 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPECS: Specificity-Enhanced CLIP-Score for Long Image Caption Evaluation
Sep 04, 2025As interest grows in generating long, detailed image captions, standard evaluation metrics become increasingly unreliable. N-gram-based metrics though efficient, fail to capture semantic correctness. Representational Similarity (RS) metrics, designed to address this, initially saw limited use due to high computational costs, while today, despite advances in hardware, they remain unpopular due to low correlation to human judgments. Meanwhile, metrics based on large language models (LLMs) show strong correlation with human judgments, but remain too expensive for iterative use during model development. We introduce SPECS (Specificity-Enhanced CLIPScore), a reference-free RS metric tailored to long image captioning. SPECS modifies CLIP with a new objective that emphasizes specificity: rewarding correct details and penalizing incorrect ones. We show that SPECS matches the performance of open-source LLM-based metrics in correlation to human judgments, while being far more efficient. This makes it a practical alternative for iterative checkpoint evaluation during image captioning model development.Our code can be found at https://github.com/mbzuai-nlp/SPECS.
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025
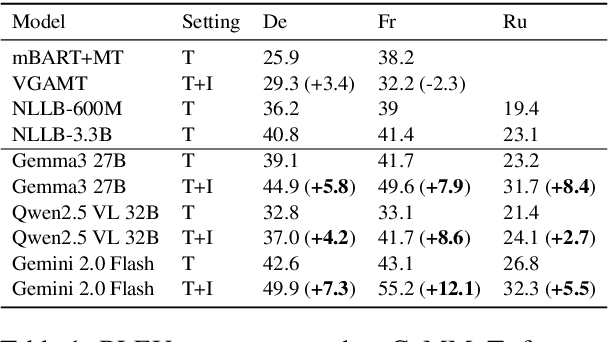

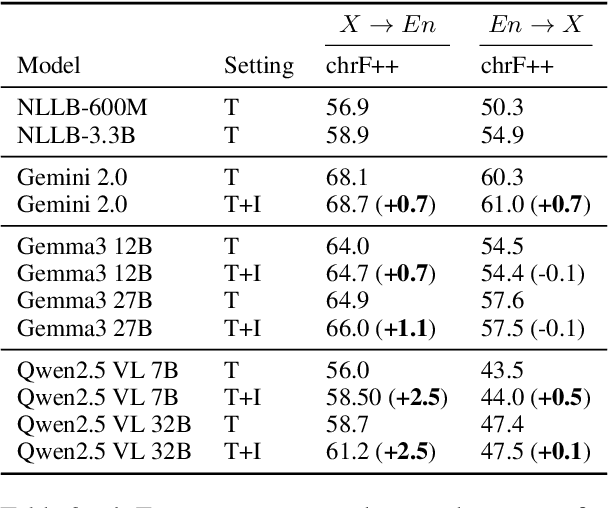
Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
Kaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation
Apr 09, 2025The evaluation of vision-language models (VLMs) has mainly relied on English-language benchmarks, leaving significant gaps in both multilingual and multicultural coverage. While multilingual benchmarks have expanded, both in size and languages, many rely on translations of English datasets, failing to capture cultural nuances. In this work, we propose Kaleidoscope, as the most comprehensive exam benchmark to date for the multilingual evaluation of vision-language models. Kaleidoscope is a large-scale, in-language multimodal benchmark designed to evaluate VLMs across diverse languages and visual inputs. Kaleidoscope covers 18 languages and 14 different subjects, amounting to a total of 20,911 multiple-choice questions. Built through an open science collaboration with a diverse group of researchers worldwide, Kaleidoscope ensures linguistic and cultural authenticity. We evaluate top-performing multilingual vision-language models and find that they perform poorly on low-resource languages and in complex multimodal scenarios. Our results highlight the need for progress on culturally inclusive multimodal evaluation frameworks.