empirically validate our method by predicting the dynamic behaviour of bacteria that were genetically engineered to function as biosensors.
Backpropagation through the Void: Optimizing control variates for black-box gradient estimation
Feb 23, 2018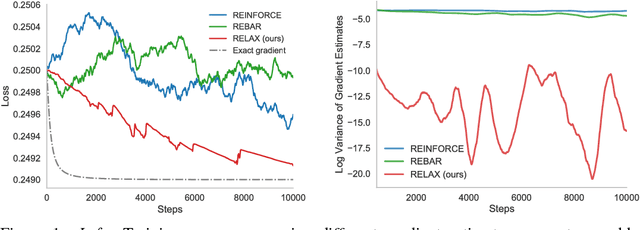
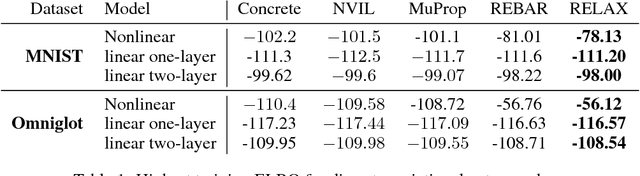
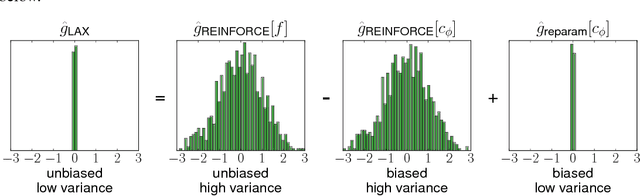

Gradient-based optimization is the foundation of deep learning and reinforcement learning. Even when the mechanism being optimized is unknown or not differentiable, optimization using high-variance or biased gradient estimates is still often the best strategy. We introduce a general framework for learning low-variance, unbiased gradient estimators for black-box functions of random variables. Our method uses gradients of a neural network trained jointly with model parameters or policies, and is applicable in both discrete and continuous settings. We demonstrate this framework for training discrete latent-variable models. We also give an unbiased, action-conditional extension of the advantage actor-critic reinforcement learning algorithm.
Sticking the Landing: Simple, Lower-Variance Gradient Estimators for Variational Inference
May 28, 2017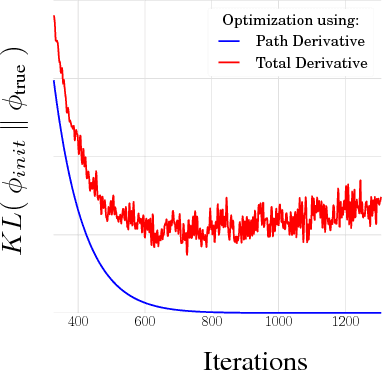
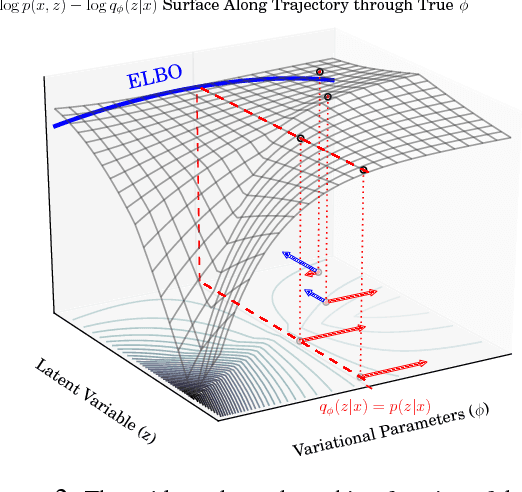
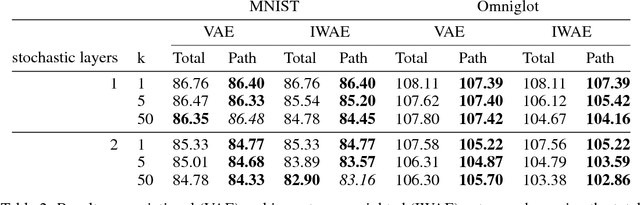
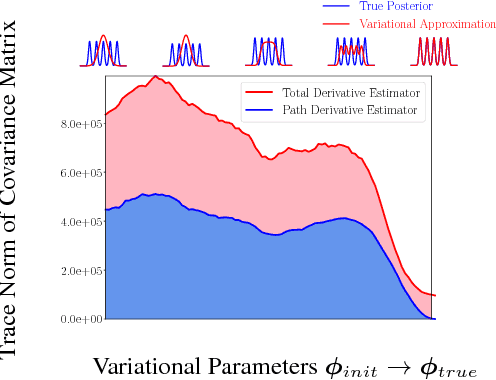
We propose a simple and general variant of the standard reparameterized gradient estimator for the variational evidence lower bound. Specifically, we remove a part of the total derivative with respect to the variational parameters that corresponds to the score function. Removing this term produces an unbiased gradient estimator whose variance approaches zero as the approximate posterior approaches the exact posterior. We analyze the behavior of this gradient estimator theoretically and empirically, and generalize it to more complex variational distributions such as mixtures and importance-weighted posteriors.