 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Learning Machines: Optimisation, Rules, and Social Norms
Dec 29, 2019
There is an analogy between machine learning systems and economic entities in that they are both adaptive, and their behaviour is specified in a more-or-less explicit way. It appears that the area of AI that is most analogous to the behaviour of economic entities is that of morally good decision-making, but it is an open question as to how precisely moral behaviour can be achieved in an AI system. This paper explores the analogy between these two complex systems, and we suggest that a clearer understanding of this apparent analogy may help us forward in both the socio-economic domain and the AI domain: known results in economics may help inform feasible solutions in AI safety, but also known results in AI may inform economic policy. If this claim is correct, then the recent successes of deep learning for AI suggest that more implicit specifications work better than explicit ones for solving such problems.
On the Morality of Artificial Intelligence
Dec 26, 2019Much of the existing research on the social and ethical impact of Artificial Intelligence has been focused on defining ethical principles and guidelines surrounding Machine Learning (ML) and other Artificial Intelligence (AI) algorithms [IEEE, 2017, Jobin et al., 2019]. While this is extremely useful for helping define the appropriate social norms of AI, we believe that it is equally important to discuss both the potential and risks of ML and to inspire the community to use ML for beneficial objectives. In the present article, which is specifically aimed at ML practitioners, we thus focus more on the latter, carrying out an overview of existing high-level ethical frameworks and guidelines, but above all proposing both conceptual and practical principles and guidelines for ML research and deployment, insisting on concrete actions that can be taken by practitioners to pursue a more ethical and moral practice of ML aimed at using AI for social good.
A learning-based algorithm to quickly compute good primal solutions for Stochastic Integer Programs
Dec 17, 2019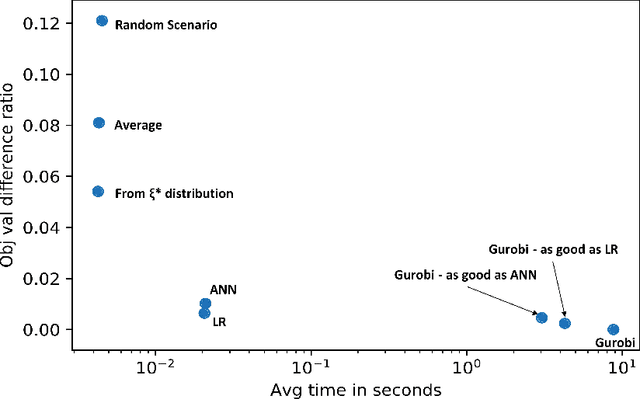
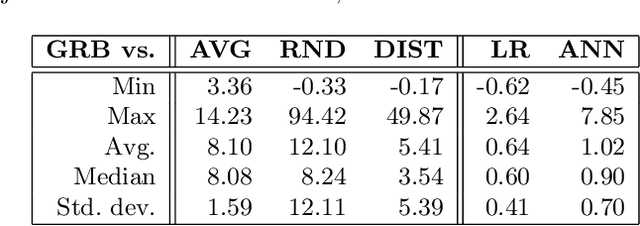

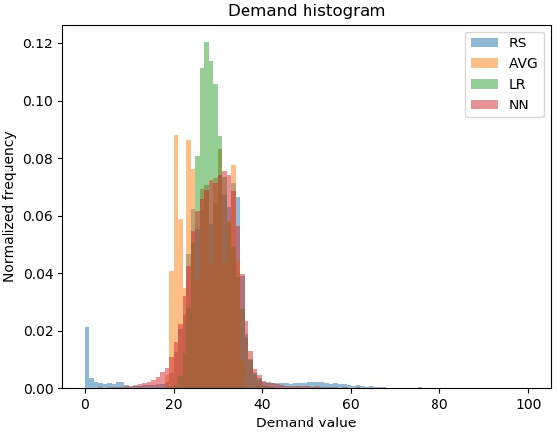
We propose a novel approach using supervised learning to obtain near-optimal primal solutions for two-stage stochastic integer programming (2SIP) problems with constraints in the first and second stages. The goal of the algorithm is to predict a "representative scenario" (RS) for the problem such that, deterministically solving the 2SIP with the random realization equal to the RS, gives a near-optimal solution to the original 2SIP. Predicting an RS, instead of directly predicting a solution ensures first-stage feasibility of the solution. If the problem is known to have complete recourse, second-stage feasibility is also guaranteed. For computational testing, we learn to find an RS for a two-stage stochastic facility location problem with integer variables and linear constraints in both stages and consistently provide near-optimal solutions. Our computing times are very competitive with those of general-purpose integer programming solvers to achieve a similar solution quality.
Joint Learning of Generative Translator and Classifier for Visually Similar Classes
Dec 15, 2019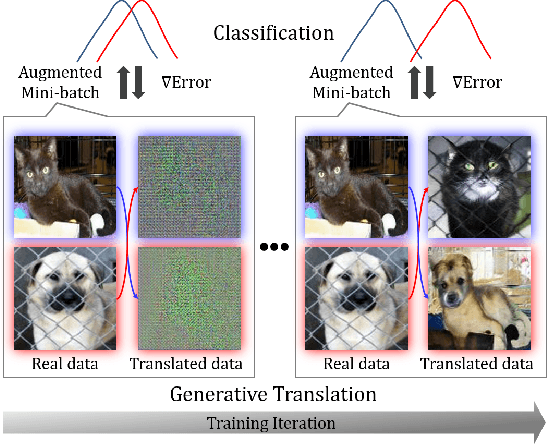
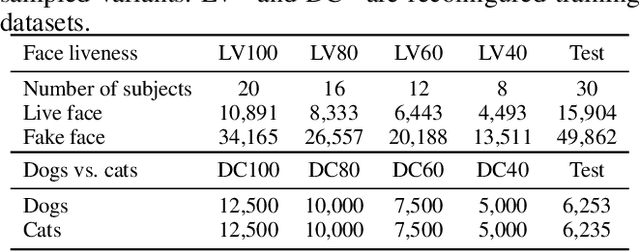
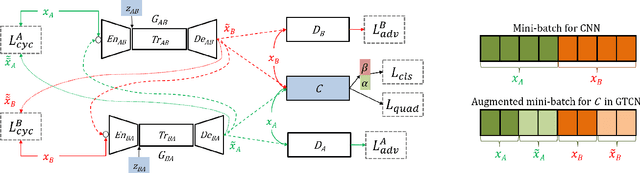
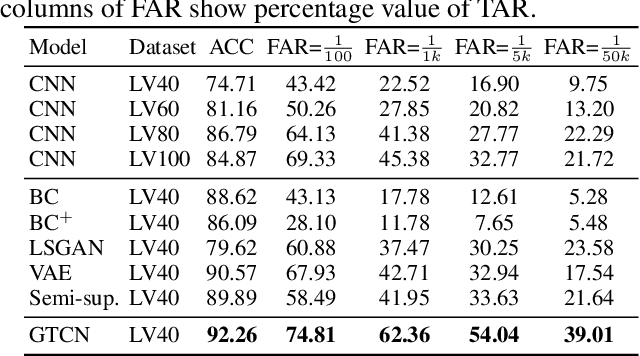
In this paper, we propose a Generative Translation Classification Network (GTCN) for improving visual classification accuracy in settings where classes are visually similar and data is scarce. For this purpose, we propose joint learning to train a classifier and a generative stochastic translation network end-to-end. The translation network is used to perform on-line data augmentation across classes, whereas previous works have mostly involved domain adaptation. To help the model further benefit from this data-augmentation, we introduce an adaptive fade-in loss and a quadruplet loss. We perform experiments on multiple datasets to demonstrate the proposed method's performance in varied settings. Of particular interest, training on 40% of the dataset is enough for our model to surpass the performance of baselines trained on the full dataset. When our architecture is trained on the full dataset, we achieve comparable performance with state-of-the-art methods despite using a light-weight architecture.
CLOSURE: Assessing Systematic Generalization of CLEVR Models
Dec 12, 2019
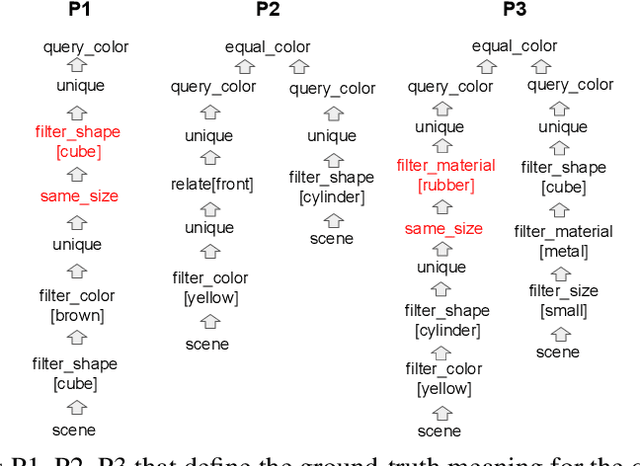
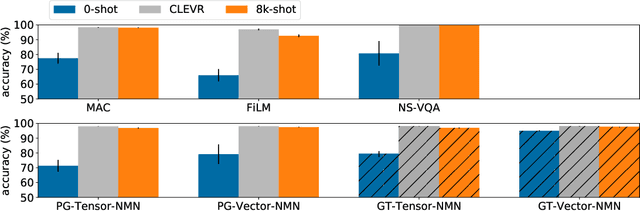
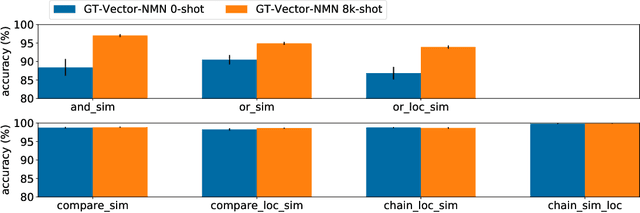
The CLEVR dataset of natural-looking questions about 3D-rendered scenes has recently received much attention from the research community. A number of models have been proposed for this task, many of which achieved very high accuracies of around 97-99%. In this work, we study how systematic the generalization of such models is, that is to which extent they are capable of handling novel combinations of known linguistic constructs. To this end, we test models' understanding of referring expressions based on matching object properties (such as e.g. "the object that is the same size as the red ball") in novel contexts. Our experiments on the thereby constructed CLOSURE benchmark show that state-of-the-art models often do not exhibit systematicity after being trained on CLEVR. Surprisingly, we find that an explicitly compositional Neural Module Network model also generalizes badly on CLOSURE, even when it has access to the ground-truth programs at test time. We improve the NMN's systematic generalization by developing a novel Vector-NMN module architecture with vector-valued inputs and outputs. Lastly, we investigate the extent to which few-shot transfer learning can help models that are pretrained on CLEVR to adapt to CLOSURE. Our few-shot learning experiments contrast the adaptation behavior of the models with intermediate discrete programs with that of the end-to-end continuous models.
The effect of task and training on intermediate representations in convolutional neural networks revealed with modified RV similarity analysis
Dec 04, 2019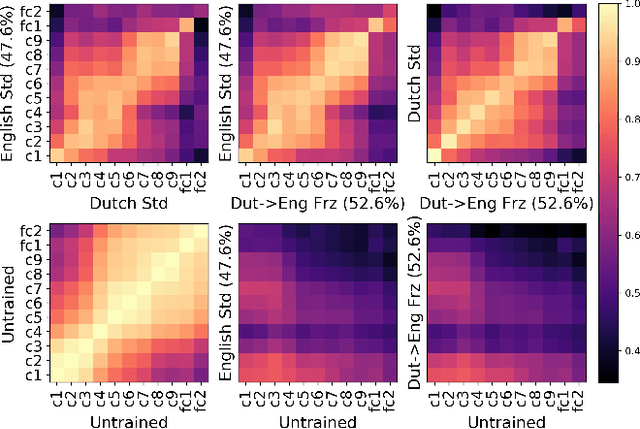
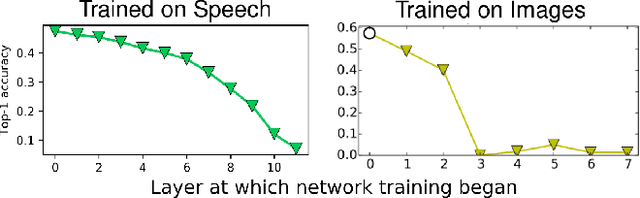
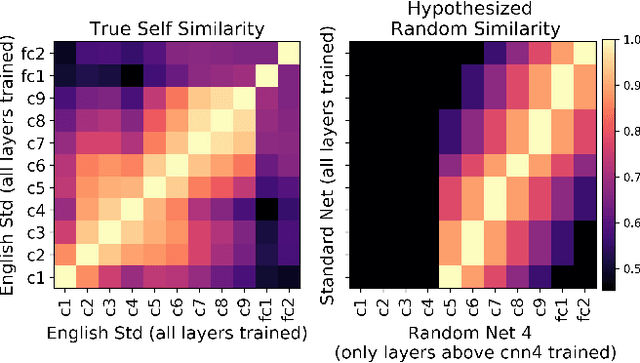
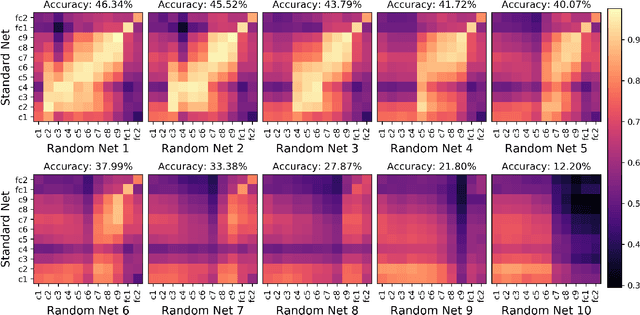
Centered Kernel Alignment (CKA) was recently proposed as a similarity metric for comparing activation patterns in deep networks. Here we experiment with the modified RV-coefficient (RV2), which has very similar properties as CKA while being less sensitive to dataset size. We compare the representations of networks that received varying amounts of training on different layers: a standard trained network (all parameters updated at every step), a freeze trained network (layers gradually frozen during training), random networks (only some layers trained), and a completely untrained network. We found that RV2 was able to recover expected similarity patterns and provide interpretable similarity matrices that suggested hypotheses about how representations are affected by different training recipes. We propose that the superior performance achieved by freeze training can be attributed to representational differences in the penultimate layer. Our comparisons of random networks suggest that the inputs and targets serve as anchors on the representations in the lowest and highest layers.
Applying Knowledge Transfer for Water Body Segmentation in Peru
Dec 02, 2019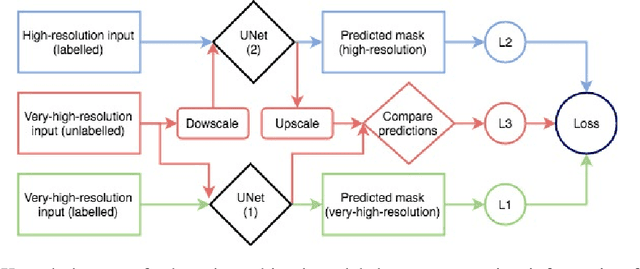
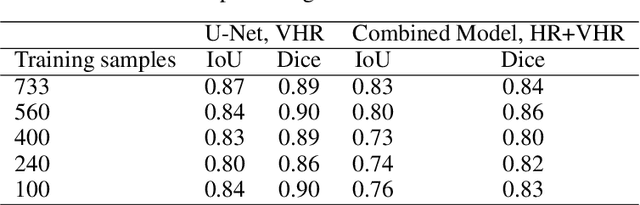
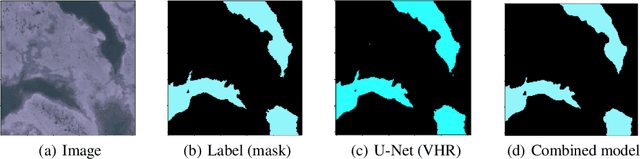
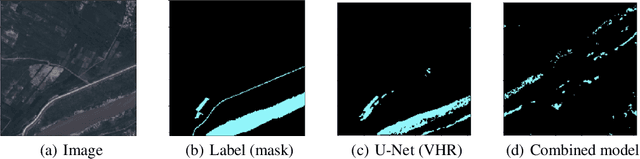
In this work, we present the application of convolutional neural networks for segmenting water bodies in satellite images. We first use a variant of the U-Net model to segment rivers and lakes from very high-resolution images from Peru. To circumvent the issue of scarce labelled data, we investigate the applicability of a knowledge transfer-based model that learns the mapping from high-resolution labelled images and combines it with the very high-resolution mapping so that better segmentation can be achieved. We train this model in a single process, end-to-end. Our preliminary results show that adding the information from the available high-resolution images does not help out-of-the-box, and in fact worsen results. This leads us to infer that the high-resolution data could be from a different distribution, and its addition leads to increased variance in our results.
Automated curriculum generation for Policy Gradients from Demonstrations
Dec 01, 2019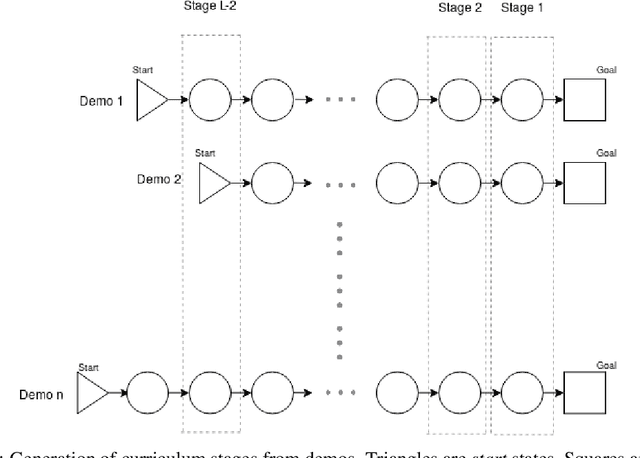

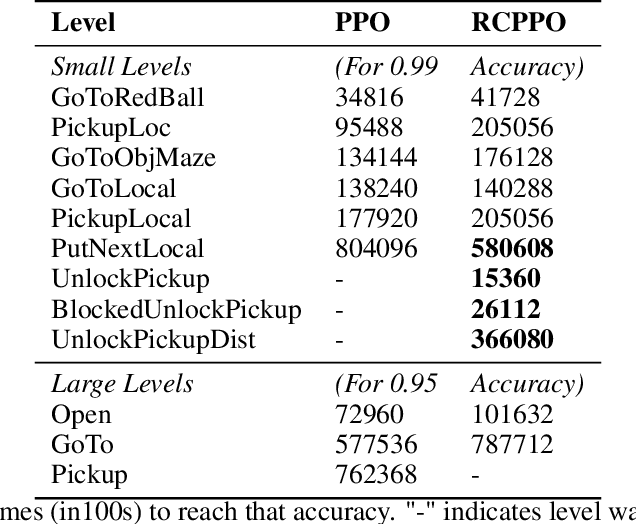
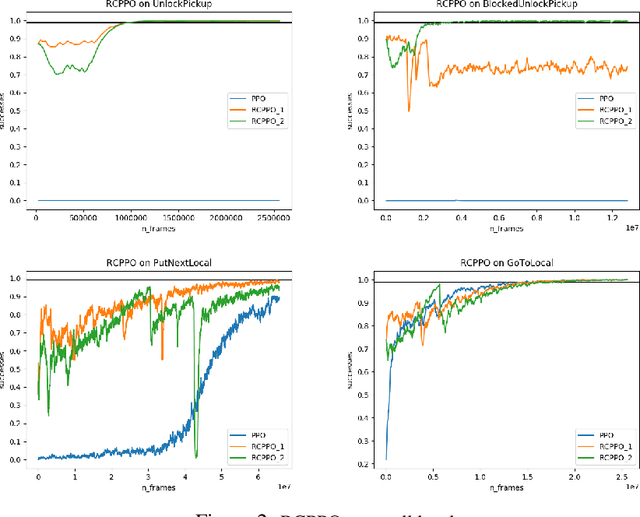
In this paper, we present a technique that improves the process of training an agent (using RL) for instruction following. We develop a training curriculum that uses a nominal number of expert demonstrations and trains the agent in a manner that draws parallels from one of the ways in which humans learn to perform complex tasks, i.e by starting from the goal and working backwards. We test our method on the BabyAI platform and show an improvement in sample efficiency for some of its tasks compared to a PPO (proximal policy optimization) baseline.
Deep Verifier Networks: Verification of Deep Discriminative Models with Deep Generative Models
Nov 18, 2019
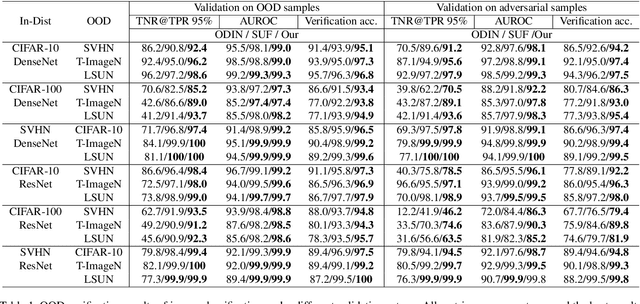
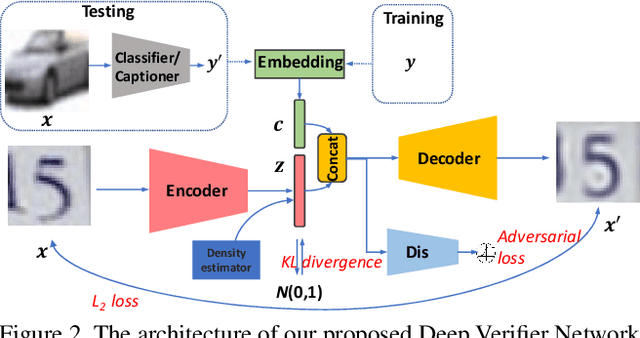

AI Safety is a major concern in many deep learning applications such as autonomous driving. Given a trained deep learning model, an important natural problem is how to reliably verify the model's prediction. In this paper, we propose a novel framework --- deep verifier networks (DVN) to verify the inputs and outputs of deep discriminative models with deep generative models. Our proposed model is based on conditional variational auto-encoders with disentanglement constraints. We give both intuitive and theoretical justifications of the model. Our verifier network is trained independently with the prediction model, which eliminates the need of retraining the verifier network for a new model. We test the verifier network on out-of-distribution detection and adversarial example detection problems, as well as anomaly detection problems in structured prediction tasks such as image caption generation. We achieve state-of-the-art results in all of these problems.
Ghost Units Yield Biologically Plausible Backprop in Deep Neural Networks
Nov 15, 2019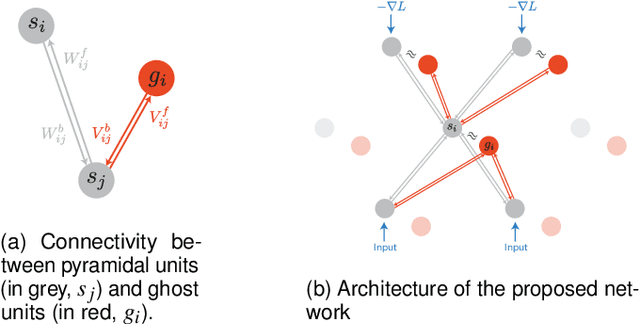
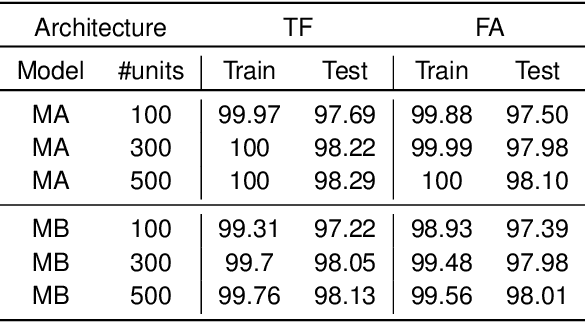
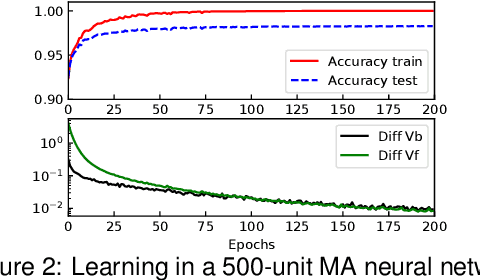
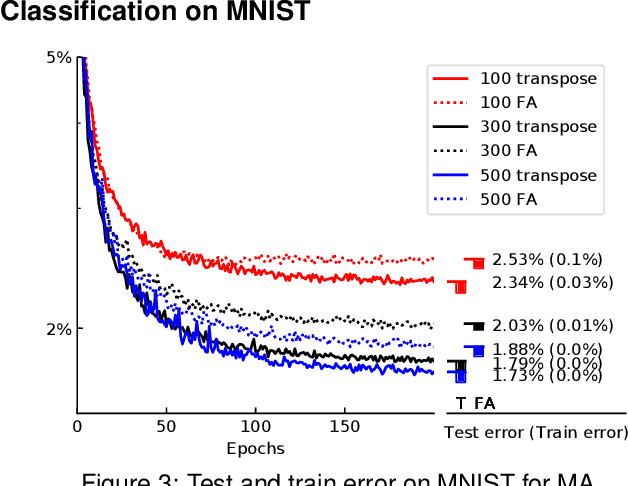
In the past few years, deep learning has transformed artificial intelligence research and led to impressive performance in various difficult tasks. However, it is still unclear how the brain can perform credit assignment across many areas as efficiently as backpropagation does in deep neural networks. In this paper, we introduce a model that relies on a new role for a neuronal inhibitory machinery, referred to as ghost units. By cancelling the feedback coming from the upper layer when no target signal is provided to the top layer, the ghost units enables the network to backpropagate errors and do efficient credit assignment in deep structures. While considering one-compartment neurons and requiring very few biological assumptions, it is able to approximate the error gradient and achieve good performance on classification tasks. Error backpropagation occurs through the recurrent dynamics of the network and thanks to biologically plausible local learning rules. In particular, it does not require separate feedforward and feedback circuits. Different mechanisms for cancelling the feedback were studied, ranging from complete duplication of the connectivity by long term processes to online replication of the feedback activity. This reduced system combines the essential elements to have a working biologically abstracted analogue of backpropagation with a simple formulation and proofs of the associated results. Therefore, this model is a step towards understanding how learning and memory are implemented in cortical multilayer structures, but it also raises interesting perspectives for neuromorphic hardware.