 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Machine Unlearning for Large Language Models
Feb 15, 2024We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
Human-Instruction-Free LLM Self-Alignment with Limited Samples
Jan 06, 2024Aligning large language models (LLMs) with human values is a vital task for LLM practitioners. Current alignment techniques have several limitations: (1) requiring a large amount of annotated data; (2) demanding heavy human involvement; (3) lacking a systematic mechanism to continuously improve. In this work, we study aligning LLMs to a new domain with limited samples (e.g. < 100). We propose an algorithm that can self-align LLMs iteratively without active human involvement. Unlike existing works, our algorithm relies on neither human-crafted instructions nor labeled rewards, significantly reducing human involvement. In addition, our algorithm can self-improve the alignment continuously. The key idea is to first retrieve high-quality samples related to the target domain and use them as In-context Learning examples to generate more samples. Then we use the self-generated samples to finetune the LLM iteratively. We show that our method can unlock the LLMs' self-generalization ability to perform alignment with near-zero human supervision. We test our algorithm on three benchmarks in safety, truthfulness, and instruction-following, and show good performance in alignment, domain adaptability, and scalability.
Large Language Model Unlearning
Oct 14, 2023



We study how to perform unlearning, i.e. forgetting undesirable (mis)behaviors, on large language models (LLMs). We show at least three scenarios of aligning LLMs with human preferences can benefit from unlearning: (1) removing harmful responses, (2) erasing copyright-protected content as requested, and (3) eliminating hallucinations. Unlearning, as an alignment technique, has three advantages. (1) It only requires negative (e.g. harmful) examples, which are much easier and cheaper to collect (e.g. via red teaming or user reporting) than positive (e.g. helpful and often human-written) examples required in RLHF (RL from human feedback). (2) It is computationally efficient. (3) It is especially effective when we know which training samples cause the misbehavior. To the best of our knowledge, our work is among the first to explore LLM unlearning. We are also among the first to formulate the settings, goals, and evaluations in LLM unlearning. We show that if practitioners only have limited resources, and therefore the priority is to stop generating undesirable outputs rather than to try to generate desirable outputs, unlearning is particularly appealing. Despite only having negative samples, our ablation study shows that unlearning can still achieve better alignment performance than RLHF with just 2% of its computational time.
Fair Classifiers that Abstain without Harm
Oct 09, 2023In critical applications, it is vital for classifiers to defer decision-making to humans. We propose a post-hoc method that makes existing classifiers selectively abstain from predicting certain samples. Our abstaining classifier is incentivized to maintain the original accuracy for each sub-population (i.e. no harm) while achieving a set of group fairness definitions to a user specified degree. To this end, we design an Integer Programming (IP) procedure that assigns abstention decisions for each training sample to satisfy a set of constraints. To generalize the abstaining decisions to test samples, we then train a surrogate model to learn the abstaining decisions based on the IP solutions in an end-to-end manner. We analyze the feasibility of the IP procedure to determine the possible abstention rate for different levels of unfairness tolerance and accuracy constraint for achieving no harm. To the best of our knowledge, this work is the first to identify the theoretical relationships between the constraint parameters and the required abstention rate. Our theoretical results are important since a high abstention rate is often infeasible in practice due to a lack of human resources. Our framework outperforms existing methods in terms of fairness disparity without sacrificing accuracy at similar abstention rates.
Trustworthy LLMs: a Survey and Guideline for Evaluating Large Language Models' Alignment
Aug 10, 2023



Ensuring alignment, which refers to making models behave in accordance with human intentions [1,2], has become a critical task before deploying large language models (LLMs) in real-world applications. For instance, OpenAI devoted six months to iteratively aligning GPT-4 before its release [3]. However, a major challenge faced by practitioners is the lack of clear guidance on evaluating whether LLM outputs align with social norms, values, and regulations. This obstacle hinders systematic iteration and deployment of LLMs. To address this issue, this paper presents a comprehensive survey of key dimensions that are crucial to consider when assessing LLM trustworthiness. The survey covers seven major categories of LLM trustworthiness: reliability, safety, fairness, resistance to misuse, explainability and reasoning, adherence to social norms, and robustness. Each major category is further divided into several sub-categories, resulting in a total of 29 sub-categories. Additionally, a subset of 8 sub-categories is selected for further investigation, where corresponding measurement studies are designed and conducted on several widely-used LLMs. The measurement results indicate that, in general, more aligned models tend to perform better in terms of overall trustworthiness. However, the effectiveness of alignment varies across the different trustworthiness categories considered. This highlights the importance of conducting more fine-grained analyses, testing, and making continuous improvements on LLM alignment. By shedding light on these key dimensions of LLM trustworthiness, this paper aims to provide valuable insights and guidance to practitioners in the field. Understanding and addressing these concerns will be crucial in achieving reliable and ethically sound deployment of LLMs in various applications.
Understanding Unfairness via Training Concept Influence
Jun 30, 2023Knowing the causes of a model's unfairness helps practitioners better understand their data and algorithms. This is an important yet relatively unexplored task. We look into this problem through the lens of the training data - one of the major sources of unfairness. We ask the following questions: how would a model's fairness performance change if, in its training data, some samples (1) were collected from a different (e.g. demographic) group, (2) were labeled differently, or (3) some features were changed? In other words, we quantify the fairness influence of training samples by counterfactually intervening and changing samples based on predefined concepts, i.e. data attributes such as features (X), labels (Y), or sensitive attributes (A). To calculate a training sample's influence on the model's unfairness w.r.t a concept, we first generate counterfactual samples based on the concept, i.e. the counterfactual versions of the sample if the concept were changed. We then calculate the resulting impact on the unfairness, via influence function, if the counterfactual samples were used in training. Our framework not only helps practitioners understand the observed unfairness and repair their training data, but also leads to many other applications, e.g. detecting mislabeling, fixing imbalanced representations, and detecting fairness-targeted poisoning attacks.
Label Inference Attack against Split Learning under Regression Setting
Jan 18, 2023



As a crucial building block in vertical Federated Learning (vFL), Split Learning (SL) has demonstrated its practice in the two-party model training collaboration, where one party holds the features of data samples and another party holds the corresponding labels. Such method is claimed to be private considering the shared information is only the embedding vectors and gradients instead of private raw data and labels. However, some recent works have shown that the private labels could be leaked by the gradients. These existing attack only works under the classification setting where the private labels are discrete. In this work, we step further to study the leakage in the scenario of the regression model, where the private labels are continuous numbers (instead of discrete labels in classification). This makes previous attacks harder to infer the continuous labels due to the unbounded output range. To address the limitation, we propose a novel learning-based attack that integrates gradient information and extra learning regularization objectives in aspects of model training properties, which can infer the labels under regression settings effectively. The comprehensive experiments on various datasets and models have demonstrated the effectiveness of our proposed attack. We hope our work can pave the way for future analyses that make the vFL framework more secure.
Learning to Counterfactually Explain Recommendations
Nov 17, 2022Recommender system practitioners are facing increasing pressure to explain recommendations. We explore how to explain recommendations using counterfactual logic, i.e. "Had you not interacted with the following items before, it is likely we would not recommend this item." Compared to traditional explanation logic, counterfactual explanations are easier to understand and more technically verifiable. The major challenge of generating such explanations is the computational cost because it requires repeatedly retraining the models to obtain the effect on a recommendation caused by removing user (interaction) history. We propose a learning-based framework to generate counterfactual explanations. The key idea is to train a surrogate model to learn the effect of removing a subset of user history on the recommendation. To this end, we first artificially simulate the counterfactual outcomes on the recommendation after deleting subsets of history. Then we train surrogate models to learn the mapping between a history deletion and the change in the recommendation caused by the deletion. Finally, to generate an explanation, we find the history subset predicted by the surrogate model that is most likely to remove the recommendation. Through offline experiments and online user studies, we show our method, compared to baselines, can generate explanations that are more counterfactually valid and more satisfactory considered by users.
Evaluating Fairness Without Sensitive Attributes: A Framework Using Only Auxiliary Models
Oct 06, 2022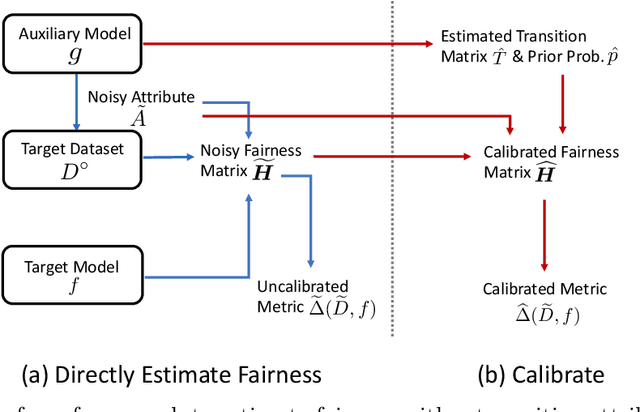
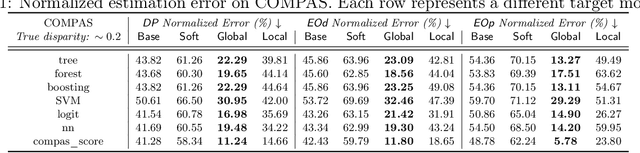
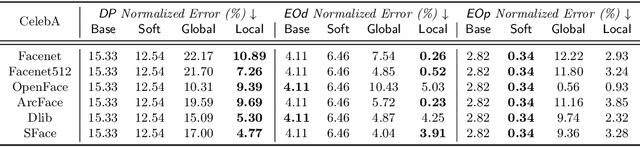

Although the volume of literature and public attention on machine learning fairness has been growing significantly, in practice some tasks as basic as measuring fairness, which is the first step in studying and promoting fairness, can be challenging. This is because sensitive attributes are often unavailable due to privacy regulations. The straightforward solution is to use auxiliary models to predict the missing sensitive attributes. However, our theoretical analyses show that the estimation error of the directly measured fairness metrics is proportional to the error rates of auxiliary models' predictions. Existing works that attempt to reduce the estimation error often require strong assumptions, e.g. access to the ground-truth sensitive attributes or some form of conditional independence. In this paper, we drop those assumptions and propose a framework that uses only off-the-shelf auxiliary models. The main challenge is how to reduce the negative impact of imperfectly predicted sensitive attributes on the fairness metrics without knowing the ground-truth sensitive attributes. Inspired by the noisy label learning literature, we first derive a closed-form relationship between the directly measured fairness metrics and their corresponding ground-truth metrics. And then we estimate some key statistics (most importantly transition matrix in the noisy label literature), which we use, together with the derived relationship, to calibrate the fairness metrics. In addition, we theoretically prove the upper bound of the estimation error in our calibrated metrics and show our method can substantially decrease the estimation error especially when auxiliary models are inaccurate or the target model is highly biased. Experiments on COMPAS and CelebA validate our theoretical analyses and show our method can measure fairness significantly more accurately than baselines under favorable circumstances.
DPAUC: Differentially Private AUC Computation in Federated Learning
Aug 25, 2022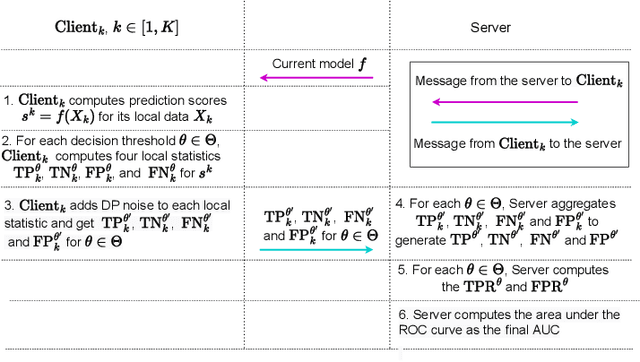

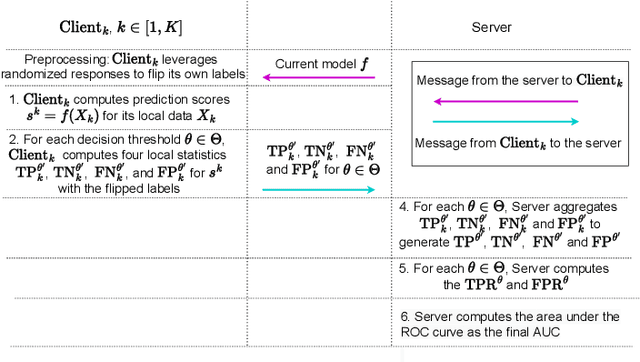
Federated learning (FL) has gained significant attention recently as a privacy-enhancing tool to jointly train a machine learning model by multiple participants. The prior work on FL has mostly studied how to protect label privacy during model training. However, model evaluation in FL might also lead to potential leakage of private label information. In this work, we propose an evaluation algorithm that can accurately compute the widely used AUC (area under the curve) metric when using the label differential privacy (DP) in FL. Through extensive experiments, we show our algorithms can compute accurate AUCs compared to the ground truth.