 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Stochastic Processes for Satellite Precipitation Refinement
Apr 12, 2026Accurate precipitation estimation is critical for flood forecasting, water resource management, and disaster preparedness. Satellite products provide global hourly coverage but contain systematic biases; ground-based gauges are accurate at point locations but too sparse for direct gridded correction. Existing methods fuse these sources by interpolating gauge observations onto the satellite grid, but treat each time step independently and therefore discard temporal structure in precipitation fields. We propose Neural Stochastic Process (NSP), a model that pairs a Neural Process encoder conditioning on arbitrary sets of gauge observations with a latent Neural SDE on a 2D spatial representation. NSP is trained under a single variational objective with simulation-free cost. We also introduce QPEBench, a benchmark of 43{,}756 hourly samples over the Contiguous United States (2021--2025) with four aligned data sources and six evaluation metrics. On QPEBench, NSP outperforms 13 baselines across all six metrics and surpasses JAXA's operational gauge-calibrated product. An additional experiment on Kyushu, Japan confirms generalization to a different region with independent data sources.
ABMAMBA: Multimodal Large Language Model with Aligned Hierarchical Bidirectional Scan for Efficient Video Captioning
Apr 09, 2026In this study, we focus on video captioning by fully open multimodal large language models (MLLMs). The comprehension of visual sequences is challenging because of their intricate temporal dependencies and substantial sequence length. The core attention mechanisms of existing Transformer-based approaches scale quadratically with the sequence length, making them computationally prohibitive. To address these limitations, we propose Aligned Hierarchical Bidirectional Scan Mamba (ABMamba), a fully open MLLM with linear computational complexity that enables the scalable processing of video sequences. ABMamba extends Deep State Space Models as its language backbone, replacing the costly quadratic attention mechanisms, and employs a novel Aligned Hierarchical Bidirectional Scan module that processes videos across multiple temporal resolutions. On standard video captioning benchmarks such as VATEX and MSR-VTT, ABMamba demonstrates competitive performance compared to typical MLLMs while achieving approximately three times higher throughput.
A Decomposition-based State Space Model for Multivariate Time-Series Forecasting
Feb 05, 2026Multivariate time series (MTS) forecasting is crucial for decision-making in domains such as weather, energy, and finance. It remains challenging because real-world sequences intertwine slow trends, multi-rate seasonalities, and irregular residuals. Existing methods often rely on rigid, hand-crafted decompositions or generic end-to-end architectures that entangle components and underuse structure shared across variables. To address these limitations, we propose DecompSSM, an end-to-end decomposition framework using three parallel deep state space model branches to capture trend, seasonal, and residual components. The model features adaptive temporal scales via an input-dependent predictor, a refinement module for shared cross-variable context, and an auxiliary loss that enforces reconstruction and orthogonality. Across standard benchmarks (ECL, Weather, ETTm2, and PEMS04), DecompSSM outperformed strong baselines, indicating the effectiveness of combining component-wise deep state space models and global context refinement.
MEGState: Phoneme Decoding from Magnetoencephalography Signals
Dec 19, 2025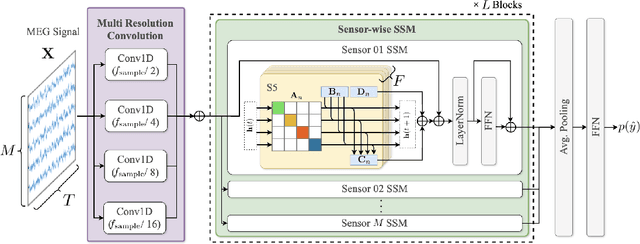
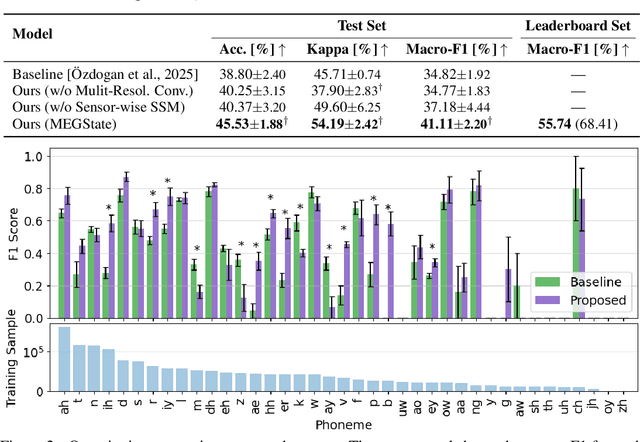
Decoding linguistically meaningful representations from non-invasive neural recordings remains a central challenge in neural speech decoding. Among available neuroimaging modalities, magnetoencephalography (MEG) provides a safe and repeatable means of mapping speech-related cortical dynamics, yet its low signal-to-noise ratio and high temporal dimensionality continue to hinder robust decoding. In this work, we introduce MEGState, a novel architecture for phoneme decoding from MEG signals that captures fine-grained cortical responses evoked by auditory stimuli. Extensive experiments on the LibriBrain dataset demonstrate that MEGState consistently surpasses baseline model across multiple evaluation metrics. These findings highlight the potential of MEG-based phoneme decoding as a scalable pathway toward non-invasive brain-computer interfaces for speech.