 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Expectations: Learning with Stochastic Dominance Made Practical
Feb 05, 2024



Stochastic dominance models risk-averse preferences for decision making with uncertain outcomes, which naturally captures the intrinsic structure of the underlying uncertainty, in contrast to simply resorting to the expectations. Despite theoretically appealing, the application of stochastic dominance in machine learning has been scarce, due to the following challenges: $\textbf{i)}$, the original concept of stochastic dominance only provides a $\textit{partial order}$, therefore, is not amenable to serve as an optimality criterion; and $\textbf{ii)}$, an efficient computational recipe remains lacking due to the continuum nature of evaluating stochastic dominance.%, which barriers its application for machine learning. In this work, we make the first attempt towards establishing a general framework of learning with stochastic dominance. We first generalize the stochastic dominance concept to enable feasible comparisons between any arbitrary pair of random variables. We next develop a simple and computationally efficient approach for finding the optimal solution in terms of stochastic dominance, which can be seamlessly plugged into many learning tasks. Numerical experiments demonstrate that the proposed method achieves comparable performance as standard risk-neutral strategies and obtains better trade-offs against risk across a variety of applications including supervised learning, reinforcement learning, and portfolio optimization.
Communication-Efficient Federated Optimization over Semi-Decentralized Networks
Nov 30, 2023In large-scale federated and decentralized learning, communication efficiency is one of the most challenging bottlenecks. While gossip communication -- where agents can exchange information with their connected neighbors -- is more cost-effective than communicating with the remote server, it often requires a greater number of communication rounds, especially for large and sparse networks. To tackle the trade-off, we examine the communication efficiency under a semi-decentralized communication protocol, in which agents can perform both agent-to-agent and agent-to-server communication in a probabilistic manner. We design a tailored communication-efficient algorithm over semi-decentralized networks, referred to as PISCO, which inherits the robustness to data heterogeneity thanks to gradient tracking and allows multiple local updates for saving communication. We establish the convergence rate of PISCO for nonconvex problems and show that PISCO enjoys a linear speedup in terms of the number of agents and local updates. Our numerical results highlight the superior communication efficiency of PISCO and its resilience to data heterogeneity and various network topologies.
Federated Natural Policy Gradient Methods for Multi-task Reinforcement Learning
Nov 01, 2023Federated reinforcement learning (RL) enables collaborative decision making of multiple distributed agents without sharing local data trajectories. In this work, we consider a multi-task setting, in which each agent has its own private reward function corresponding to different tasks, while sharing the same transition kernel of the environment. Focusing on infinite-horizon tabular Markov decision processes, the goal is to learn a globally optimal policy that maximizes the sum of the discounted total rewards of all the agents in a decentralized manner, where each agent only communicates with its neighbors over some prescribed graph topology. We develop federated vanilla and entropy-regularized natural policy gradient (NPG) methods under softmax parameterization, where gradient tracking is applied to the global Q-function to mitigate the impact of imperfect information sharing. We establish non-asymptotic global convergence guarantees under exact policy evaluation, which are nearly independent of the size of the state-action space and illuminate the impacts of network size and connectivity. To the best of our knowledge, this is the first time that global convergence is established for federated multi-task RL using policy optimization. Moreover, the convergence behavior of the proposed algorithms is robust against inexactness of policy evaluation.
Escaping Saddle Points in Heterogeneous Federated Learning via Distributed SGD with Communication Compression
Oct 29, 2023


We consider the problem of finding second-order stationary points of heterogeneous federated learning (FL). Previous works in FL mostly focus on first-order convergence guarantees, which do not rule out the scenario of unstable saddle points. Meanwhile, it is a key bottleneck of FL to achieve communication efficiency without compensating the learning accuracy, especially when local data are highly heterogeneous across different clients. Given this, we propose a novel algorithm Power-EF that only communicates compressed information via a novel error-feedback scheme. To our knowledge, Power-EF is the first distributed and compressed SGD algorithm that provably escapes saddle points in heterogeneous FL without any data homogeneity assumptions. In particular, Power-EF improves to second-order stationary points after visiting first-order (possibly saddle) points, using additional gradient queries and communication rounds only of almost the same order required by first-order convergence, and the convergence rate exhibits a linear speedup in terms of the number of workers. Our theory improves/recovers previous results, while extending to much more tolerant settings on the local data. Numerical experiments are provided to complement the theory.
Provably Accelerating Ill-Conditioned Low-rank Estimation via Scaled Gradient Descent, Even with Overparameterization
Oct 09, 2023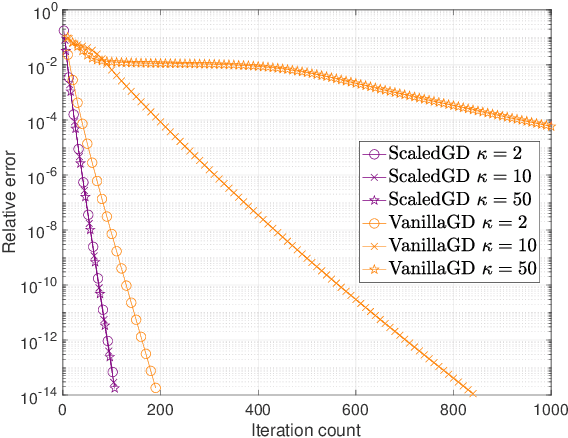
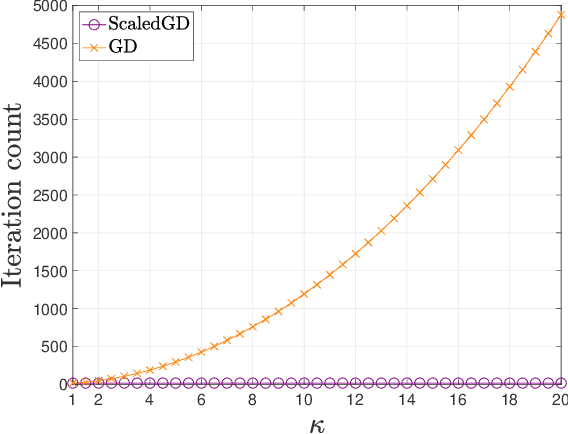
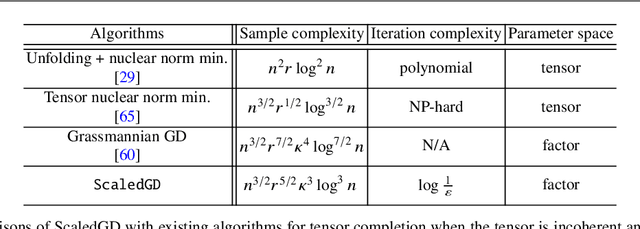
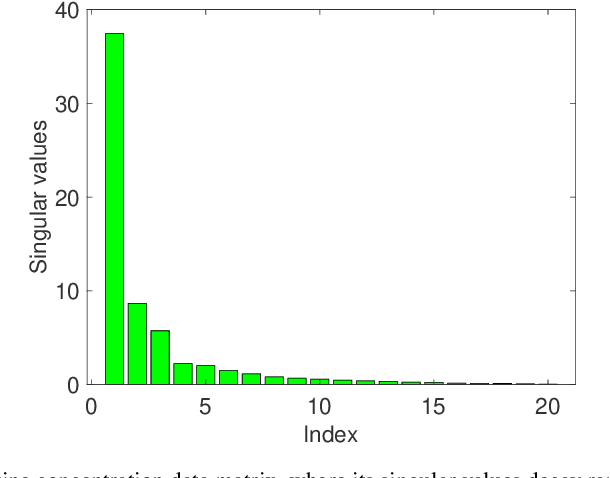
Many problems encountered in science and engineering can be formulated as estimating a low-rank object (e.g., matrices and tensors) from incomplete, and possibly corrupted, linear measurements. Through the lens of matrix and tensor factorization, one of the most popular approaches is to employ simple iterative algorithms such as gradient descent (GD) to recover the low-rank factors directly, which allow for small memory and computation footprints. However, the convergence rate of GD depends linearly, and sometimes even quadratically, on the condition number of the low-rank object, and therefore, GD slows down painstakingly when the problem is ill-conditioned. This chapter introduces a new algorithmic approach, dubbed scaled gradient descent (ScaledGD), that provably converges linearly at a constant rate independent of the condition number of the low-rank object, while maintaining the low per-iteration cost of gradient descent for a variety of tasks including sensing, robust principal component analysis and completion. In addition, ScaledGD continues to admit fast global convergence to the minimax-optimal solution, again almost independent of the condition number, from a small random initialization when the rank is over-specified in the presence of Gaussian noise. In total, ScaledGD highlights the power of appropriate preconditioning in accelerating nonconvex statistical estimation, where the iteration-varying preconditioners promote desirable invariance properties of the trajectory with respect to the symmetry in low-rank factorization without hurting generalization.
Global Convergence of Policy Gradient Methods in Reinforcement Learning, Games and Control
Oct 08, 2023

Policy gradient methods, where one searches for the policy of interest by maximizing the value functions using first-order information, become increasingly popular for sequential decision making in reinforcement learning, games, and control. Guaranteeing the global optimality of policy gradient methods, however, is highly nontrivial due to nonconcavity of the value functions. In this exposition, we highlight recent progresses in understanding and developing policy gradient methods with global convergence guarantees, putting an emphasis on their finite-time convergence rates with regard to salient problem parameters.
A Multi-Token Coordinate Descent Method for Semi-Decentralized Vertical Federated Learning
Sep 18, 2023Communication efficiency is a major challenge in federated learning (FL). In client-server schemes, the server constitutes a bottleneck, and while decentralized setups spread communications, they do not necessarily reduce them due to slower convergence. We propose Multi-Token Coordinate Descent (MTCD), a communication-efficient algorithm for semi-decentralized vertical federated learning, exploiting both client-server and client-client communications when each client holds a small subset of features. Our multi-token method can be seen as a parallel Markov chain (block) coordinate descent algorithm and it subsumes the client-server and decentralized setups as special cases. We obtain a convergence rate of $\mathcal{O}(1/T)$ for nonconvex objectives when tokens roam over disjoint subsets of clients and for convex objectives when they roam over possibly overlapping subsets. Numerical results show that MTCD improves the state-of-the-art communication efficiency and allows for a tunable amount of parallel communications.
A Lightweight Transformer for Faster and Robust EBSD Data Collection
Aug 18, 2023Three dimensional electron back-scattered diffraction (EBSD) microscopy is a critical tool in many applications in materials science, yet its data quality can fluctuate greatly during the arduous collection process, particularly via serial-sectioning. Fortunately, 3D EBSD data is inherently sequential, opening up the opportunity to use transformers, state-of-the-art deep learning architectures that have made breakthroughs in a plethora of domains, for data processing and recovery. To be more robust to errors and accelerate this 3D EBSD data collection, we introduce a two step method that recovers missing slices in an 3D EBSD volume, using an efficient transformer model and a projection algorithm to process the transformer's outputs. Overcoming the computational and practical hurdles of deep learning with scarce high dimensional data, we train this model using only synthetic 3D EBSD data with self-supervision and obtain superior recovery accuracy on real 3D EBSD data, compared to existing methods.
Offline Reinforcement Learning with On-Policy Q-Function Regularization
Jul 25, 2023



The core challenge of offline reinforcement learning (RL) is dealing with the (potentially catastrophic) extrapolation error induced by the distribution shift between the history dataset and the desired policy. A large portion of prior work tackles this challenge by implicitly/explicitly regularizing the learning policy towards the behavior policy, which is hard to estimate reliably in practice. In this work, we propose to regularize towards the Q-function of the behavior policy instead of the behavior policy itself, under the premise that the Q-function can be estimated more reliably and easily by a SARSA-style estimate and handles the extrapolation error more straightforwardly. We propose two algorithms taking advantage of the estimated Q-function through regularizations, and demonstrate they exhibit strong performance on the D4RL benchmarks.
Seeing is not Believing: Robust Reinforcement Learning against Spurious Correlation
Jul 15, 2023Robustness has been extensively studied in reinforcement learning (RL) to handle various forms of uncertainty such as random perturbations, rare events, and malicious attacks. In this work, we consider one critical type of robustness against spurious correlation, where different portions of the state do not have causality but have correlations induced by unobserved confounders. These spurious correlations are ubiquitous in real-world tasks, for instance, a self-driving car usually observes heavy traffic in the daytime and light traffic at night due to unobservable human activity. A model that learns such useless or even harmful correlation could catastrophically fail when the confounder in the test case deviates from the training one. Although motivated, enabling robustness against spurious correlation poses significant challenges since the uncertainty set, shaped by the unobserved confounder and sequential structure of RL, is difficult to characterize and identify. Existing robust algorithms that assume simple and unstructured uncertainty sets are therefore inadequate to address this challenge. To solve this issue, we propose Robust State-Confounded Markov Decision Processes (RSC-MDPs) and theoretically demonstrate its superiority in breaking spurious correlations compared with other robust RL counterparts. We also design an empirical algorithm to learn the robust optimal policy for RSC-MDPs, which outperforms all baselines in eight realistic self-driving and manipulation tasks.