 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Task Decomposition with Ordered Memory Policy Network
Mar 19, 2021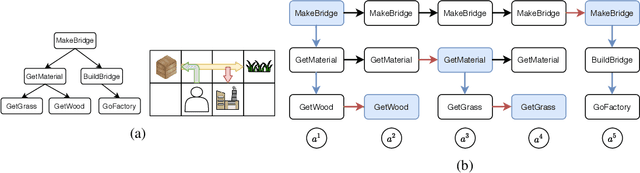
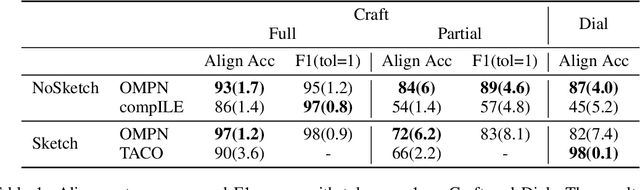
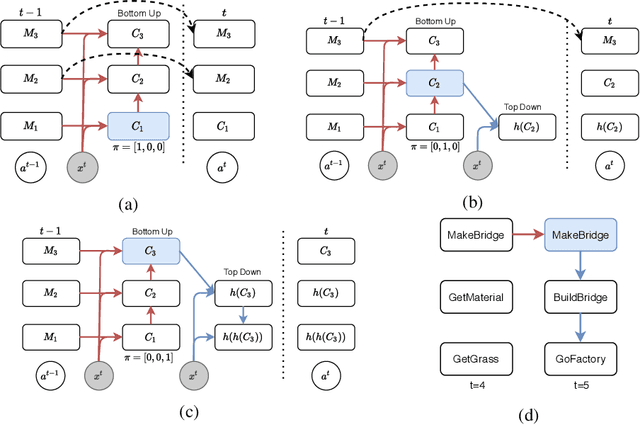
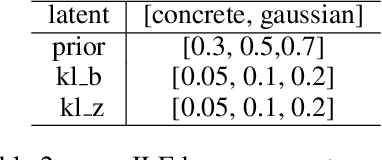
Many complex real-world tasks are composed of several levels of sub-tasks. Humans leverage these hierarchical structures to accelerate the learning process and achieve better generalization. In this work, we study the inductive bias and propose Ordered Memory Policy Network (OMPN) to discover subtask hierarchy by learning from demonstration. The discovered subtask hierarchy could be used to perform task decomposition, recovering the subtask boundaries in an unstruc-tured demonstration. Experiments on Craft and Dial demonstrate that our modelcan achieve higher task decomposition performance under both unsupervised and weakly supervised settings, comparing with strong baselines. OMPN can also bedirectly applied to partially observable environments and still achieve higher task decomposition performance. Our visualization further confirms that the subtask hierarchy can emerge in our model.
Supervised Seeded Iterated Learning for Interactive Language Learning
Oct 06, 2020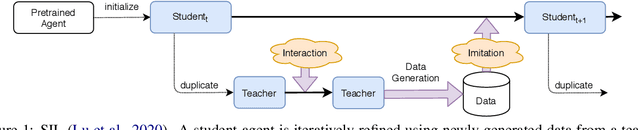
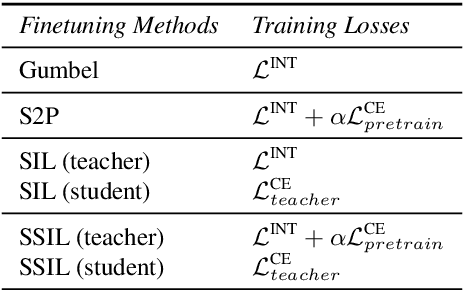
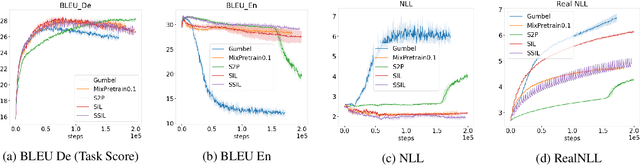
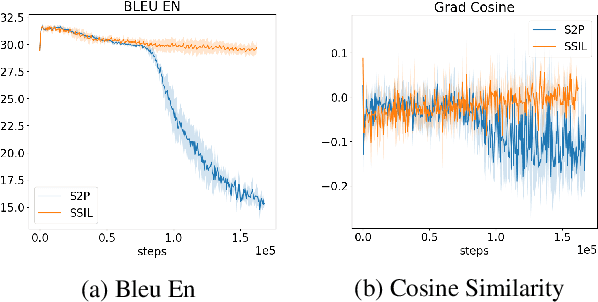
Language drift has been one of the major obstacles to train language models through interaction. When word-based conversational agents are trained towards completing a task, they tend to invent their language rather than leveraging natural language. In recent literature, two general methods partially counter this phenomenon: Supervised Selfplay (S2P) and Seeded Iterated Learning (SIL). While S2P jointly trains interactive and supervised losses to counter the drift, SIL changes the training dynamics to prevent language drift from occurring. In this paper, we first highlight their respective weaknesses, i.e., late-stage training collapses and higher negative likelihood when evaluated on human corpus. Given these observations, we introduce Supervised Seeded Iterated Learning to combine both methods to minimize their respective weaknesses. We then show the effectiveness of \algo in the language-drift translation game.
Countering Language Drift with Seeded Iterated Learning
Apr 06, 2020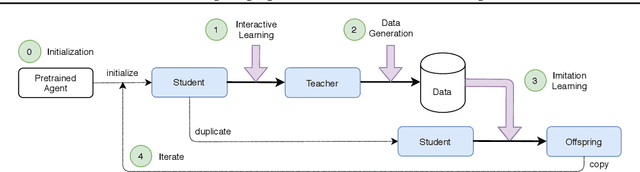

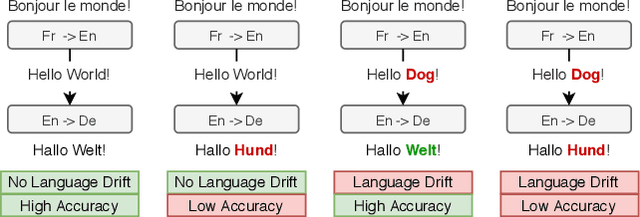
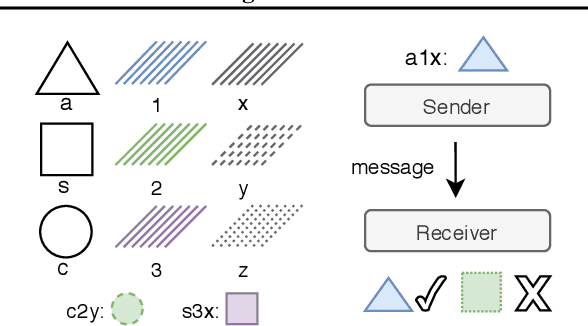
Supervised learning methods excel at capturing statistical properties of language when trained over large text corpora. Yet, these models often produce inconsistent outputs in goal-oriented language settings as they are not trained to complete the underlying task. Moreover, as soon as the agents are finetuned to maximize task completion, they suffer from the so-called language drift phenomenon: they slowly lose syntactic and semantic properties of language as they only focus on solving the task. In this paper, we propose a generic approach to counter language drift by using iterated learning. We iterate between fine-tuning agents with interactive training steps, and periodically replacing them with new agents that are seeded from last iteration and trained to imitate the latest finetuned models. Iterated learning does not require external syntactic constraint nor semantic knowledge, making it a valuable task-agnostic finetuning protocol. We first explore iterated learning in the Lewis Game. We then scale-up the approach in the translation game. In both settings, our results show that iterated learn-ing drastically counters language drift as well as it improves the task completion metric.
Out-of-Distribution Detection for Skin Lesion Images with Deep Isolation Forest
Mar 20, 2020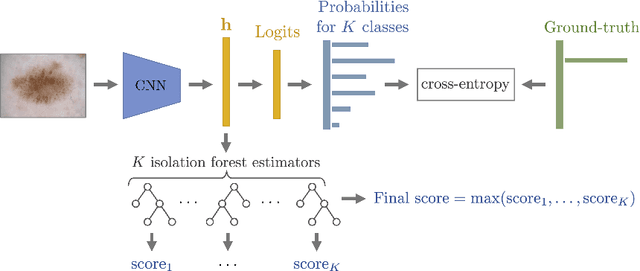
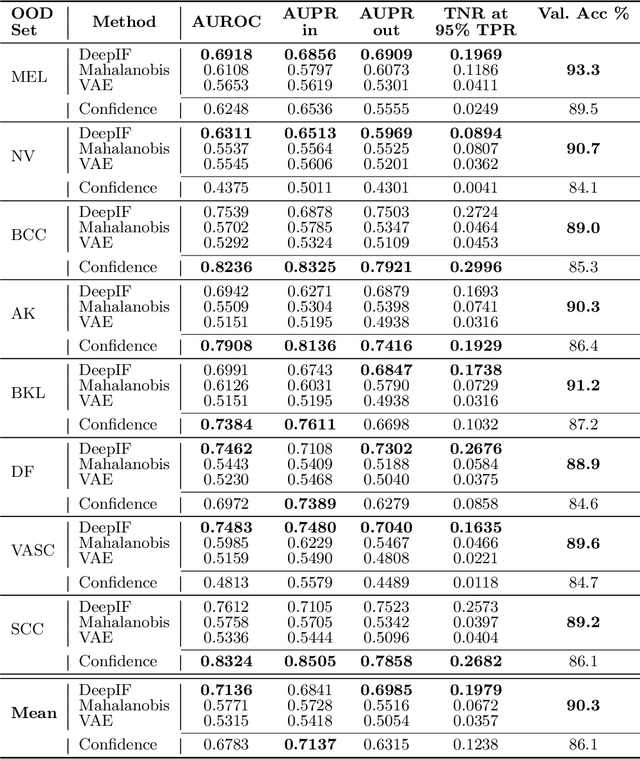
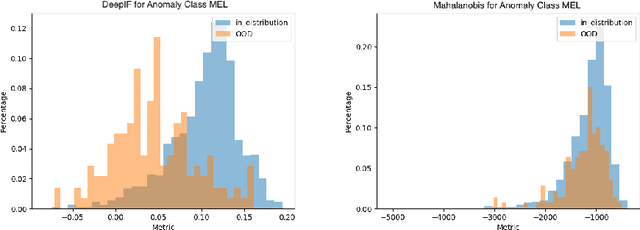
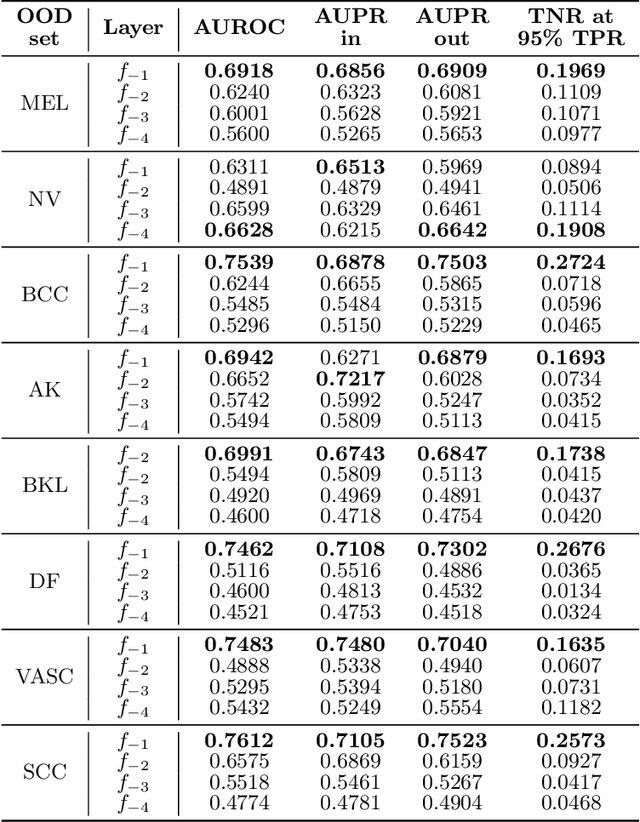
In this paper, we study the problem of out-of-distribution detection in skin disease images. Publicly available medical datasets normally have a limited number of lesion classes (e.g. HAM10000 has 8 lesion classes). However, there exists a few thousands of clinically identified diseases. Hence, it is important if lesions not in the training data can be differentiated. Toward this goal, we propose DeepIF, a non-parametric Isolation Forest based approach combined with deep convolutional networks. We conduct comprehensive experiments to compare our DeepIF with three baseline models. Results demonstrate state-of-the-art performance of our proposed approach on the task of detecting abnormal skin lesions.
Boosting Image Recognition with Non-differentiable Constraints
Oct 02, 2019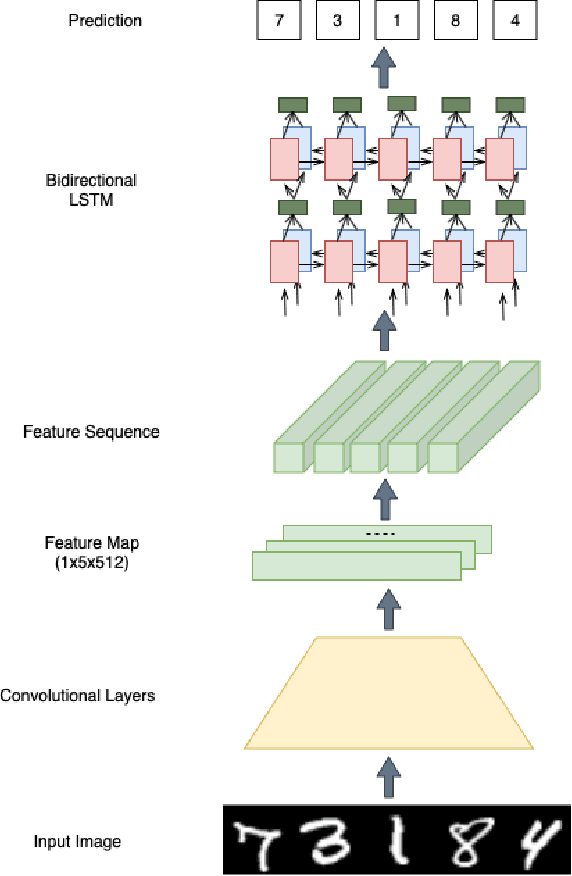
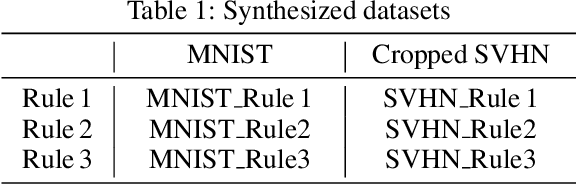

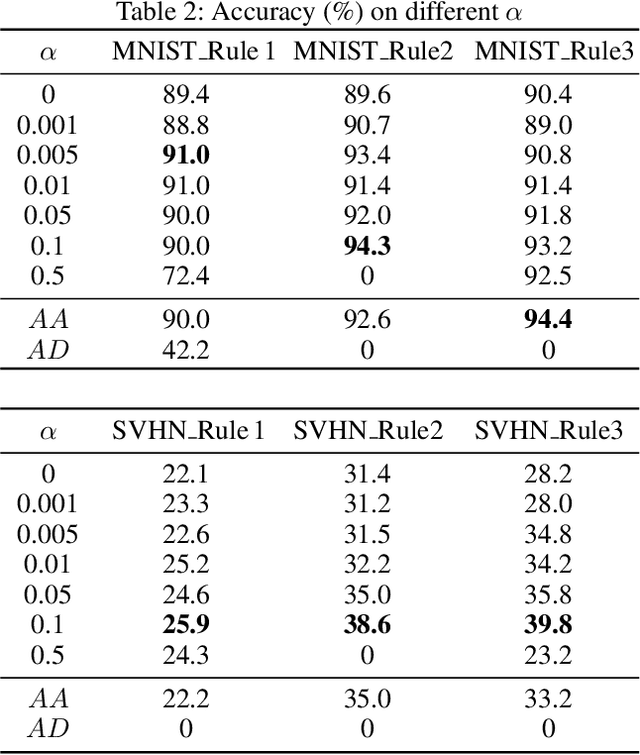
In this paper, we study the problem of image recognition with non-differentiable constraints. A lot of real-life recognition applications require a rich output structure with deterministic constraints that are discrete or modeled by a non-differentiable function. A prime example is recognizing digit sequences, which are restricted by such rules (e.g., \textit{container code detection}, \textit{social insurance number recognition}, etc.). We investigate the usefulness of adding non-differentiable constraints in learning for the task of digit sequence recognition. Toward this goal, we synthesize six different datasets from MNIST and Cropped SVHN, with three discrete rules inspired by real-life protocols. To deal with the non-differentiability of these rules, we propose a reinforcement learning approach based on the policy gradient method. We find that incorporating this rule-based reinforcement can effectively increase the accuracy for all datasets and provide a good inductive bias which improves the model even with limited data. On one of the datasets, MNIST\_Rule2, models trained with rule-based reinforcement increase the accuracy by 4.7\% for 2000 samples and 23.6\% for 500 samples. We further test our model against synthesized adversarial examples, e.g., blocking out digits, and observe that adding our rule-based reinforcement increases the model robustness with a relatively smaller performance drop.
No Press Diplomacy: Modeling Multi-Agent Gameplay
Sep 04, 2019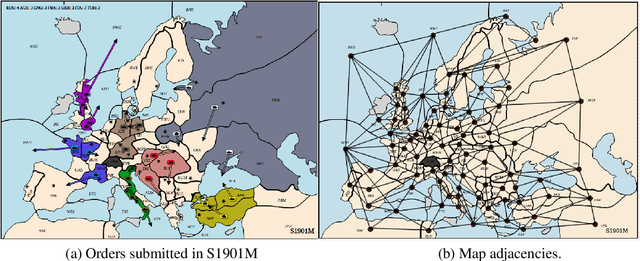
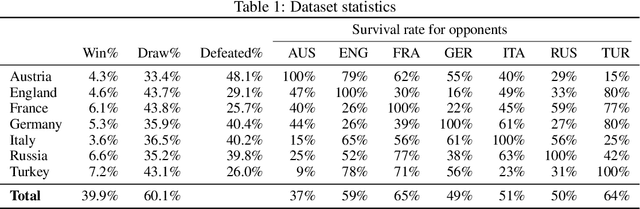
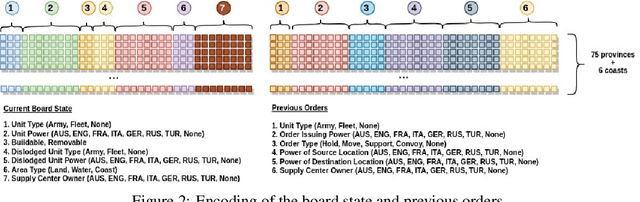
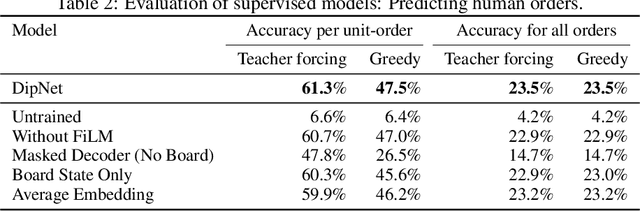
Diplomacy is a seven-player non-stochastic, non-cooperative game, where agents acquire resources through a mix of teamwork and betrayal. Reliance on trust and coordination makes Diplomacy the first non-cooperative multi-agent benchmark for complex sequential social dilemmas in a rich environment. In this work, we focus on training an agent that learns to play the No Press version of Diplomacy where there is no dedicated communication channel between players. We present DipNet, a neural-network-based policy model for No Press Diplomacy. The model was trained on a new dataset of more than 150,000 human games. Our model is trained by supervised learning (SL) from expert trajectories, which is then used to initialize a reinforcement learning (RL) agent trained through self-play. Both the SL and RL agents demonstrate state-of-the-art No Press performance by beating popular rule-based bots.
Anomaly Detection for Skin Disease Images Using Variational Autoencoder
Jul 24, 2018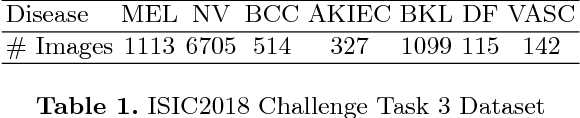
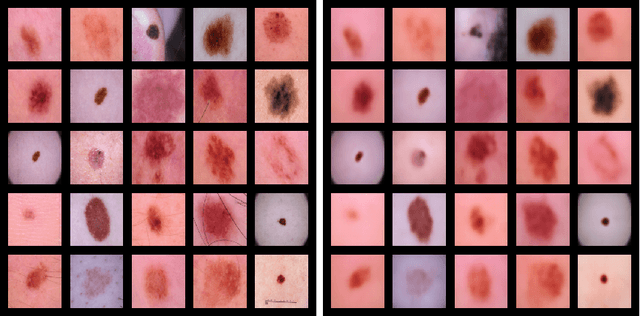
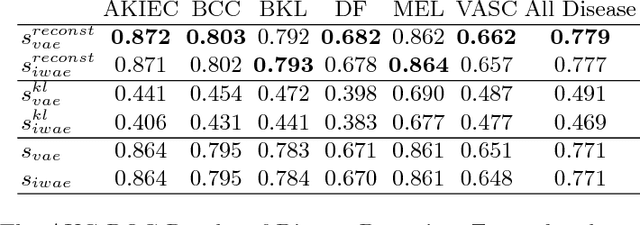
In this paper, we demonstrate the potential of applying Variational Autoencoder (VAE) [10] for anomaly detection in skin disease images. VAE is a class of deep generative models which is trained by maximizing the evidence lower bound of data distribution [10]. When trained on only normal data, the resulting model is able to perform efficient inference and to determine if a test image is normal or not. We perform experiments on ISIC2018 Challenge Disease Classification dataset (Task 3) and compare different methods to use VAE to detect anomaly. The model is able to detect all diseases with 0.779 AUCROC. If we focus on specific diseases, the model is able to detect melanoma with 0.864 AUCROC and detect actinic keratosis with 0.872 AUCROC, even if it only sees the images of nevus. To the best of our knowledge, this is the first applied work of deep generative models for anomaly detection in dermatology.