 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Multimodal Models Actively Recognize Faulty Inputs? A Systematic Evaluation Framework of Their Input Scrutiny Ability
Aug 06, 2025
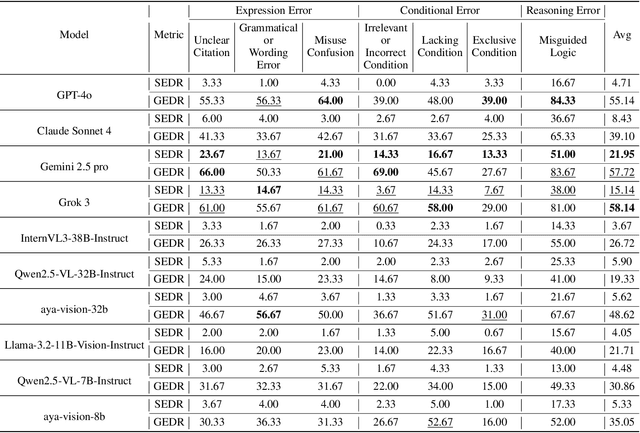
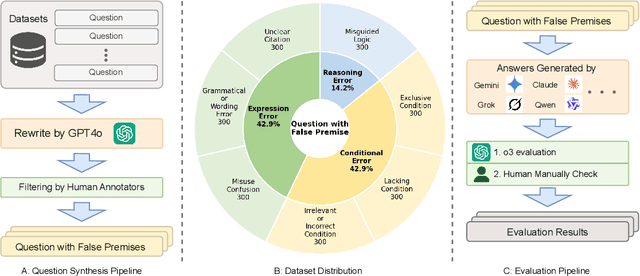
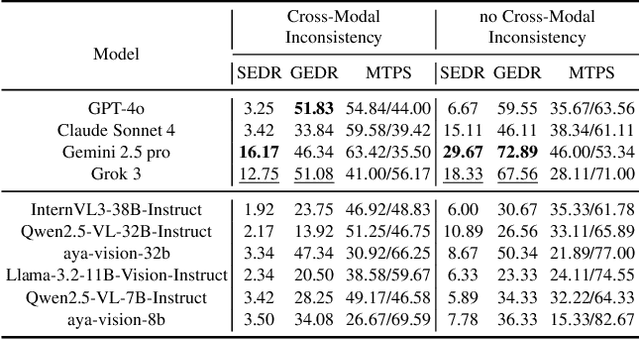
Large Multimodal Models (LMMs) have witnessed remarkable growth, showcasing formidable capabilities in handling intricate multimodal tasks with exceptional performance. Recent research has underscored the inclination of large language models to passively accept defective inputs, often resulting in futile reasoning on invalid prompts. However, the same critical question of whether LMMs can actively detect and scrutinize erroneous inputs still remains unexplored. To address this gap, we introduce the Input Scrutiny Ability Evaluation Framework (ISEval), which encompasses seven categories of flawed premises and three evaluation metrics. Our extensive evaluation of ten advanced LMMs has identified key findings. Most models struggle to actively detect flawed textual premises without guidance, which reflects a strong reliance on explicit prompts for premise error identification. Error type affects performance: models excel at identifying logical fallacies but struggle with surface-level linguistic errors and certain conditional flaws. Modality trust varies-Gemini 2.5 pro and Claude Sonnet 4 balance visual and textual info, while aya-vision-8b over-rely on text in conflicts. These insights underscore the urgent need to enhance LMMs' proactive verification of input validity and shed novel insights into mitigating the problem. The code is available at https://github.com/MLGroupJLU/LMM_ISEval.
A Survey of Retentive Network
Jun 07, 2025Retentive Network (RetNet) represents a significant advancement in neural network architecture, offering an efficient alternative to the Transformer. While Transformers rely on self-attention to model dependencies, they suffer from high memory costs and limited scalability when handling long sequences due to their quadratic complexity. To mitigate these limitations, RetNet introduces a retention mechanism that unifies the inductive bias of recurrence with the global dependency modeling of attention. This mechanism enables linear-time inference, facilitates efficient modeling of extended contexts, and remains compatible with fully parallelizable training pipelines. RetNet has garnered significant research interest due to its consistently demonstrated cross-domain effectiveness, achieving robust performance across machine learning paradigms including natural language processing, speech recognition, and time-series analysis. However, a comprehensive review of RetNet is still missing from the current literature. This paper aims to fill that gap by offering the first detailed survey of the RetNet architecture, its key innovations, and its diverse applications. We also explore the main challenges associated with RetNet and propose future research directions to support its continued advancement in both academic research and practical deployment.