 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFewSOL: A Dataset for Few-Shot Object Learning in Robotic Environments
Jul 06, 2022
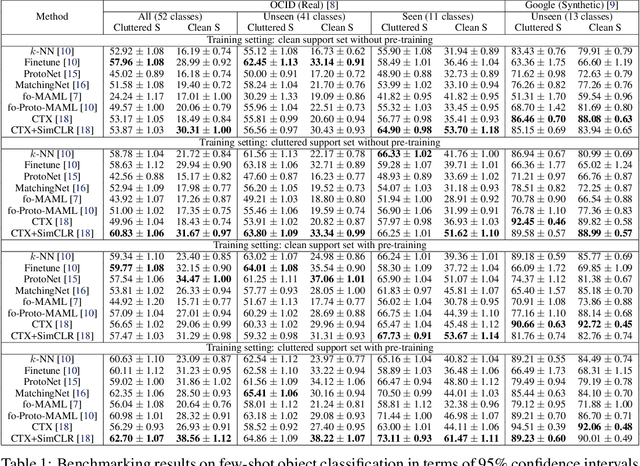

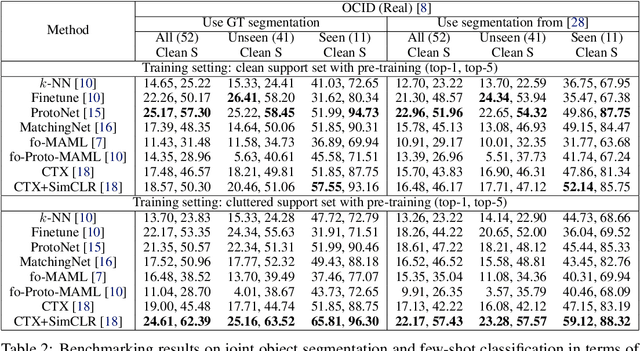
We introduce the Few-Shot Object Learning (FewSOL) dataset for object recognition with a few images per object. We captured 336 real-world objects with 9 RGB-D images per object from different views. Object segmentation masks, object poses and object attributes are provided. In addition, synthetic images generated using 330 3D object models are used to augment the dataset. We investigated (i) few-shot object classification and (ii) joint object segmentation and few-shot classification with the state-of-the-art methods for few-shot learning and meta-learning using our dataset. The evaluation results show that there is still a large margin to be improved for few-shot object classification in robotic environments. Our dataset can be used to study a set of few-shot object recognition problems such as classification, detection and segmentation, shape reconstruction, pose estimation, keypoint correspondences and attribute recognition. The dataset and code are available at https://irvlutd.github.io/FewSOL.
Lower Bounds on the Error Probability for Invariant Causal Prediction
Jun 30, 2022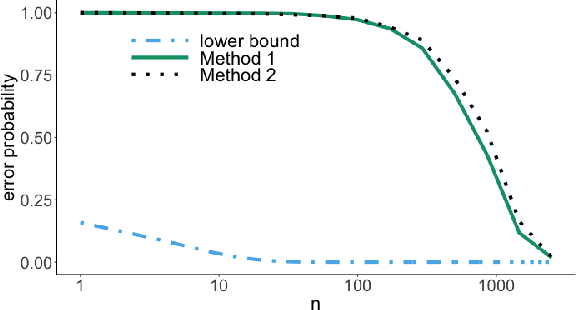
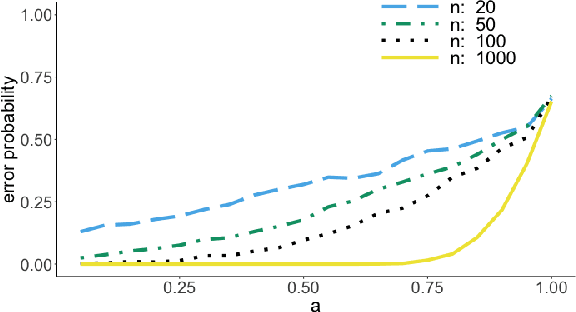
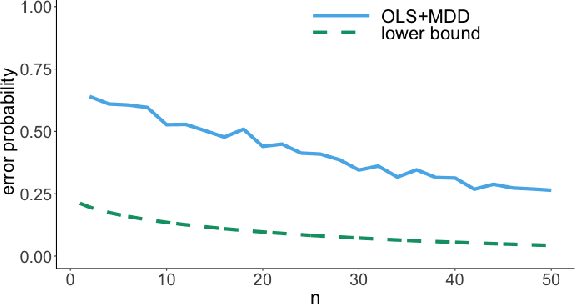
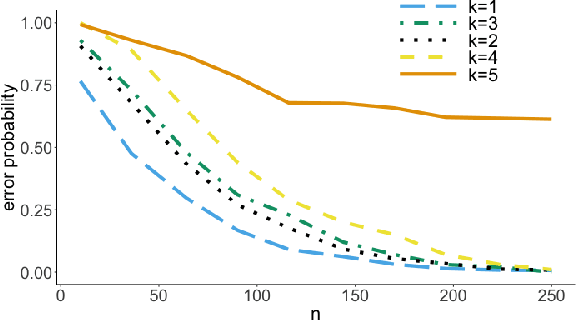
It is common practice to collect observations of feature and response pairs from different environments. A natural question is how to identify features that have consistent prediction power across environments. The invariant causal prediction framework proposes to approach this problem through invariance, assuming a linear model that is invariant under different environments. In this work, we make an attempt to shed light on this framework by connecting it to the Gaussian multiple access channel problem. Specifically, we incorporate optimal code constructions and decoding methods to provide lower bounds on the error probability. We illustrate our findings by various simulation settings.
A Manifold-based Airfoil Geometric-feature Extraction and Discrepant Data Fusion Learning Method
Jun 23, 2022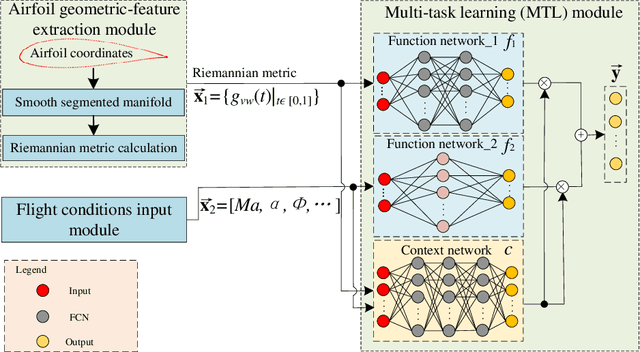
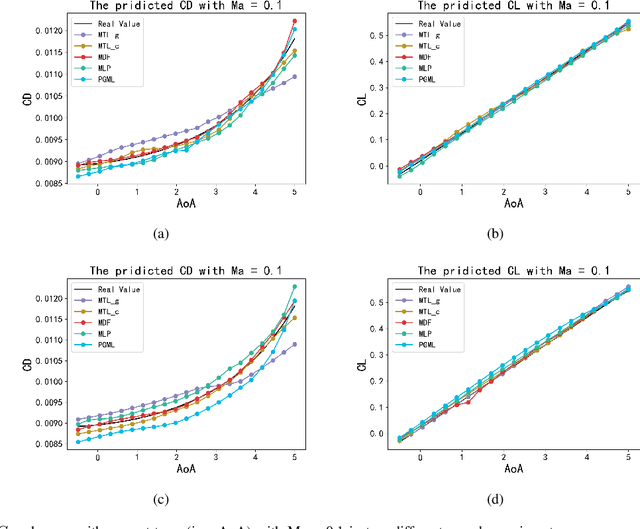
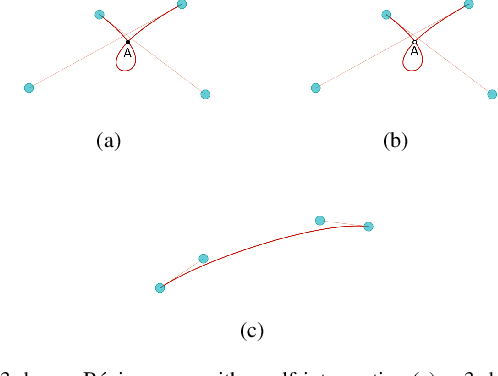
Geometrical shape of airfoils, together with the corresponding flight conditions, are crucial factors for aerodynamic performances prediction. The obtained airfoils geometrical features in most existing approaches (e.g., geometrical parameters extraction, polynomial description and deep learning) are in Euclidean space. State-of-the-art studies showed that curves or surfaces of an airfoil formed a manifold in Riemannian space. Therefore, the features extracted by existing methods are not sufficient to reflect the geometric-features of airfoils. Meanwhile, flight conditions and geometric features are greatly discrepant with different types, the relevant knowledge of the influence of these two factors that on final aerodynamic performances predictions must be evaluated and learned to improve prediction accuracy. Motivated by the advantages of manifold theory and multi-task learning, we propose a manifold-based airfoil geometric-feature extraction and discrepant data fusion learning method (MDF) to extract geometric-features of airfoils in Riemannian space (we call them manifold-features) and further fuse the manifold-features with flight conditions to predict aerodynamic performances. Experimental results show that our method could extract geometric-features of airfoils more accurately compared with existing methods, that the average MSE of re-built airfoils is reduced by 56.33%, and while keeping the same predicted accuracy level of CL, the MSE of CD predicted by MDF is further reduced by 35.37%.
HandoverSim: A Simulation Framework and Benchmark for Human-to-Robot Object Handovers
May 19, 2022

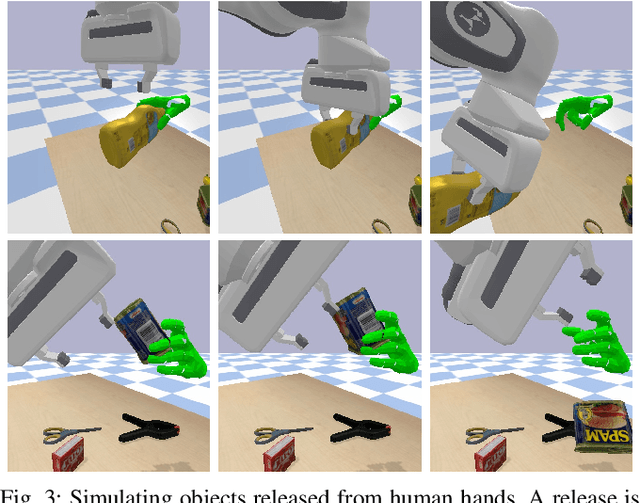

We introduce a new simulation benchmark "HandoverSim" for human-to-robot object handovers. To simulate the giver's motion, we leverage a recent motion capture dataset of hand grasping of objects. We create training and evaluation environments for the receiver with standardized protocols and metrics. We analyze the performance of a set of baselines and show a correlation with a real-world evaluation. Code is open sourced at https://handover-sim.github.io.
An Invariant Matching Property for Distribution Generalization under Intervened Response
May 18, 2022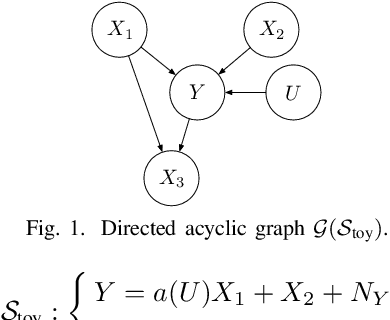
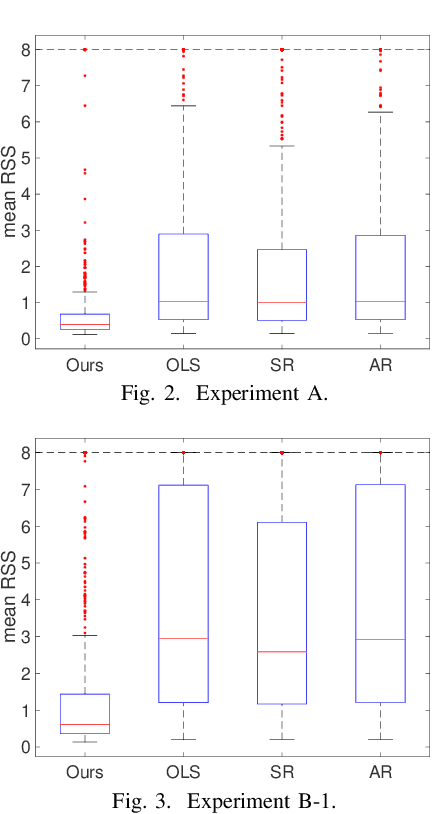
The task of distribution generalization concerns making reliable prediction of a response in unseen environments. The structural causal models are shown to be useful to model distribution changes through intervention. Motivated by the fundamental invariance principle, it is often assumed that the conditional distribution of the response given its predictors remains the same across environments. However, this assumption might be violated in practical settings when the response is intervened. In this work, we investigate a class of model with an intervened response. We identify a novel form of invariance by incorporating the estimates of certain features as additional predictors. Effectively, we show this invariance is equivalent to having a deterministic linear matching that makes the generalization possible. We provide an explicit characterization of the linear matching and present our simulation results under various intervention settings.
Variable Selection with the Knockoffs: Composite Null Hypotheses
Mar 28, 2022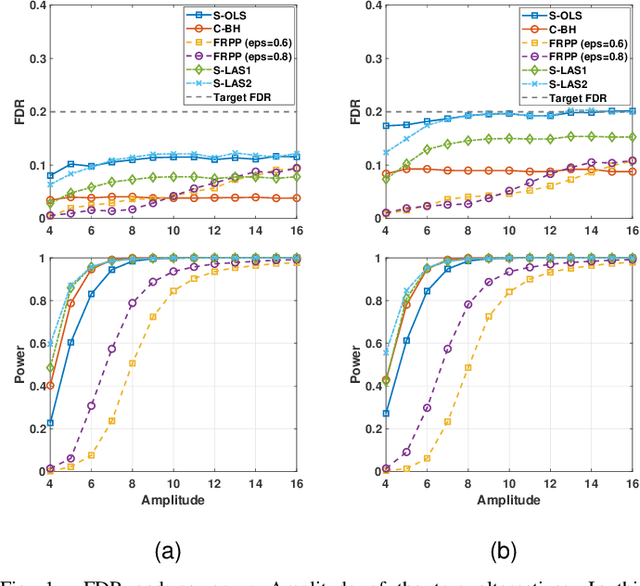
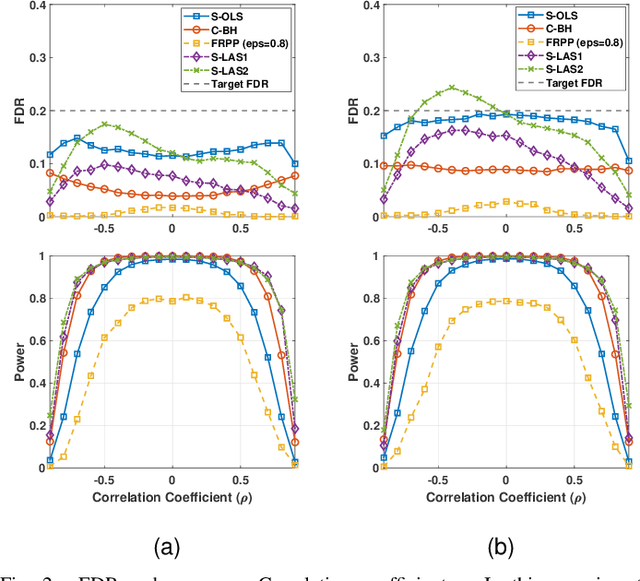
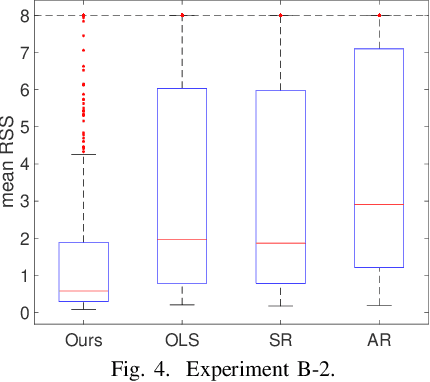
The Fixed-X knockoff filter is a flexible framework for variable selection with false discovery rate (FDR) control in linear models with arbitrary (non-singular) design matrices and it allows for finite-sample selective inference via the LASSO estimates. In this paper, we extend the theory of the knockoff procedure to tests with composite null hypotheses, which are usually more relevant to real-world problems. The main technical challenge lies in handling composite nulls in tandem with dependent features from arbitrary designs. We develop two methods for composite inference with the knockoffs, namely, shifted ordinary least-squares (S-OLS) and feature-response product perturbation (FRPP), building on new structural properties of test statistics under composite nulls. We also propose two heuristic variants of the S-OLS method that outperform the celebrated Benjamini-Hochberg (BH) procedure for composite nulls, which serves as a heuristic baseline under dependent test statistics. Finally, we analyze the loss in FDR when the original knockoff procedure is naively applied on composite tests.
A Multi-Characteristic Learning Method with Micro-Doppler Signatures for Pedestrian Identification
Mar 23, 2022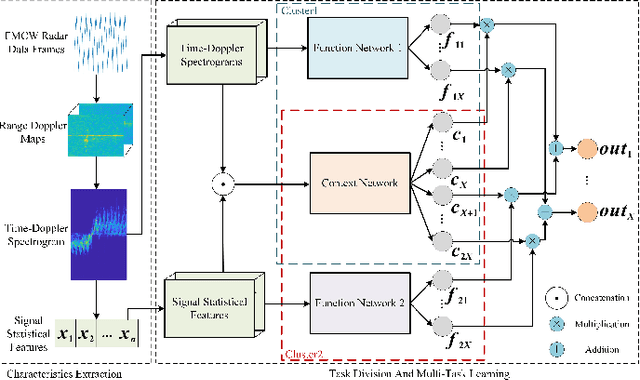
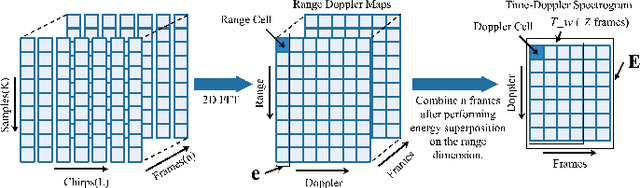
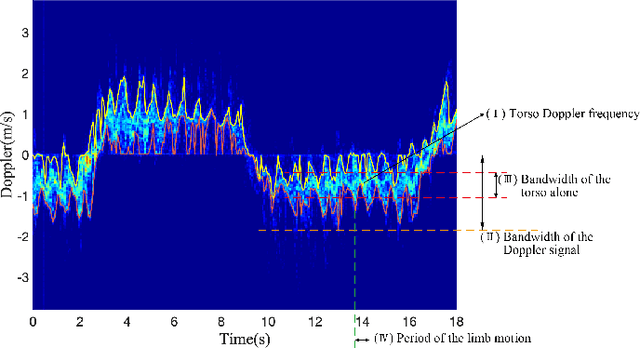
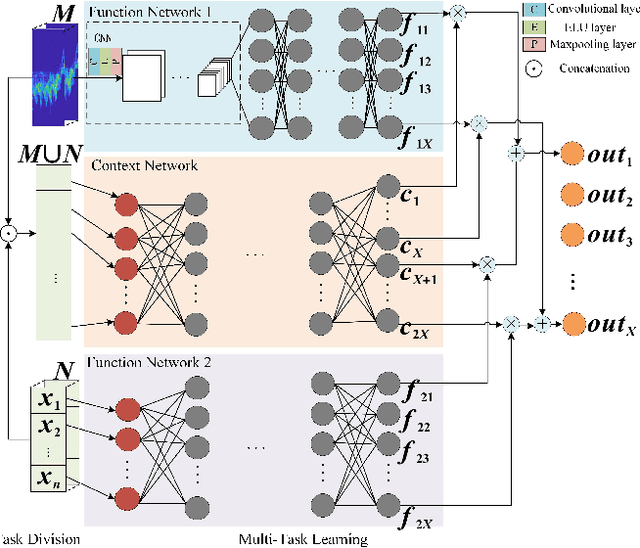
The identification of pedestrians using radar micro-Doppler signatures has become a hot topic in recent years. In this paper, we propose a multi-characteristic learning (MCL) model with clusters to jointly learn discrepant pedestrian micro-Doppler signatures and fuse the knowledge learned from each cluster into final decisions. Time-Doppler spectrogram (TDS) and signal statistical features extracted from FMCW radar, as two categories of micro-Doppler signatures, are used in MCL to learn the micro-motion information inside pedestrians' free walking patterns. The experimental results show that our model achieves a higher accuracy rate and is more stable for pedestrian identification than other studies, which make our model more practical.
Communication-Efficient Distributed Multiple Testing for Large-Scale Inference
Feb 11, 2022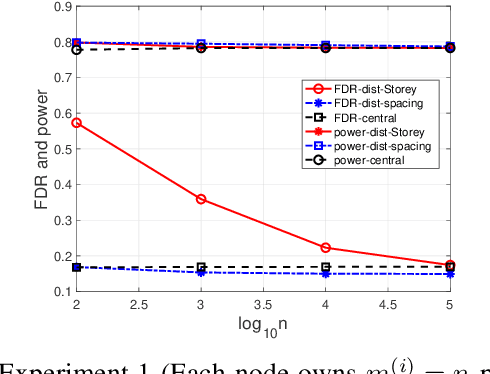
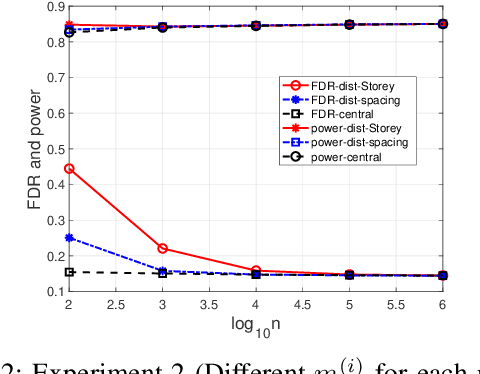
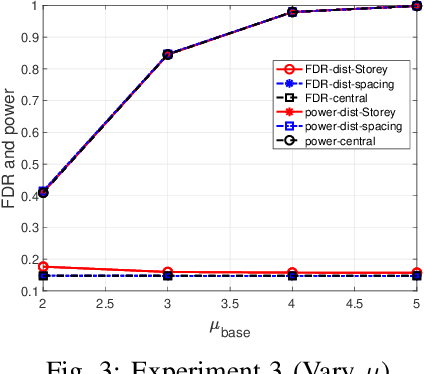
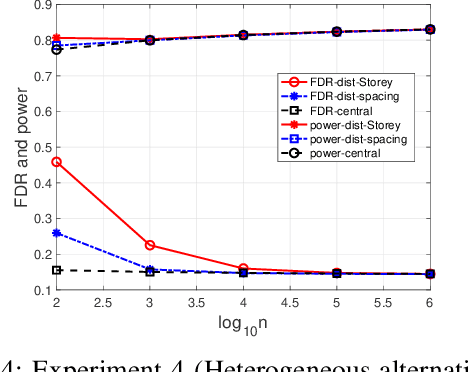
The Benjamini-Hochberg (BH) procedure is a celebrated method for multiple testing with false discovery rate (FDR) control. In this paper, we consider large-scale distributed networks where each node possesses a large number of p-values and the goal is to achieve the global BH performance in a communication-efficient manner. We propose that every node performs a local test with an adjusted test size according to the (estimated) global proportion of true null hypotheses. With suitable assumptions, our method is asymptotically equivalent to the global BH procedure. Motivated by this, we develop an algorithm for star networks where each node only needs to transmit an estimate of the (local) proportion of nulls and the (local) number of p-values to the center node; the center node then broadcasts a parameter (computed based on the global estimate and test size) to the local nodes. In the experiment section, we utilize existing estimators of the proportion of true nulls and consider various settings to evaluate the performance and robustness of our method.
iCaps: Iterative Category-level Object Pose and Shape Estimation
Dec 31, 2021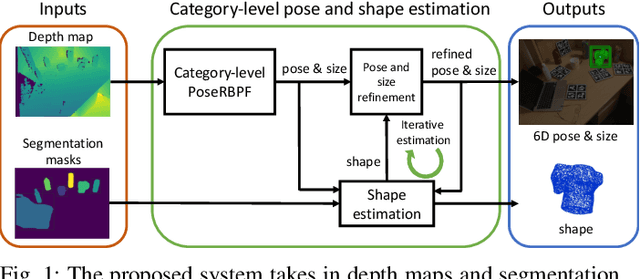
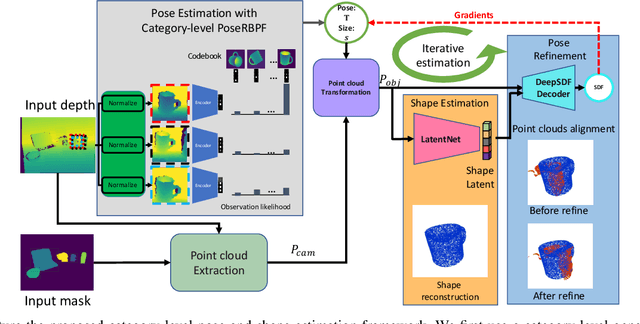
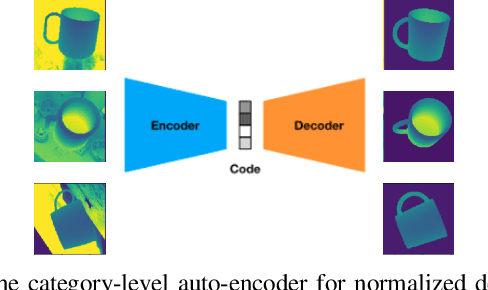
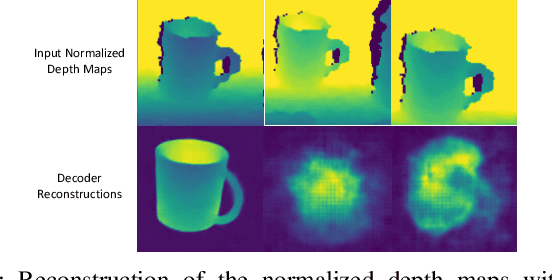
This paper proposes a category-level 6D object pose and shape estimation approach iCaps, which allows tracking 6D poses of unseen objects in a category and estimating their 3D shapes. We develop a category-level auto-encoder network using depth images as input, where feature embeddings from the auto-encoder encode poses of objects in a category. The auto-encoder can be used in a particle filter framework to estimate and track 6D poses of objects in a category. By exploiting an implicit shape representation based on signed distance functions, we build a LatentNet to estimate a latent representation of the 3D shape given the estimated pose of an object. Then the estimated pose and shape can be used to update each other in an iterative way. Our category-level 6D object pose and shape estimation pipeline only requires 2D detection and segmentation for initialization. We evaluate our approach on a publicly available dataset and demonstrate its effectiveness. In particular, our method achieves comparably high accuracy on shape estimation.
TALISMAN: Targeted Active Learning for Object Detection with Rare Classes and Slices using Submodular Mutual Information
Nov 30, 2021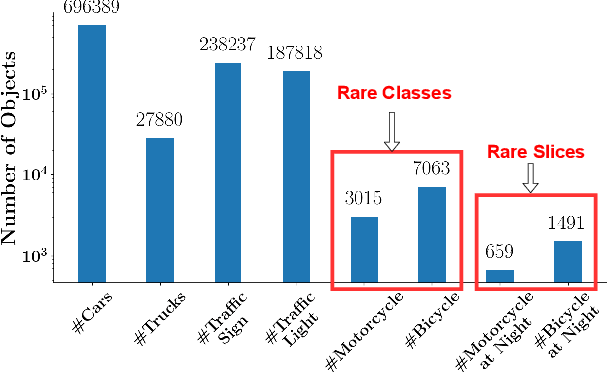
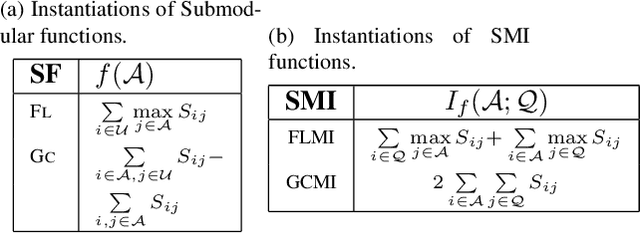
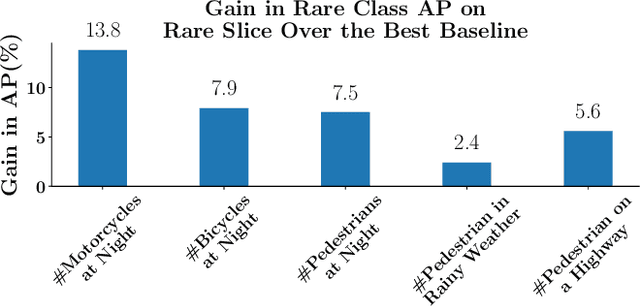
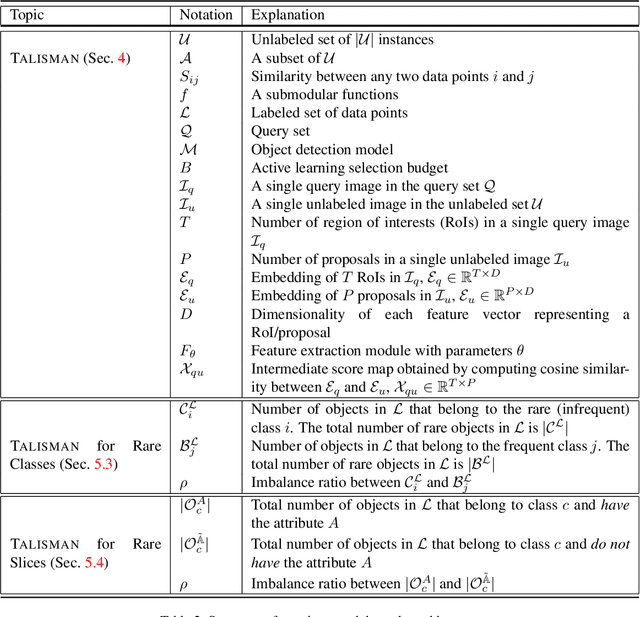
Deep neural networks based object detectors have shown great success in a variety of domains like autonomous vehicles, biomedical imaging, etc. It is known that their success depends on a large amount of data from the domain of interest. While deep models often perform well in terms of overall accuracy, they often struggle in performance on rare yet critical data slices. For example, data slices like "motorcycle at night" or "bicycle at night" are often rare but very critical slices for self-driving applications and false negatives on such rare slices could result in ill-fated failures and accidents. Active learning (AL) is a well-known paradigm to incrementally and adaptively build training datasets with a human in the loop. However, current AL based acquisition functions are not well-equipped to tackle real-world datasets with rare slices, since they are based on uncertainty scores or global descriptors of the image. We propose TALISMAN, a novel framework for Targeted Active Learning or object detectIon with rare slices using Submodular MutuAl iNformation. Our method uses the submodular mutual information functions instantiated using features of the region of interest (RoI) to efficiently target and acquire data points with rare slices. We evaluate our framework on the standard PASCAL VOC07+12 and BDD100K, a real-world self-driving dataset. We observe that TALISMAN outperforms other methods by in terms of average precision on rare slices, and in terms of mAP.