 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEGState: Phoneme Decoding from Magnetoencephalography Signals
Dec 19, 2025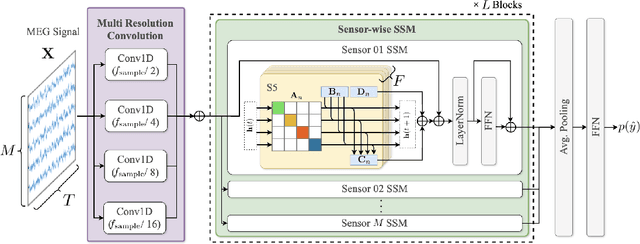
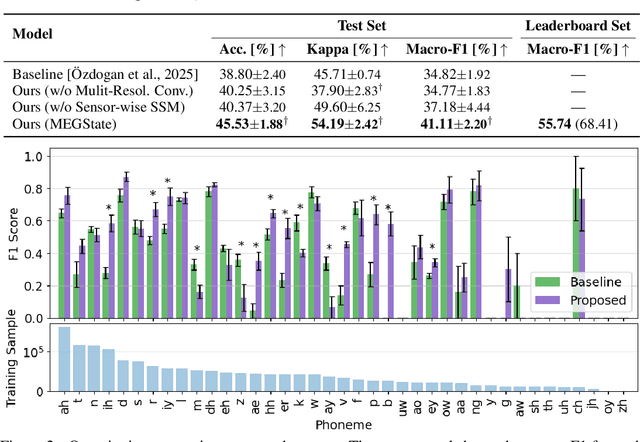
Decoding linguistically meaningful representations from non-invasive neural recordings remains a central challenge in neural speech decoding. Among available neuroimaging modalities, magnetoencephalography (MEG) provides a safe and repeatable means of mapping speech-related cortical dynamics, yet its low signal-to-noise ratio and high temporal dimensionality continue to hinder robust decoding. In this work, we introduce MEGState, a novel architecture for phoneme decoding from MEG signals that captures fine-grained cortical responses evoked by auditory stimuli. Extensive experiments on the LibriBrain dataset demonstrate that MEGState consistently surpasses baseline model across multiple evaluation metrics. These findings highlight the potential of MEG-based phoneme decoding as a scalable pathway toward non-invasive brain-computer interfaces for speech.
Learning-based Radio Link Failure Prediction Based on Measurement Dataset in Railway Environments
Nov 13, 2025In this paper, a measurement-driven framework is proposed for early radio link failure (RLF) prediction in 5G non-standalone (NSA) railway environments. Using 10 Hz metro-train traces with serving and neighbor-cell indicators, we benchmark six models, namely CNN, LSTM, XGBoost, Anomaly Transformer, PatchTST, and TimesNet, under varied observation windows and prediction horizons. When the observation window is three seconds, TimesNet attains the highest F1 score with a three-second prediction horizon, while CNN provides a favorable accuracy-latency tradeoff with a two-second horizon, enabling proactive actions such as redundancy and adaptive handovers. The results indicate that deep temporal models can anticipate reliability degradations several seconds in advance using lightweight features available on commercial devices, offering a practical path to early-warning control in 5G-based railway systems.
NGGAN: Noise Generation GAN Based on the Practical Measurement Dataset for Narrowband Powerline Communications
Oct 02, 2025Capturing comprehensive statistics of nonperiodic asynchronous impulsive noise is a critical issue in enhancing impulse noise processing for narrowband powerline communication (NB-PLC) transceivers. However, existing mathematical noise generative models capture only some of the characteristics of additive noise. Therefore, we propose a generative adversarial network (GAN), called the noise-generation GAN (NGGAN), that learns the complicated characteristics of practically measured noise samples for data augmentation. To closely match the statistics of complicated noise in NB-PLC systems, we measured the NB-PLC noise via the analog coupling and bandpass filtering circuits of a commercial NB-PLC modem to build a realistic dataset. Specifically, the NGGAN design approaches based on the practically measured dataset are as follows: (i) we design the length of input signals that the NGGAN model can fit to facilitate cyclo-stationary noise generation. (ii) Wasserstein distance is used as a loss function to enhance the similarity between the generated noise and the training dataset and ensure that the sample diversity is sufficient for various applications. (iii) To measure the similarity performance of the GAN-based models based on mathematical and practically measured datasets, we perform quantitative and qualitative analyses. The training datasets include (1) a piecewise spectral cyclo-stationary Gaussian model (PSCGM), (2) a frequency-shift (FRESH) filter, and (3) practical measurements from NB-PLC systems. Simulation results demonstrate that the proposed NGGAN trained using waveform characteristics is closer to the practically measured dataset in terms of the quality of the generated noise.
* 16 pages, 15 figures, 11 tables, and published in IEEE Transactions on Instrumentation and Measurement, Vol. 74, 2025
Improving Perceptual Audio Aesthetic Assessment via Triplet Loss and Self-Supervised Embeddings
Sep 03, 2025We present a system for automatic multi-axis perceptual quality prediction of generative audio, developed for Track 2 of the AudioMOS Challenge 2025. The task is to predict four Audio Aesthetic Scores--Production Quality, Production Complexity, Content Enjoyment, and Content Usefulness--for audio generated by text-to-speech (TTS), text-to-audio (TTA), and text-to-music (TTM) systems. A main challenge is the domain shift between natural training data and synthetic evaluation data. To address this, we combine BEATs, a pretrained transformer-based audio representation model, with a multi-branch long short-term memory (LSTM) predictor and use a triplet loss with buffer-based sampling to structure the embedding space by perceptual similarity. Our results show that this improves embedding discriminability and generalization, enabling domain-robust audio quality assessment without synthetic training data.
DNN-Based Precoding in RIS-Aided mmWave MIMO Systems With Practical Phase Shift
Jul 03, 2025In this paper, the precoding design is investigated for maximizing the throughput of millimeter wave (mmWave) multiple-input multiple-output (MIMO) systems with obstructed direct communication paths. In particular, a reconfigurable intelligent surface (RIS) is employed to enhance MIMO transmissions, considering mmWave characteristics related to line-of-sight (LoS) and multipath effects. The traditional exhaustive search (ES) for optimal codewords in the continuous phase shift is computationally intensive and time-consuming. To reduce computational complexity, permuted discrete Fourier transform (DFT) vectors are used for finding codebook design, incorporating amplitude responses for practical or ideal RIS systems. However, even if the discrete phase shift is adopted in the ES, it results in significant computation and is time-consuming. Instead, the trained deep neural network (DNN) is developed to facilitate faster codeword selection. Simulation results show that the DNN maintains sub-optimal spectral efficiency even as the distance between the end-user and the RIS has variations in the testing phase. These results highlight the potential of DNN in advancing RIS-aided systems.
An Investigation on Combining Geometry and Consistency Constraints into Phase Estimation for Speech Enhancement
Jul 02, 2025



We propose a novel iterative phase estimation framework, termed multi-source Griffin-Lim algorithm (MSGLA), for speech enhancement (SE) under additive noise conditions. The core idea is to leverage the ad-hoc consistency constraint of complex-valued short-time Fourier transform (STFT) spectrograms to address the sign ambiguity challenge commonly encountered in geometry-based phase estimation. Furthermore, we introduce a variant of the geometric constraint framework based on the law of sines and cosines, formulating a new phase reconstruction algorithm using noise phase estimates. We first validate the proposed technique through a series of oracle experiments, demonstrating its effectiveness under ideal conditions. We then evaluate its performance on the VB-DMD and WSJ0-CHiME3 data sets, and show that the proposed MSGLA variants match well or slightly outperform existing algorithms, including direct phase estimation and DNN-based sign prediction, especially in terms of background noise suppression.
An Exploration of Mamba for Speech Self-Supervised Models
Jun 14, 2025



While Mamba has demonstrated strong performance in language modeling, its potential as a speech self-supervised (SSL) model remains underexplored, with prior studies limited to isolated tasks. To address this, we explore Mamba-based HuBERT models as alternatives to Transformer-based SSL architectures. Leveraging the linear-time Selective State Space, these models enable fine-tuning on long-context ASR with significantly lower compute. Moreover, they show superior performance when fine-tuned for streaming ASR. Beyond fine-tuning, these models show competitive performance on SUPERB probing benchmarks, particularly in causal settings. Our analysis shows that they yield higher-quality quantized representations and capture speaker-related features more distinctly than Transformer-based models. These findings highlight Mamba-based SSL as a promising and complementary direction for long-sequence modeling, real-time speech modeling, and speech unit extraction.
A Study on Speech Assessment with Visual Cues
Jun 11, 2025Non-intrusive assessment of speech quality and intelligibility is essential when clean reference signals are unavailable. In this work, we propose a multimodal framework that integrates audio features and visual cues to predict PESQ and STOI scores. It employs a dual-branch architecture, where spectral features are extracted using STFT, and visual embeddings are obtained via a visual encoder. These features are then fused and processed by a CNN-BLSTM with attention, followed by multi-task learning to simultaneously predict PESQ and STOI. Evaluations on the LRS3-TED dataset, augmented with noise from the DEMAND corpus, show that our model outperforms the audio-only baseline. Under seen noise conditions, it improves LCC by 9.61% (0.8397->0.9205) for PESQ and 11.47% (0.7403->0.8253) for STOI. These results highlight the effectiveness of incorporating visual cues in enhancing the accuracy of non-intrusive speech assessment.
Towards Robust Assessment of Pathological Voices via Combined Low-Level Descriptors and Foundation Model Representations
May 30, 2025



Perceptual voice quality assessment is essential for diagnosing and monitoring voice disorders by providing standardized evaluations of vocal function. Traditionally, expert raters use standard scales such as the Consensus Auditory-Perceptual Evaluation of Voice (CAPE-V) and Grade, Roughness, Breathiness, Asthenia, and Strain (GRBAS). However, these metrics are subjective and prone to inter-rater variability, motivating the need for automated, objective assessment methods. This study proposes Voice Quality Assessment Network (VOQANet), a deep learning-based framework with an attention mechanism that leverages a Speech Foundation Model (SFM) to extract high-level acoustic and prosodic information from raw speech. To enhance robustness and interpretability, we also introduce VOQANet+, which integrates low-level speech descriptors such as jitter, shimmer, and harmonics-to-noise ratio (HNR) with SFM embeddings into a hybrid representation. Unlike prior studies focused only on vowel-based phonation (PVQD-A subset) of the Perceptual Voice Quality Dataset (PVQD), we evaluate our models on both vowel-based and sentence-level speech (PVQD-S subset) to improve generalizability. Results show that sentence-based input outperforms vowel-based input, especially at the patient level, underscoring the value of longer utterances for capturing perceptual voice attributes. VOQANet consistently surpasses baseline methods in root mean squared error (RMSE) and Pearson correlation coefficient (PCC) across CAPE-V and GRBAS dimensions, with VOQANet+ achieving even better performance. Additional experiments under noisy conditions show that VOQANet+ maintains high prediction accuracy and robustness, supporting its potential for real-world and telehealth deployment.
Towards Robust Automated Perceptual Voice Quality Assessment with Speech Foundation Models
May 28, 2025Perceptual voice quality assessment is essential for diagnosing and monitoring voice disorders. Traditionally, expert raters use scales such as the CAPE-V and GRBAS. However, these are subjective and prone to inter-rater variability, motivating the need for automated, objective assessment methods. This study proposes VOQANet, a deep learning framework with an attention mechanism that leverages a Speech Foundation Model (SFM) to extract high-level acoustic and prosodic information from raw speech. To improve robustness and interpretability, we introduce VOQANet+, which integrates handcrafted acoustic features such as jitter, shimmer, and harmonics-to-noise ratio (HNR) with SFM embeddings into a hybrid representation. Unlike prior work focusing only on vowel-based phonation (PVQD-A subset) from the Perceptual Voice Quality Dataset (PVQD), we evaluate our models on both vowel-based and sentence-level speech (PVQD-S subset) for better generalizability. Results show that sentence-based input outperforms vowel-based input, particularly at the patient level, highlighting the benefit of longer utterances for capturing voice attributes. VOQANet consistently surpasses baseline methods in root mean squared error and Pearson correlation across CAPE-V and GRBAS dimensions, with VOQANet+ achieving further improvements. Additional tests under noisy conditions show that VOQANet+ maintains high prediction accuracy, supporting its use in real-world and telehealth settings. These findings demonstrate the value of combining SFM embeddings with domain-informed acoustic features for interpretable and robust voice quality assessment.